溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
實際應用中,可能會涉及處理 pdf 文件,PyPDF2 就是這樣一個庫,使用它可以輕松的處理 pdf 文件,它提供了讀,割,合并,文件轉換等多種操作。
文檔地址:http://pythonhosted.org/PyPDF2/
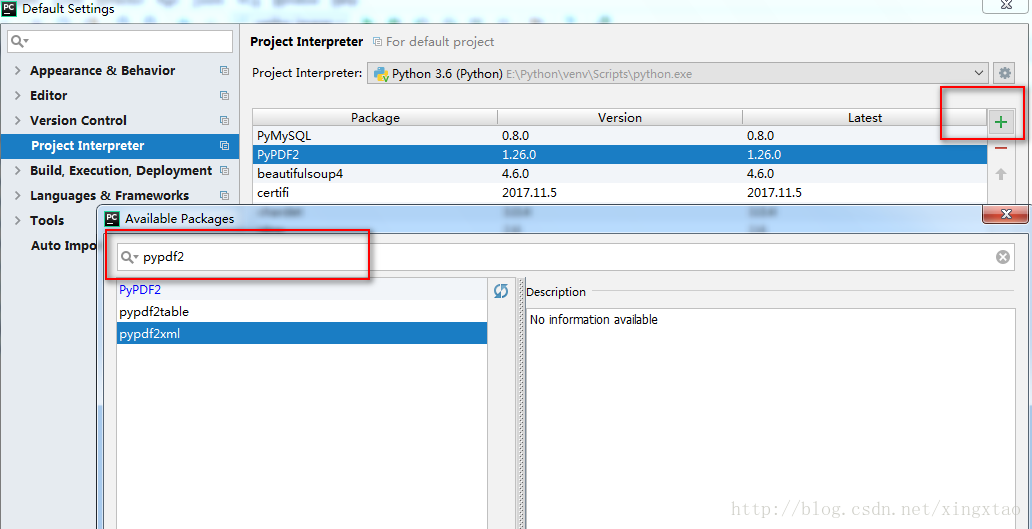
PyPDF2 安裝
PyCharm 安裝:File -> Default Settings -> Project Interpreter
PdfFileReader
構造方法:
PyPDF2.PdfFileReader(stream,strict = True,warndest = None,overwriteWarnings = True)
初始化一個 PdfFileReader 對象,此操作可能需要一些時間,因為 PDF 流的交叉引用表被讀入內存。
參數:
PdfFileReader 對象的屬性和方法
| 屬性和方法 | 描述 |
|---|---|
| getDestinationPageNumber(destination) | 檢索給定目標對象的頁碼 |
| getDocumentInfo() | 檢索 PDF 文件的文檔信息字典 |
| getFields(tree = None,retval = None,fileObj= None) | 如果此 PDF 包含交互式表單字段,則提取字段數據, |
| getFormTextFields() | 從文檔中檢索帶有文本數據(輸入,下拉列表)的表單域 |
| getNameDestinations(tree = None,retval= None) | 檢索文檔中的指定目標 |
| getNumPages() | 計算此 PDF 文件中的頁數 |
| getOutlines(node = None,outline = None,) | 檢索文檔中出現的文檔大綱 |
| getPage(pageNumber) | 從這個 PDF 文件中檢索指定編號的頁面 |
| getPageLayout() | 獲取頁面布局 |
| getPageMode() | 獲取頁面模式 |
| getPageNumber(pageObject) | 檢索給定 pageObject 處于的頁碼 |
| getXmpMetadata() | 從 PDF 文檔根目錄中檢索 XMP 數據 |
| isEncrypted | 顯示 PDF 文件是否加密的只讀布爾屬性 |
| namedDestinations | 訪問該getNamedDestinations()函數的只讀屬性 |
PDF 讀取操作:
# encoding:utf-8
from PyPDF2 import PdfFileReader, PdfFileWriter
readFile = 'C:/Users/Administrator/Desktop/RxJava 完全解析.pdf'
# 獲取 PdfFileReader 對象
pdfFileReader = PdfFileReader(readFile) # 或者這個方式:pdfFileReader = PdfFileReader(open(readFile, 'rb'))
# 獲取 PDF 文件的文檔信息
documentInfo = pdfFileReader.getDocumentInfo()
print('documentInfo = %s' % documentInfo)
# 獲取頁面布局
pageLayout = pdfFileReader.getPageLayout()
print('pageLayout = %s ' % pageLayout)
# 獲取頁模式
pageMode = pdfFileReader.getPageMode()
print('pageMode = %s' % pageMode)
xmpMetadata = pdfFileReader.getXmpMetadata()
print('xmpMetadata = %s ' % xmpMetadata)
# 獲取 pdf 文件頁數
pageCount = pdfFileReader.getNumPages()
print('pageCount = %s' % pageCount)
for index in range(0, pageCount):
# 返回指定頁編號的 pageObject
pageObj = pdfFileReader.getPage(index)
print('index = %d , pageObj = %s' % (index, type(pageObj))) # <class 'PyPDF2.pdf.PageObject'>
# 獲取 pageObject 在 PDF 文檔中處于的頁碼
pageNumber = pdfFileReader.getPageNumber(pageObj)
print('pageNumber = %s ' % pageNumber)
輸出結果:
documentInfo = {'/Title': IndirectObject(157, 0), '/Producer': IndirectObject(158, 0), '/Creator': IndirectObject(159, 0), '/CreationDate': IndirectObject(160, 0), '/ModDate': IndirectObject(160, 0), '/Keywords': IndirectObject(161, 0), '/AAPL:Keywords': IndirectObject(162, 0)}
pageLayout = None
pageMode = None
xmpMetadata = None
pageCount = 3
index = 0 , pageObj = <class 'PyPDF2.pdf.PageObject'>
pageNumber = 0
index = 1 , pageObj = <class 'PyPDF2.pdf.PageObject'>
pageNumber = 1
index = 2 , pageObj = <class 'PyPDF2.pdf.PageObject'>
pageNumber = 2
PdfFileWriter
這個類支持 PDF 文件,給出其他類生成的頁面。
| 屬性和方法 | 描述 |
|---|---|
| addAttachment(fname,fdata) | 在 PDF 中嵌入文件 |
| addBlankPage(width= None,height=None) | 追加一個空白頁面到這個 PDF 文件并返回它 |
| addBookmark(title,pagenum,parent=None, color=None,bold=False,italic=False,fit='/fit,*args') |
|
| addJS(javascript) | 添加將在打開此 PDF 是啟動的 javascript |
| addLink(pagenum,pagedest,rect,border=None,fit='/fit',*args) | 從一個矩形區域添加一個內部鏈接到指定的頁面 |
| addPage(page) | 添加一個頁面到這個PDF 文件,該頁面通常從 PdfFileReader 實例獲取 |
| getNumpages() | 頁數 |
| getPage(pageNumber) | 從這個 PDF 文件中檢索一個編號的頁面 |
| insertBlankPage(width=None,height=None,index=0) | 插入一個空白頁面到這個 PDF 文件并返回它,如果沒有指定頁面大小,就使用最后一頁的大小 |
| insertPage(page,index=0) | 在這個 PDF 文件中插入一個頁面,該頁面通常從 PdfFileReader 實例獲取 |
| removeLinks() | 從次數出中刪除連接盒注釋 |
| removeText(ignoreByteStringObject = False) | 從這個輸出中刪除圖像 |
| write(stream) | 將添加到此對象的頁面集合寫入 PDF 文件 |
PDF 寫入操作:
def addBlankpage():
readFile = 'C:/Users/Administrator/Desktop/RxJava 完全解析.pdf'
outFile = 'C:/Users/Administrator/Desktop/copy.pdf'
pdfFileWriter = PdfFileWriter()
# 獲取 PdfFileReader 對象
pdfFileReader = PdfFileReader(readFile) # 或者這個方式:pdfFileReader = PdfFileReader(open(readFile, 'rb'))
numPages = pdfFileReader.getNumPages()
for index in range(0, numPages):
pageObj = pdfFileReader.getPage(index)
pdfFileWriter.addPage(pageObj) # 根據每頁返回的 PageObject,寫入到文件
pdfFileWriter.write(open(outFile, 'wb'))
pdfFileWriter.addBlankPage() # 在文件的最后一頁寫入一個空白頁,保存至文件中
pdfFileWriter.write(open(outFile,'wb'))
結果是:在寫入的 copy.pdf 文檔的最后最后一頁寫入了一個空白頁。
分割文檔(取第五頁之后的頁面)
def splitPdf():
readFile = 'C:/Users/Administrator/Desktop/RxJava 完全解析.pdf'
outFile = 'C:/Users/Administrator/Desktop/copy.pdf'
pdfFileWriter = PdfFileWriter()
# 獲取 PdfFileReader 對象
pdfFileReader = PdfFileReader(readFile) # 或者這個方式:pdfFileReader = PdfFileReader(open(readFile, 'rb'))
# 文檔總頁數
numPages = pdfFileReader.getNumPages()
if numPages > 5:
# 從第五頁之后的頁面,輸出到一個新的文件中,即分割文檔
for index in range(5, numPages):
pageObj = pdfFileReader.getPage(index)
pdfFileWriter.addPage(pageObj)
# 添加完每頁,再一起保存至文件中
pdfFileWriter.write(open(outFile, 'wb'))
合并文檔
def mergePdf(inFileList, outFile):
'''
合并文檔
:param inFileList: 要合并的文檔的 list
:param outFile: 合并后的輸出文件
:return:
'''
pdfFileWriter = PdfFileWriter()
for inFile in inFileList:
# 依次循環打開要合并文件
pdfReader = PdfFileReader(open(inFile, 'rb'))
numPages = pdfReader.getNumPages()
for index in range(0, numPages):
pageObj = pdfReader.getPage(index)
pdfFileWriter.addPage(pageObj)
# 最后,統一寫入到輸出文件中
pdfFileWriter.write(open(outFile, 'wb'))
PageObject
PageObject(pdf=None,indirectRef=None)
此類表示 PDF 文件中的單個頁面,通常這個對象是通過訪問 PdfFileReader 對象的 getPage() 方法來得到的,也可以使用 createBlankPage() 靜態方法創建一個空的頁面。
參數:
PageObject 對象的屬性和方法
| 屬性或方法 | 描述 |
|---|---|
| static createBlankPage(pdf=None,width=None,height=None) | 返回一個新的空白頁面 |
| extractText() | 找到所有文本繪圖命令,按照他們在內容流中提供的順序,并提取文本 |
| getContents() | 訪問頁面內容,返回 Contents 對象或 None |
| rotateClockwise(angle) | 順時針旋轉 90 度 |
| scale(sx,sy) | 通過向其內容應用轉換矩陣并更新頁面大小 |
粗略讀取 PDF 文本內容
def getPdfContent(filename):
pdf = PdfFileReader(open(filename, "rb"))
content = ""
for i in range(0, pdf.getNumPages()):
pageObj = pdf.getPage(i)
extractedText = pageObj.extractText()
content += extractedText + "\n"
# return content.encode("ascii", "ignore")
return content
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





