溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
聲音的本質是震動,震動的本質是位移關于時間的函數,波形文件(.wav)中記錄了不同采樣時刻的位移。
通過傅里葉變換,可以將時間域的聲音函數分解為一系列不同頻率的正弦函數的疊加,通過頻率譜線的特殊分布,建立音頻內容和文本的對應關系,以此作為模型訓練的基礎。
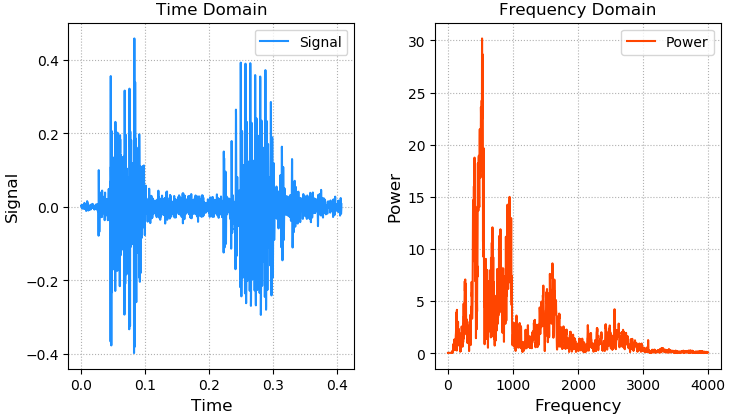
案例:畫出語音信號的波形和頻率分布,(freq.wav數據地址)
# -*- encoding:utf-8 -*-
import numpy as np
import numpy.fft as nf
import scipy.io.wavfile as wf
import matplotlib.pyplot as plt
sample_rate, sigs = wf.read('../machine_learning_date/freq.wav')
print(sample_rate) # 8000采樣率
print(sigs.shape) # (3251,)
sigs = sigs / (2 ** 15) # 歸一化
times = np.arange(len(sigs)) / sample_rate
freqs = nf.fftfreq(sigs.size, 1 / sample_rate)
ffts = nf.fft(sigs)
pows = np.abs(ffts)
plt.figure('Audio')
plt.subplot(121)
plt.title('Time Domain')
plt.xlabel('Time', fontsize=12)
plt.ylabel('Signal', fontsize=12)
plt.tick_params(labelsize=10)
plt.grid(linestyle=':')
plt.plot(times, sigs, c='dodgerblue', label='Signal')
plt.legend()
plt.subplot(122)
plt.title('Frequency Domain')
plt.xlabel('Frequency', fontsize=12)
plt.ylabel('Power', fontsize=12)
plt.tick_params(labelsize=10)
plt.grid(linestyle=':')
plt.plot(freqs[freqs >= 0], pows[freqs >= 0], c='orangered', label='Power')
plt.legend()
plt.tight_layout()
plt.show()
語音識別
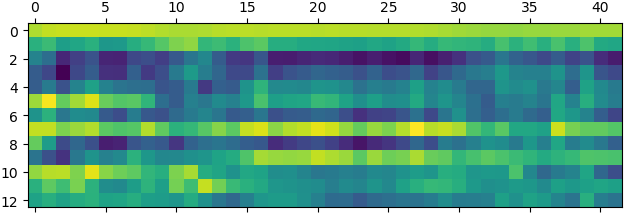
梅爾頻率倒譜系數(MFCC)通過與聲音內容密切相關的13個特殊頻率所對應的能量分布,可以使用梅爾頻率倒譜系數矩陣作為語音識別的特征。基于隱馬爾科夫模型進行模式識別,找到測試樣本最匹配的聲音模型,從而識別語音內容。
MFCC
梅爾頻率倒譜系數相關API:
import scipy.io.wavfile as wf
import python_speech_features as sf
sample_rate, sigs = wf.read('../data/freq.wav')
mfcc = sf.mfcc(sigs, sample_rate)
案例:畫出MFCC矩陣:
python -m pip install python_speech_features import scipy.io.wavfile as wf import python_speech_features as sf import matplotlib.pyplot as mp sample_rate, sigs = wf.read( '../ml_data/speeches/training/banana/banana01.wav') mfcc = sf.mfcc(sigs, sample_rate) mp.matshow(mfcc.T, cmap='gist_rainbow') mp.show()
隱馬爾科夫模型
隱馬爾科夫模型相關API:
import hmmlearn.hmm as hl model = hl.GaussianHMM(n_components=4, covariance_type='diag', n_iter=1000) # n_components: 用幾個高斯分布函數擬合樣本數據 # covariance_type: 相關矩陣的輔對角線進行相關性比較 # n_iter: 最大迭代上限 model.fit(mfccs) # 使用模型匹配測試mfcc矩陣的分值 score = model.score(test_mfccs)
案例:訓練training文件夾下的音頻,對testing文件夾下的音頻文件做分類
1、讀取training文件夾中的訓練音頻樣本,每個音頻對應一個mfcc矩陣,每個mfcc都有一個類別(apple)。
2、把所有類別為apple的mfcc合并在一起,形成訓練集。
| mfcc | |
| mfcc | apple |
| mfcc | |
.....
由上述訓練集樣本可以訓練一個用于匹配apple的HMM。
3、訓練7個HMM分別對應每個水果類別。 保存在列表中。
4、讀取testing文件夾中的測試樣本,整理測試樣本
| mfcc | apple |
| mfcc | lime |
5、針對每一個測試樣本:
1、分別使用7個HMM模型,對測試樣本計算score得分。
2、取7個模型中得分最高的模型所屬類別作為預測類別。
import os
import numpy as np
import scipy.io.wavfile as wf
import python_speech_features as sf
import hmmlearn.hmm as hl
#1. 讀取training文件夾中的訓練音頻樣本,每個音頻對應一個mfcc矩陣,每個mfcc都有一個類別(apple)。
def search_file(directory):
# 使傳過來的directory匹配當前操作系統
# {'apple':[url, url, url ... ], 'banana':[...]}
directory = os.path.normpath(directory)
objects = {}
# curdir:當前目錄
# subdirs: 當前目錄下的所有子目錄
# files: 當前目錄下的所有文件名
for curdir, subdirs, files in os.walk(directory):
for file in files:
if file.endswith('.wav'):
label = curdir.split(os.path.sep)[-1]
if label not in objects:
objects[label] = []
# 把路徑添加到label對應的列表中
path = os.path.join(curdir, file)
objects[label].append(path)
return objects
#讀取訓練集數據
train_samples = \
search_file('../ml_data/speeches/training')
'''
2. 把所有類別為apple的mfcc合并在一起,形成訓練集。
| mfcc | |
| mfcc | apple |
| mfcc | |
.....
由上述訓練集樣本可以訓練一個用于匹配apple的HMM。
'''
train_x, train_y = [], []
# 遍歷7次 apple/banana/...
for label, filenames in train_samples.items():
mfccs = np.array([])
for filename in filenames:
sample_rate, sigs = wf.read(filename)
mfcc = sf.mfcc(sigs, sample_rate)
if len(mfccs)==0:
mfccs = mfcc
else:
mfccs = np.append(mfccs, mfcc, axis=0)
train_x.append(mfccs)
train_y.append(label)
'''
訓練集:
train_x train_y
----------------
| mfcc | |
| mfcc | apple |
| mfcc | |
----------------
| mfcc | |
| mfcc | banana |
| mfcc | |
-----------------
| mfcc | |
| mfcc | lime |
| mfcc | |
-----------------
'''
# {'apple':object, 'banana':object ...}
models = {}
for mfccs, label in zip(train_x, train_y):
model = hl.GaussianHMM(n_components=4,
covariance_type='diag', n_iter=1000)
models[label] = model.fit(mfccs)
'''
4. 讀取testing文件夾中的測試樣本,針對每一個測試樣本:
1. 分別使用7個HMM模型,對測試樣本計算score得分。
2. 取7個模型中得分最高的模型所屬類別作為預測類別。
'''
#讀取測試集數據
test_samples = \
search_file('../ml_data/speeches/testing')
test_x, test_y = [], []
for label, filenames in test_samples.items():
mfccs = np.array([])
for filename in filenames:
sample_rate, sigs = wf.read(filename)
mfcc = sf.mfcc(sigs, sample_rate)
if len(mfccs)==0:
mfccs = mfcc
else:
mfccs = np.append(mfccs, mfcc, axis=0)
test_x.append(mfccs)
test_y.append(label)
'''測試集:
test_x test_y
-----------------
| mfcc | apple |
-----------------
| mfcc | banana |
-----------------
| mfcc | lime |
-----------------
'''
pred_test_y = []
for mfccs in test_x:
# 判斷mfccs與哪一個HMM模型更加匹配
best_score, best_label = None, None
for label, model in models.items():
score = model.score(mfccs)
if (best_score is None) or (best_score<score):
best_score = score
best_label = label
pred_test_y.append(best_label)
print(test_y)
print(pred_test_y)
聲音合成
根據需求獲取某個聲音的模型頻域數據,根據業務需要可以修改模型數據,逆向生成時域數據,完成聲音的合成。
案例:
import json
import numpy as np
import scipy.io.wavfile as wf
with open('../data/12.json', 'r') as f:
freqs = json.loads(f.read())
tones = [
('G5', 1.5),
('A5', 0.5),
('G5', 1.5),
('E5', 0.5),
('D5', 0.5),
('E5', 0.25),
('D5', 0.25),
('C5', 0.5),
('A4', 0.5),
('C5', 0.75)]
sample_rate = 44100
music = np.empty(shape=1)
for tone, duration in tones:
times = np.linspace(0, duration, duration * sample_rate)
sound = np.sin(2 * np.pi * freqs[tone] * times)
music = np.append(music, sound)
music *= 2 ** 15
music = music.astype(np.int16)
wf.write('../data/music.wav', sample_rate, music)
總結
以上所述是小編給大家介紹的Python實現語音識別和語音合成功能,希望對大家有所幫助,如果大家有任何疑問請給我留言,小編會及時回復大家的。在此也非常感謝大家對億速云網站的支持!
如果你覺得本文對你有幫助,歡迎轉載,煩請注明出處,謝謝!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





