溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
簡介:
本文介紹了圖像檢索的三種實現方式,均用python完成,其中前兩種基于直方圖比較,哈希法基于像素分布。
檢索方式是:提前導入圖片庫作為檢索范圍,給出待檢索的圖片,將其與圖片庫中的圖片進行比較,得出所有相似度后進行排序,從而檢索結果為相似度由高到低的圖片。由于工程中還包含Qt界面類、觸發函數等其他部分,在該文檔中只給出關鍵函數的代碼。
開發系統:MacOS
實現方式:Qt + Python
方法一:自定義的直方圖比較算法
a) 基本思路
遍歷圖片像素點,提取R\G\B值并進行對應的計數,得到原始直方圖,但由于0-255的范圍太大,因此每一個像素值的統計量均偏小,因此分別將R\G\B的256個像素值映射到0-31共32個像素值上,將像素值范圍由256*3縮小到32*3。記錄像素值采用的數據結構為一維數組,第1到32個值為R的像素直方圖,第33到第64個值為G的像素統計,第65到96個值為B的像素統計。得到直方圖后,計算待檢索圖的直方圖和圖片庫中圖像的直方圖之間的相似性。
b) 具體實現
用到的函數:
遍歷圖片的像素點以計算直方圖:calc_Hist(img)
嘗試了兩種方式,第一種是對圖像遍歷時逐個調用getpixel()來獲取R,G,B的值,但發現這種方式的速度太慢。第二種采用的是內存讀取,利用load()函數一次性讀取圖像的像素值,然后對像素值進行遍歷,該方法的速度比逐個提取更快。
#統計直方圖,用load()載入圖片的像素pix,再分別讀取每個像素點的R\G\B值進行統計(分別為0-255)
#將256個顏色值的統計情況投影到32個,返回R\G\B投影后的統計值數組,共32*3=96個元素
def calc_Hist(img):
'''
#120張圖片,4.43s
w,h = img.size
pix = img.load() #載入圖片,pix存的是像素
calcR = [0 for i in range(0,32)]
calcG = [0 for i in range(0,32)]
calcB = [0 for i in range(0,32)]
for i in range(0,w):
for j in range(0,h):
(r,g,b) = pix[i,j]
#print (r,g,b)
calcR[r/8] += 1
calcG[g/8] += 1
calcB[b/8] += 1
calcG.extend(calcB)
calcR.extend(calcG)
return calcR
'''
#120張圖,3.49s
w,h = img.size
pix = img.load() #載入圖片,pix存的是像素
calcR = [0 for i in range(0,256)]
calcG = [0 for i in range(0,256)]
calcB = [0 for i in range(0,256)]
for i in range(0,w):
for j in range(0,h):
(r,g,b) = pix[i,j]
#print (r,g,b)
calcR[r] += 1
calcG[g] += 1
calcB[b] += 1
calcG.extend(calcB)
calcR.extend(calcG) #256*3
#calc存放最終結果,32*3
calc = [0 for i in range(0,96)]
step = 0 #calc的下標,0~95
start = 0 #每次統計的開始位置
while step < 96:
for i in range(start,start+8): #8個值為1組,統計值相加,eg:色彩值為0~7的統計值全部轉換為色彩值為0的統計值
calc[step] += calcR[i]
start = start+8
step += 1
#print calc
return calc
直方圖比較 calc_Similar(h2,h3)
采用的公式是:
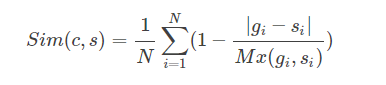
其中N為顏色級數,Sim越靠近1則兩幅圖像的相似度越高。
c) 問題和改進
簡單實現直方圖比較后,檢索的結果并不好,和預期相比誤差較大。分析原因,直方圖比較主要依靠整幅圖像的色彩統計來進行比較,而對像素的位置并沒有很好的記錄,因此會造成誤判。
同時增加calc_Similar_Split(h2,h3)函數,加入分塊比較的部分,計算方法是:對每個小塊調用calc_Similar(h2,h3),累加計算結果,最后除以16取平均值。
測試發現效果顯著提升,基于顏色相似的同時保留了形狀信息。
函數如下:
#該函數用于統一圖片大小為256*256,并且分割為16個塊,返回值是16個局部圖像句柄的數組
def split_Img(img, size = (64,64)):
img = img.resize((256,256)).convert('RGB')
w,h = img.size
sw,sh = size
return [img.crop((i,j,i+sw,j+sh)).copy() for i in xrange(0,w,sw) for j in xrange(0,h,sh)]
#計算兩個直方圖之間的相似度,h2和h3為直方圖,zip表示同步遍歷
def calc_Similar(h2,h3):
return sum(1 - (0 if g==s else float(abs(g-s))/max(g,s)) for g,s in zip(h2,h3)) / len(h2)
方法二:openCV庫的直方圖比較算法實現
openCV開源庫已經集成了直方圖提取、直方圖均衡化以及直方圖比較的功能,調用方便。為了進一步了解直方圖比較的各類實現方法,利用openCV重新進行了實驗。
a) 基本思路
對圖片庫中每個圖片提取直方圖并均衡化,然后調用cv庫函數進行直方圖比較,結果進行排序,并顯示。
b) 具體實現
首先調用cv2.imread()讀取圖像,然后調用cv2.calcHist()計算直方圖,cv2.normalize()均衡化后進入比較階段,調用cv2.compareHist(),比較待檢索圖和圖片庫圖像之間的直方圖差異,然后調用DisplayTotalPics()進行顯示。
關鍵代碼如下:
results = {} #記錄結果
reverse = True #correlation/intersection方法reverse為true,另外兩種為false
imgCV = cv2.imread(self.testImg.encode('utf-8'))
#self.testImg為待匹配圖片
testHist = cv2.calcHist([imgCV],[0,1,2],None,[8,8,8],[0,256,0,256,0,256])
#提取直方圖
testHist = cv2.normalize(testHist,testHist,0,255,cv2.NORM_MINMAX).flatten()
#均衡化
#計算self.testImg和其他圖片的直方圖差異,INTERSECTION方法效果比較好
for (k, hist) in self.index_cv.items():
#self.index_cv保存的是圖片庫中圖片的直方圖信息
d = cv2.compareHist(testHist,hist, cv2.cv.CV_COMP_INTERSECT)
results[k] = d
#對結果排序,以v即上面的d作為關鍵字
results = sorted([(v, k) for (k, v) in results.items()], reverse = reverse)
end = time.time()
print 'OpenCV Time:'
print end-start
self.DisplayTotalPics(results)
c) 問題與解決
openCV中的compareHist函數中提供了4中比較方法:
1.相關系數標準(method=CV_COMP_CORREL) 值越大,相關度越高,最大值1,最小值0
2.卡方系數標準(method=CV_COMP_CHISQR) 值越小,相關度越高,無上限,最小值0
3.相交系數標準(method=CV_COMP_INTERSECT)值大,相關度越高,最大9.455319,最小0
4.巴氏系數的標準(method=CV_COMP_BHATTACHARYYA) 值小,相關度越高,最大值1,最小值0
測試后選擇的是method = cv2.cv.CV_COMP_INTERSECT
另外,該方法的速度很快,完全基于圖像的色彩分布,但在一些情況下精度并不高。
方法三:平均哈希值比較算法實現
用到的函數:getKey(),getCode(),cmpCode()
a) 基本思路
平均哈希值的比較算法是基于像素分布的,比較對象是灰度圖的圖像指紋。圖像指紋的計算通過比較每個圖的像素值和平均像素值來計算,然后計算圖像指紋之間的漢明距離,排序后得到相似圖像。
b) 具體實現
具體方法是:計算進行灰度處理后圖片的所有像素點的平均值,然后遍歷灰度圖片每一個像素,如果大于平均值記錄為1,否則為0,這一步通過定義函數getCode(img)完成。接著計算編碼之間的漢明距離,即一組二進制數據變為另一組數據所需的步驟數,漢明距離越小,說明圖像指紋的相似度越高。計算漢明距離可以通過簡單的遍歷和計數來完成,函數為compCode(code1,code2),其中code1和code2為getCode得到的圖像指紋。
關鍵函數代碼如下:
#獲取排序時的關鍵值(即漢明距離)
def getKey(x):
return int(x[1])
#由灰度圖得到2值“指紋”,從而計算漢明距離
def getCode(img):
w,h = img.size
pixel = []
for i in range(0,w):
for j in range(0,h):
pixel_value = img.getpixel((i,j))
pixel.append(pixel_value) #加入pixel數組
avg = sum(pixel)/len(pixel) #計算像素平均值
cp = [] #二值數組
for px in pixel:
if px > avg:
cp.append(1)
else:
cp.append(0)
return cp
#計算兩個編碼之間的漢明距離
def compCode(code1,code2):
num = 0
for index in range(0,len(code1)):
if code1[index] != code2[index]:
num+=1
#print num
#print '\n'
return num
c) 問題與優化
我們發現在數據量大時,該方法的檢索速度較慢,因此我們將圖像指紋也作為圖像的屬性存在self.hashCode中,在importFolder時計算好,避免后續操作中的冗余重復計算。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





