溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
但凡介紹數據庫連接池的文章,都會說“數據庫連接是一種關鍵的有限的昂貴的資源,這一點在多用戶的網頁應用程序中體現得尤為突出。對數據庫連接的管理能顯著影響到整個應用程序的伸縮性和健壯性,影響到程序的性能指標。數據庫連接池正是針對這個問題提出來的。數據庫連接池負責分配、管理和釋放數據庫連接,它允許應用程序重復使用一個現有的數據庫連接,而不是再重新建立一個;釋放空閑時間超過最大空閑時間的數據庫連接來避免因為沒有釋放數據庫連接而引起的數據庫連接遺漏。這項技術能明顯提高對數據庫操作的性能。”
這句話雖然說得很好,但也很讓人疑惑。比如,多個請求是怎樣共用數據庫連接池啊?
其實,數據庫連接池主要是利用了程序,靜態變量與靜態方法的概念實現的。靜態變量和靜態方法,是程序運行時,就被加載到內存中的。該進程中所有對于它的訪問,都是對“唯一”的它的訪問。所以,才能有數據庫連接池被共享的概念。
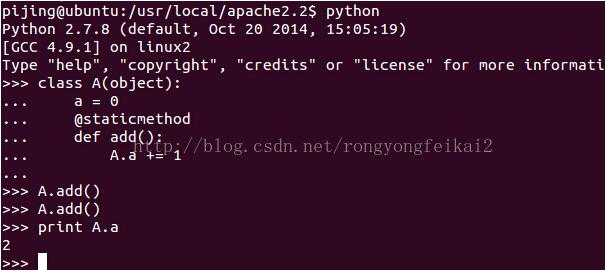
可以看到,靜態變量a以及靜態方法add,即使類A從未被實例化過,它們也都會被加載到內存中。
另外,在python的此次運行(一個進程)中,多次對a的操作,都是對為一個的這個a變量的操作,所以它的值是在被操作后累加的。
這個在我上面簡單的例子中很好理解。那么如何理解Web應用程序(如django程序)在接到url請求時的場景呢?在多個請求時,他們是如何可以共享數據庫連接池的?
我寫了一個簡單的例子:
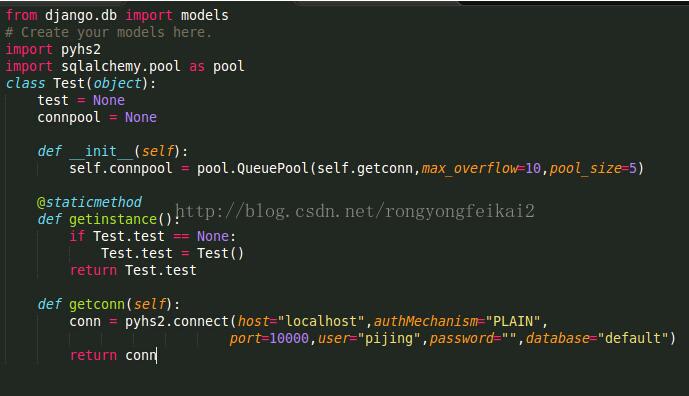
Test model,使用了單例模式,它的功能是調用sqlalchemy.pool中的數據庫連接池。
而views.py的index方法,則是調用Test的getinstance方法獲得它的實例,同時用它的數據庫連接池。
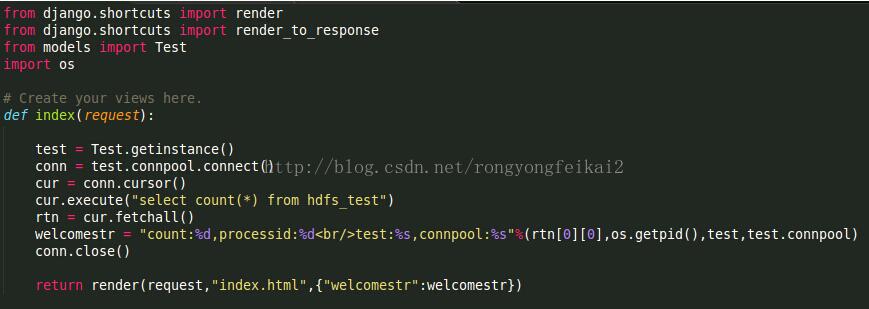
為了看得清楚,我在這個方法中增加打印了當前所屬進程的pid,test和test.connpool信息。
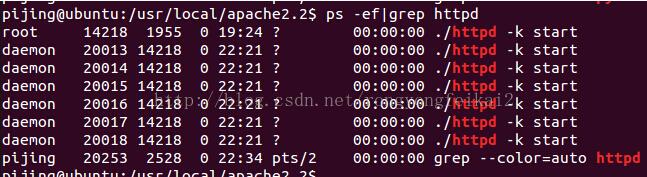
首先要說明一點,apache在windows和linux中的運行方式不盡相同(windows是兩個httpd進程,一個父進程,一個子進程,子進程里面多個線程處理請求)。在linux中,默認用prefork的方式運行。即一個父進程,多個子進程,這多個子進程負責處理web請求。
如下圖所示:
然后我們嘗試多次url請求(適當變化url,避免緩存);并記錄結果:
http://10.67.2.21:8081/ips/
count:3,processid:20016<br/>test:<ipsapp.models.Test object at 0x7f2b1070ac50>,connpool:<sqlalchemy.pool.QueuePool object at 0x7f2b1070ad10>
http://10.67.2.21:8081/ips/?user=kjsdkfjsdf&kljsdlkfjsdf
count:3,processid:20013<br/>test:<ipsapp.models.Test object at 0x7f2b107c6c10>,connpool:<sqlalchemy.pool.QueuePool object at 0x7f2b107c6cd0>
http://10.67.2.21:8081/ips/?user=kjsdkfjsdf&kljsdlkfjsdf&pass=ksjdkjdf
count:3,processid:20018<br/>test:<ipsapp.models.Test object at 0x7f2b103c6c50>,connpool:<sqlalchemy.pool.QueuePool object at 0x7f2b103c6d10>
http://10.67.2.21:8081/ips/?user=123u42i3u4
count:3,processid:20016<br/>test:<ipsapp.models.Test object at 0x7f2b1070ac50>,connpool:<sqlalchemy.pool.QueuePool object at 0x7f2b1070ad10>
http://10.67.2.21:8081/ips/?user=123u42i3u4&tewstsjdfkjslfj
count:3,processid:20013<br/>test:<ipsapp.models.Test object at 0x7f2b107c6c10>,connpool:<sqlalchemy.pool.QueuePool object at 0x7f2b107c6cd0>
http://10.67.2.21:8081/ips/?user=passwode
count:3,processid:20018<br/>test:<ipsapp.models.Test object at 0x7f2b103c6c50>,connpool:<sqlalchemy.pool.QueuePool object at 0x7f2b103c6d10>
http://10.67.2.21:8081/ips/?newiusd=kjsdkjfd&kjsdkjf=ksdjflksjdlkf
count:3,processid:20016<br/>test:<ipsapp.models.Test object at 0x7f2b1070ac50>,connpool:<sqlalchemy.pool.QueuePool object at 0x7f2b1070ad10>
apache pid Test object QueuePool object
20016 0x7f2b1070ac50 0x7f2b1070ad10
20013 0x7f2b107c6c10 0x7f2b107c6cd0
20018 0x7f2b103c6c50 0x7f2b103c6d10
20016 0x7f2b1070ac50 0x7f2b1070ad10
20013 0x7f2b107c6c10 0x7f2b107c6cd0
20018 0x7f2b103c6c50 0x7f2b103c6d10
20016 0x7f2b1070ac50 0x7f2b1070ad10
我把分屬于不同apache進程處理的請求用顏色標出了,在本例子中,7個請求,分配到了3個apache進程處理。可以看到,被同一個apache子進程處理的請求,是共用同一個test和test.connpool實例的,即他們共享數據庫連接池。
所以,數據庫連接池,對于web請求而言,是屬于同一個apache子進程處理的請求共用一個數據庫連接池。
以上這篇淺談django url請求與數據庫連接池的共享問題就是小編分享給大家的全部內容了,希望能給大家一個參考,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





