溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關pytorch中網絡loss傳播和參數更新的示例分析,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
相比于2018年,在ICLR2019提交論文中,提及不同框架的論文數量發生了極大變化,網友發現,提及tensorflow的論文數量從2018年的228篇略微提升到了266篇,keras從42提升到56,但是pytorch的數量從87篇提升到了252篇。
TensorFlow: 228--->266
Keras: 42--->56
Pytorch: 87--->252
在使用pytorch中,自己有一些思考,如下:
1. loss計算和反向傳播
import torch.nn as nn criterion = nn.MSELoss().cuda() output = model(input) loss = criterion(output, target) loss.backward()
通過定義損失函數:criterion,然后通過計算網絡真實輸出和真實標簽之間的誤差,得到網絡的損失值:loss;
最后通過loss.backward()完成誤差的反向傳播,通過pytorch的內在機制完成自動求導得到每個參數的梯度。
需要注意,在機器學習或者深度學習中,我們需要通過修改參數使得損失函數最小化或最大化,一般是通過梯度進行網絡模型的參數更新,通過loss的計算和誤差反向傳播,我們得到網絡中,每個參數的梯度值,后面我們再通過優化算法進行網絡參數優化更新。
2. 網絡參數更新
在更新網絡參數時,我們需要選擇一種調整模型參數更新的策略,即優化算法。
優化算法中,簡單的有一階優化算法:
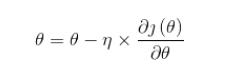
其中 就是通常說的學習率,
就是通常說的學習率,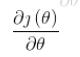 是函數的梯度;
是函數的梯度;
自己的理解是,對于復雜的優化算法,基本原理也是這樣的,不過計算更加復雜。
在pytorch中,torch.optim是一個實現各種優化算法的包,可以直接通過這個包進行調用。
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
注意:
1)在前面部分1中,已經通過loss的反向傳播得到了每個參數的梯度,然后再本部分通過定義優化器(優化算法),確定了網絡更新的方式,在上述代碼中,我們將模型的需要更新的參數傳入優化器。
2)注意優化器,即optimizer中,傳入的模型更新的參數,對于網絡中有多個模型的網絡,我們可以選擇需要更新的網絡參數進行輸入即可,上述代碼,只會更新model中的模型參數。對于需要更新多個模型的參數的情況,可以參考以下代碼:
optimizer = torch.optim.Adam([{'params': model.parameters()}, {'params': gru.parameters()}], lr=0.01) 3) 在優化前需要先將梯度歸零,即optimizer.zeros()。
3. loss計算和參數更新
import torch.nn as nn import torch criterion = nn.MSELoss().cuda() optimizer = torch.optim.Adam(model.parameters(), lr=0.01) output = model(input) loss = criterion(output, target) optimizer.zero_grad() # 將所有參數的梯度都置零 loss.backward() # 誤差反向傳播計算參數梯度 optimizer.step() # 通過梯度做一步參數更新
關于“pytorch中網絡loss傳播和參數更新的示例分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





