溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
re模塊
re 模塊使 Python 語言擁有全部的正則表達式功能。
compile 函數根據一個模式字符串和可選的標志參數生成一個正則表達式對象。該對象擁有一系列方法用于正則表達式匹配和替換。
轉義符
正則表達式中用“\”表示轉義,而python中也用“\”表示轉義,當遇到特殊字符需要轉義時,你要花費心思到底需要幾個“\”。所以為了避免這個情況,推薦使用原生字符串類型(raw string)來書寫正則表達式。
方法很簡單,只需要在表達式前面加個“r”即可,如下:
r'\d{2}-\d{8}'
r'\bt\w*\b'常用函數

re.match()
從字符串的起始位置匹配,匹配成功,返回一個匹配的對象,否則返回None
語法:re.match(pattern, string, flags=0)
pattern:匹配的正則表達式
string:要匹配的字符串
flags:標志位,用于控制正則表達式的匹配方式,如:是否區分大小寫,多行匹配等等;flags=0表示不進行特殊指定可選標志如下:
修飾符被指定為一個可選的標志。多個標志可以通過按位 OR(|) 它們來指定。如 re.I | re.M 被設置成 I 和 M 標志

re.search()
掃描整個字符串并返回第一個成功的匹配對象,否則返回None
語法:re.search(pattern, string, flags=0)
re.match與re.search的區別
re.match只匹配字符串的開始,如果字符串開始不符合正則表達式,則匹配失敗,函數返回None;而re.search匹配整個字符串,直到找到一個匹配(注意:僅僅是第一個)
re.findall()
在字符串中找到正則表達式所匹配的所有子串,并返回一個列表,如果沒有找到匹配的,則返回空列表
注意: match 和 search 是匹配一次,而findall 匹配所有
re.split()
根據正則表達式中的分隔符把字符分割為一個列表并返回成功匹配的列表.
re.sub()
用于替換字符串中的匹配項
語法: re.sub(pattern, repl, string, count=0)
pattern : 正則中的模式字符串。
repl : 替換的字符串,也可為一個函數。
string : 要被查找替換的原始字符串。
count : 模式匹配后替換的最大次數,默認 0 表示替換所有的匹配。re.compile()
compile 函數用于編譯正則表達式,生成一個正則表達式( Pattern )對象,然后就可以用編譯后的正則表達式去匹配字符串
pattern : 一個字符串形式的正則表達式
flags :可選,表示匹配模式,比如忽略大小寫,多行模式等貪婪匹配和非貪婪匹配
貪婪匹配:匹配盡可能多的字符; 非貪婪匹配:匹配盡可能少的字符
python的正則匹配默認是貪婪匹配
>>> re.match(r'^(\w+)(\d*)$','abc123').groups()
('abc123', '')
>>> re.match(r'^(\w+?)(\d*)$','abc123').groups()
('abc', '123')
表達式1:
\w+表示匹配字母或數字或下劃線或漢字并重復1次或更多次;\d*表示匹配數字并重復0次或更多次。
分組1中(\w)是貪婪匹配,它會在滿足分組2(\d*)的情況下匹配盡可能多的字符,
因為分組2(\d*)匹配0個數字也滿足,所以分組1就把所有字符全部匹配掉了,分組2只能匹配空了。
表達式2:在表達式后加個?即可進行非貪婪匹配,如上面的(\w+?),
因為分組1進行非貪婪匹配,也就是滿足分組2匹配的情況下,分組1盡可能少的匹配,
這樣的話,上面分組2(\d*)會把所有數字(123)都匹配,所以分組1匹配到(abc)常見匹配模式
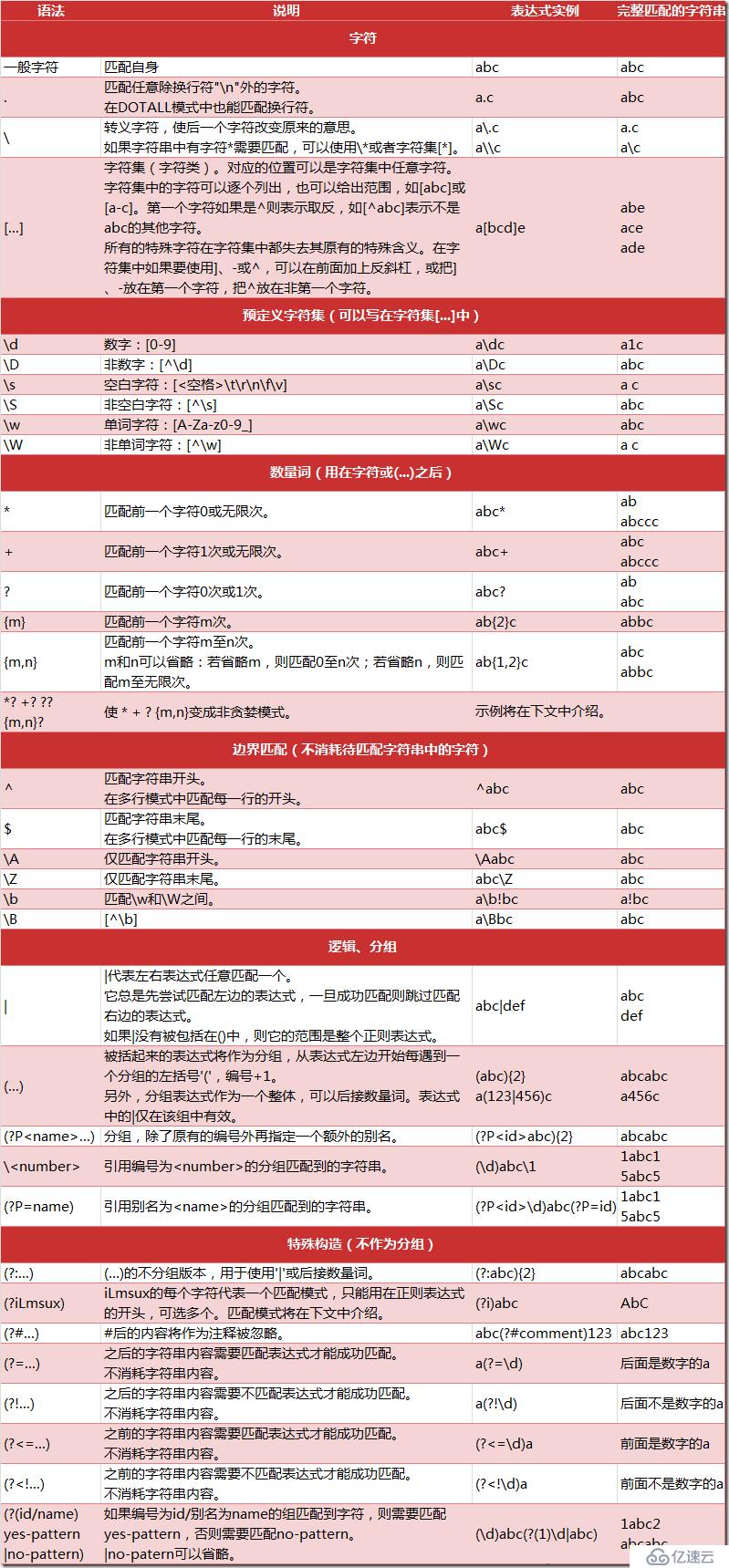
正則式需要匹配不定長的字符串,那就一定需要表示重復的指示符。Python的正則式表示重復的功能很豐富靈活。重復規則的一般的形式是在一條字符規則后面緊跟一個表示重復次數的規則,已表明需要重復前面的規則一定的次數。匹配規則舉例
1.普通字符:大多數字符和字母都會和自身匹配
re.findall("alexsel","gtuanalesxalexselericapp")
['alexsel']
re.findall("alexsel","gtuanalesxalexswxericapp")
[]
re.findall("alexsel","gtuanalesxalexselwupeiqialexsel")
['alexsel', 'alexsel']2.元字符: . ^ $ * + ? { } [ ] | ( ) \
?. :匹配一個除了換行符任意一個字符
re.findall("alexsel.w","aaaalexselaw")
['alexselaw']
#一個點只能匹配一個字符^ :只有后面跟的字符串在開頭,才能匹配上
re.findall("^alexsel","gtuanalesxalexselgeappalexsel")
[]
re.findall("^alexsel","alexselgtuanalesxalexselwgtappqialexsel")
['alexsel']
#"^"這個符號控制開頭,所以寫在開頭$ :只有它前面的字符串在檢測的字符串的最后,才能匹配上
re.findall("alexsel$","alexselseguanalesxalexselganapp")
[]
re.findall("alexsel$","alexselgtaanalesxalexsssiqialexsel")
['alexsel']*:它控制它前面那個字符,他前面那個字符出現0到多個都可以匹配上
re.findall("alexsel*","aaaalexse")
['alexse']
re.findall("alexsel*","aaaalexsel")
['alexsel']
re.findall("alexsel*","aaaalexsellllll")
['alexsellllll']+:匹配前面那個字符1到多次
re.findall("alexsel+","aaaalexselll")
['aleselll']
re.findall("alexsel+","aaaalexsel")
['alexsel']
re.findall("alexsel+","aaaalexse")
[]? :匹配前面那個字符0到1個,多余的只匹配一個
re.findall("alexsel?","aaaalexse")
['ale']
re.findall("alexsel?","aaaalexsel")
['alexsel']
re.findall("alexsel?","aaaalexsellll")
['alexsel']{} :控制它前面一個字符的匹配個數,可以有區間(閉區間),有區間的情況下按照多的匹配
re.findall("alexsel{3}","aaaalexselllll")
['alexselll']
re.findall("alexsel{3}","aaaalexsell")
[]
re.findall("alexsel{3}","aaaalexse")
[]
re.findall("alexsel{3}","aaaalexselll")
['alexselll']
re.findall("alexsel{3,5}","aaaalexsellllllll")
['alexselllll']
re.findall("alexsel{3,5}","aaaalexselll")
['alexselll']
re.findall("alexsel{3,5}","aaaalexsell")
[]\ :
后面跟元字符去除特殊功能,
后面跟普通字符實現特殊功能。
引用序號對應的字組所匹配的字符串 (一個括號為一個組)。
在開頭加上 r 表示不轉義。
#\2 就相當于第二個組(eric)
re.search(r"(alexsel)(eric)com\2","alexselericcomeric").group()
'alexselericcomeric'
re.search(r"(alexsel)(eric)com\1","alexselericcomalex").group()
'alexselericcomalex'
re.search(r"(alexsel)(eric)com\1\2","alexselericcomalexseleric").group()
'alexselericcomalexeric'\d :匹配任何十進制數;它相當于類[0-9]
re.findall("\d","aaazz1111344444c")
['1', '1', '1', '1', '3', '4', '4', '4', '4', '4']
re.findall("\d\d","aaazz1111344444c")
['11', '11', '34', '44', '44']
re.findall("\d0","aaazz1111344444c")
[]
re.findall("\d3","aaazz1111344444c")
['13']
re.findall("\d4","aaazz1111344444c")
['34', '44', '44']\D :匹配任何非數字字符;它相當于類[^0-9]
re.findall("\D","aaazz1111344444c")
['a', 'a', 'a', 'z', 'z', 'c']
re.findall("\D\D","aaazz1111344444c")
['aa', 'az']
re.findall("\D\d\D","aaazz1111344444c")
[]
re.findall("\D\d\D","aaazz1z111344444c")
['z1z']\s :匹配任何空白字符;它相當于類[ \t\n\r\f\v]
re.findall("\s","aazz1 z11..34c")
[' ']\S :匹配任何非空白字符;它相當于類[^ \t\n\r\f\v]
\w :匹配任何字母數字字符;他相當于類[a-zA-Z0-9_]
re.findall("\w","aazz1z11..34c")
['a', 'a', 'z', 'z', '1', 'z', '1', '1', '3', '4', 'c']\W :匹配任何非字母數字字符;它相當于類[^a-zA-Z0-9_]
\b :匹配一個單詞邊界,也就是指單詞和空格間的位置
re.findall(r"\babc\b","abc sdsadasabcasdsadasdabcasdsa")
['abc']
re.findall(r"\balexsel\b","abc alexsel abcasdsadasdabcasdsa")
['alexsel']
re.findall("\\balexsel\\b","abc alexsel abcasdsadasdabcasdsa")
['alexsel']
re.findall("\balexsel\b","abc alexsel abcasdsadasdabcasdsa")
[]() :把括號內字符作為一個整體去處理
re.search(r"a(\d+)","a222bz1144c").group()
'a222'
re.findall("(ab)*","aabz1144c")
['', 'ab', '', '', '', '', '', '', ''] #將括號里的字符串作為整和后面字符逐個進行匹配,在這里就首先將后面字符串里的a和ab進
#行匹配,開頭匹配成功,在看看后面是a,和ab中的第二個不匹配,然后就看后面字符串中的第二個a,和ab匹配,首先a匹配成功,b也匹配成功,拿到匹配
#然后在看后面字符串中的第三個是b,開頭匹配失敗,到第四個,后面依次
re.search(r"a(\d+)","a222bz1144c").group()
'a222'
re.search(r"a(\d+?)","a222bz1144c").group() +的最小次數為1
'a2'
re.search(r"a(\d*?)","a222bz1144c").group() *的最小次數為0
'a'
#非貪婪匹配模式 加? ,但是如果后面還有匹配字符,就無法實現非貪婪匹配
#(如果前后均有匹配條件,則無法實現非貪婪模式)
re.findall(r"a(\d+?)b","aa2017666bz1144c")
['2017666']
re.search(r"a(\d*?)b","a222bz1144c").group()
'a222b'
re.search(r"a(\d+?)b","a277722bz1144c").group()
'a277722b'元字符在字符集里就代表字符,沒有特殊意義(有幾個例外)
re.findall("a[.]d","aaaacd")
[]
re.findall("a[.]d","aaaa.d")
['a.d']例外
[-] [^] []
[-] 匹配單個字符,a到z所有的字符
re.findall("[a-z]","aaaa.d")
['a', 'a', 'a', 'a', 'd']
re.findall("[a-z]","aaazzzzzaaccc")
['a', 'a', 'a', 'z', 'z', 'z', 'z', 'z', 'a', 'a', 'c', 'c', 'c']
re.findall("[1-3]","aaazz1111344444c")
['1', '1', '1', '1', '3'][^] 匹配除了這個范圍里的字符,(^在這里有 非 的意思)
re.findall("[^1-3]","aaazz1111344444c")
['a', 'a', 'a', 'z', 'z', '4', '4', '4', '4', '4', 'c']
re.findall("[^1-4]","aaazz1111344444c")
['a', 'a', 'a', 'z', 'z', 'c'][]
re.findall("[\d]","aazz1144c")
['1', '1', '4', '4']我們首先考察的元字符是"[" 和 "]"。它們常用來指定一個字符類別,所謂字符類 別就是你想匹配的一個字符集。字符可以單個列出,也可以用“-”號分隔的兩個給定 字符來表示一個字符區間。例如,[abc] 將匹配"a", "b", 或 "c"中的任意一個字 符;也可以用區間[a-c]來表示同一字符集,和前者效果一致。如果你只想匹配小寫 字母,那么 RE 應寫成 [a-z],元字符在類別里并不起作用。例如,[akm$]將匹配字符"a", "k", "m", 或 "$" 中 的任意一個;"$"通常用作元字符,但在字符類別里,其特性被除去,恢復成普通字符。
單詞邊界
re.findall(r"\babc","abcsd abc")
['abc', 'abc']
re.findall(r"abc\b","abcsd abc")
['abc']
re.findall(r"abc\b","abcsd abc*")
['abc']
re.findall(r"\babc","*abcsd*abc")
['abc', 'abc']#檢測單詞邊界不一定就是空格,還可以是除了字母以外的特殊字符
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





