溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關python的PyPDF2怎么實現pdf文件切割和合并,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
在百度了一番后,發現大多都是使用 Adobe Acrobat 軟件進行剪裁,這完全不 Pythonic,因此又找了用 Python 處理 PDF 文件的方法,最后發現了 PyPDF2 這個庫,本文將利用這個庫,實現對 PDF 的分割。
首先,你需要通過 pip 安裝這個庫:
pip install PyPDF2
要使用python的
# 導入讀寫pdf模塊
from PyPDF2 import PdfFileReader, PdfFileWriter
'''
注意:
頁數從0開始索引
range()是左閉右開區間
'''
def split_pdf(file_name, start_page, end_page, output_pdf):
'''
:param file_name:待分割的pdf文件名
:param start_page: 執行分割的開始頁數
:param end_page: 執行分割的結束位頁數
:param output_pdf: 保存切割后的文件名
'''
# 讀取待分割的pdf文件
input_file = PdfFileReader(open(file_name, 'rb'))
# 實例一個 PDF文件編寫器
output_file = PdfFileWriter()
# 把分割的文件添加在一起
for i in range(start_page, end_page):
output_file.addPage(input_file.getPage(i))
# 將分割的文件輸出保存
with open(output_pdf, 'wb') as f:
output_file.write(f)
def merge_pdf(merge_list, output_pdf):
"""
merge_list: 需要合并的pdf列表
output_pdf:合并之后的pdf名
"""
# 實例一個 PDF文件編寫器
output = PdfFileWriter()
for ml in merge_list:
pdf_input = PdfFileReader(open(ml, 'rb'))
page_count = pdf_input.getNumPages()
for i in range(page_count):
output.addPage(pdf_input.getPage(i))
output.write(open(output_pdf, 'wb'))
if __name__ == '__main__':
# 分割pdf
split_pdf("test.pdf", 0, 3, "0-2.pdf")
split_pdf("test.pdf", 7, 12, "7-11.pdf")
split_pdf("test.pdf", 18, 23, "18-22.pdf")
split_pdf("test.pdf", 27, 33, "26-32.pdf")
split_pdf("test.pdf", 40, 44, "40-43.pdf")
split_pdf("test.pdf", 46, 51, "46-50.pdf")
split_pdf("test.pdf", 58, 66, "58-65.pdf")
split_pdf("test.pdf", 77, 84, "77-83.pdf")
split_pdf("test.pdf", 93, 97, "93-96.pdf")
split_pdf("test.pdf", 102, 106, "102-105.pdf")
# 合并pdf
# 合并的pdf列表
pdf_list = ["0-2.pdf", "7-11.pdf", "18-22.pdf", "26-32.pdf", "40-43.pdf", "46-50.pdf", "58-65.pdf", "77-83.pdf", "93-96.pdf", "102-105.pdf"]
merge_pdf(pdf_list, "all.pdf")下面是切分好的文件效果,完美
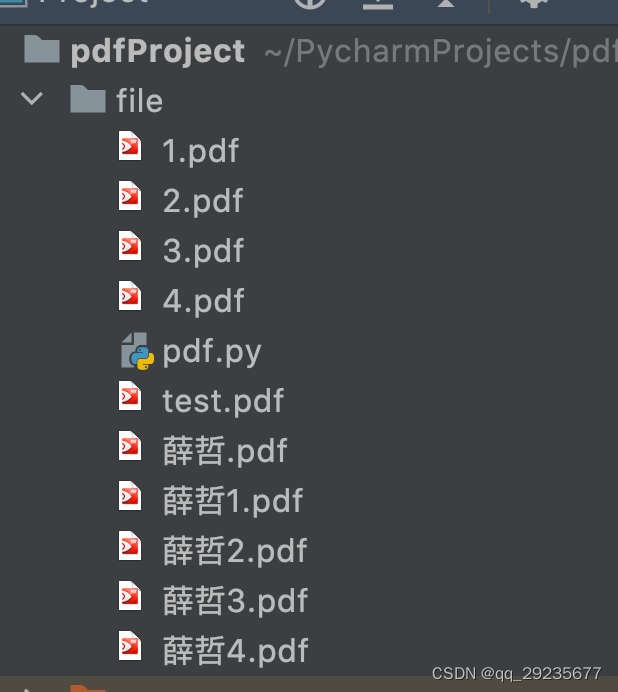
關于“python的PyPDF2怎么實現pdf文件切割和合并”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





