溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
前言
之前寫過一個用python實現的百度新歌榜、熱歌榜下載器的文章,實現了百度新歌、熱門歌曲的爬取與下載。但那個采用的是單線程,網絡狀況一般的情況下,掃描前100首歌的時間大概得到40來秒。而且用Pyqt做的界面,在下載的過程中進行窗口操作,會出現UI阻塞的現象。
前兩天有時間調整了一下,做了幾方面的改進:
1.修改了UI界面阻塞的問題,下載的過程中可以進行其它的UI操作;
2.爬蟲程序采用一個主線程,8個子線程的方式快速爬取,網絡狀況一致的情況下,將掃描100首歌曲的時間提高到了8、9秒左右;(本地下載速度大概300K左右)
3.解析網頁的方法由之前的HtmlParser變成了現在的BeautifulSoup;
要運行此功能需要安裝PyQt、BeautifulSoup。運行之前需要在settings.py文件中配置百度賬號和密碼。
username = "your baidu acount" #配置你的百度賬號 password = "your baidu password" #配置你的百度密碼
配置好賬戶和密碼后,直接雙擊spiderMan.py文件運行即可。
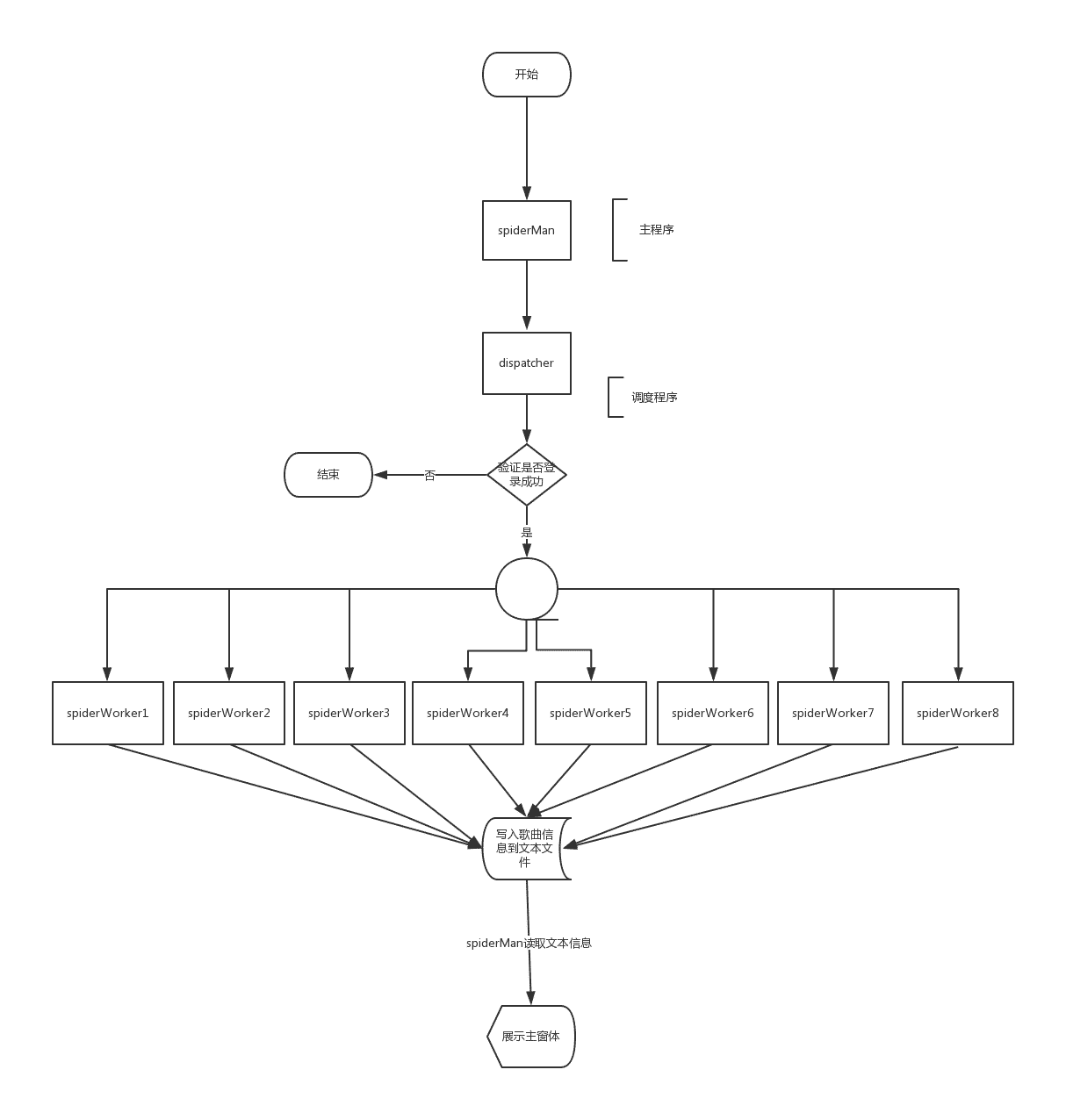
運行流程
1.首先由spiderMan.py進入主程序,開始運行。
2.主程序將控制權交給dispatcher調度程序,調度程序首先登錄百度。
3.如果登錄成功,調度程序開啟8個子線程,由這8個子線程抓取百度新歌榜或百度熱歌榜的歌曲鏈接,分析鏈接,獲取真正的下載地址,并將下載地址、歌曲名稱、歌手信息寫入一個文本文件。
4.當子線程執行完畢,主程序讀取上一步生成的文本文件,加載UI窗體。
整個過程如下圖:
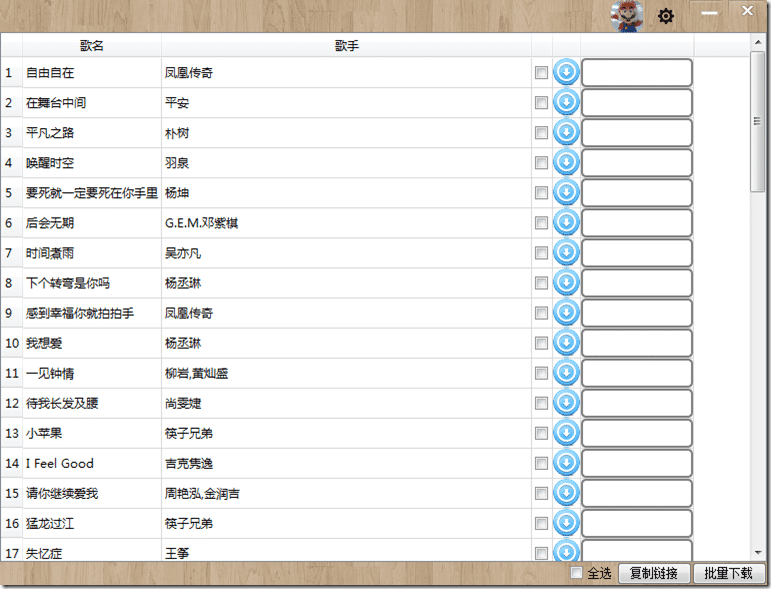
正常運行后的效果如下圖:
問題:
在github上tigerstudent提出了兩個問題:
1.文件spiderMan.py中獲取當前腳本所在的目錄 root = os.path.dirname(__file__)+"/" 獲取到的目錄為空,建議應該用os.getcwd()。
這里我實際想要的是當前腳本所在的絕對路徑,正確的腳本應該是這樣的:os.path.abspath(os.path.dirname(__file__))+"/"
那么為什么os.path.dirname(__file__)和os.getcwd()為什么都不行呢?os.path.dirname(__file__)是當前腳本相對于腳本的執行目錄的相對路徑,而os.getcwd()是腳本實際執行的目錄。新建test.py文件,代碼如下:
import os
print("os.path.dirname(__file__):"+os.path.dirname(__file__))
print("os.getcwd():"+os.getcwd())
首先定位到計算機根目錄/,執行如下命令:python /home/fengzheng/vimPython/BaiduMusicSpider-master/test.py,輸出結果:
os.path.dirname(__file__):/home/fengzheng/vimPython/BaiduMusicSpider-master os.getcwd():
定位到/home/fengzheng/vimPython/,執行如下命令:python BaiduMusicSpider-master/test.py,輸出結果:
os.path.dirname(__file__):BaiduMusicSpider-master os.getcwd():/home/fengzheng/vimPython
這樣說吧,拋開執行上的參數值,在windows下把命令理解為單擊鼠標直接運行的操作,os.path.dirname(__file__)就是所執行的腳本文件對于當前所處的目錄的相對路徑,而os.getcwd()就是當前執行這個腳本所在的路徑,即在哪個位置執行就是那個位置的路徑。
2.有一些路徑字符串中用的是”\”,正確的寫法應該是”/”,因為當時是在windows上寫的,沒太注意。
github下載地址如下:下載地址
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





