溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關Python中怎么爬取電影天堂數據,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
首先打開Pycharm點擊File再點開setting。
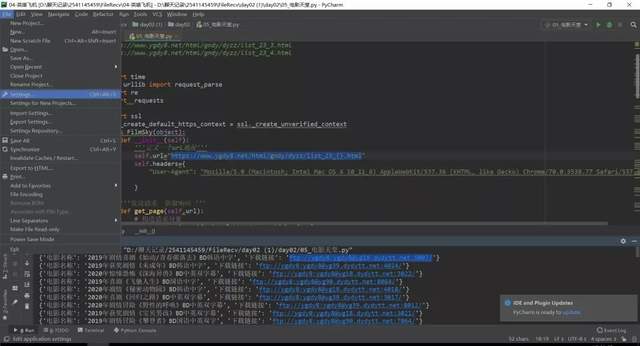
打開后會出現這個界面點擊你的項目名字(project:(你的項目名字))project interpreter點擊加號下載我們需要的庫本項目需要(requests,requests,time,re模塊),如下圖所示。
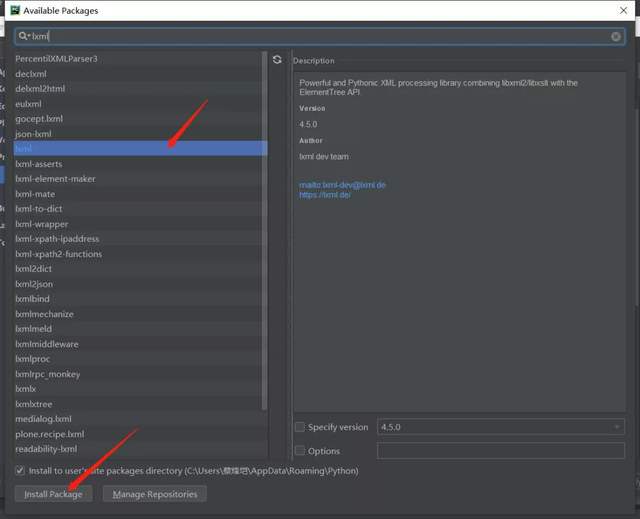
我們需要(requests,requests,time,re模塊 ),如下圖所示。
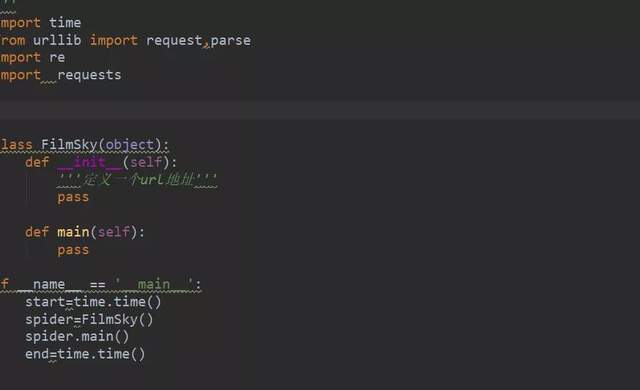
這個time是用于防止反爬,設置的時間延時。
首先我們來分析一下這個網址下一頁得到特點。

在主方法main函數里邊用for循環實現遍歷網址。
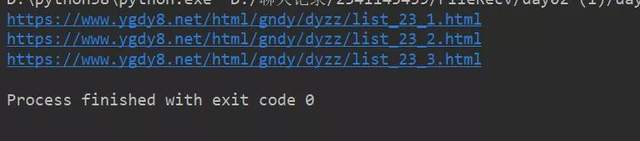
說明你已經成功一半了加油!!
現在我們需要對這些網址發生請求,為了更直觀的看出來,我們用一個類寫。
我們用requests發生請求 這個網站的編碼是gbk (怎么看網站的編碼?)。
打開一個網站右鍵檢查在header的標簽,以這個網站為例,可以看到charset=“gb312”。
這個gb2312就是編碼 我們常見的編碼方式有2種(utf_8, gbk)。
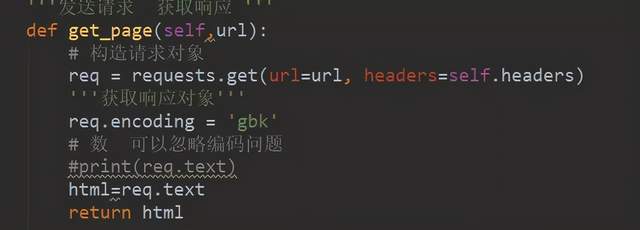
我們可以驗證一下是不是真的請求到了。使用Print(html)看到這個結果(一個完整的html網頁)說明請求成功。
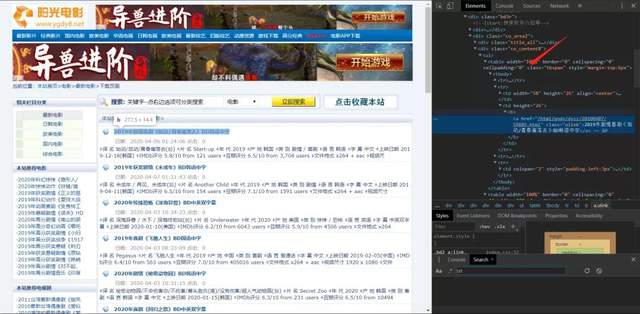
所以我們可以先找到table,一層一層的去找,可以參考一下下面的圖。
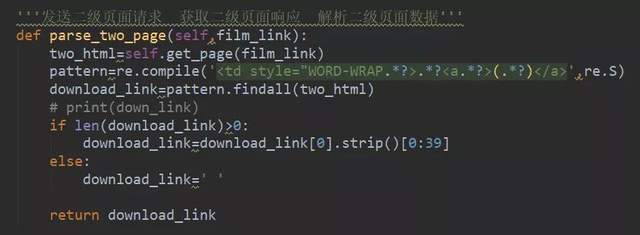
點開第二級頁面如圖右鍵點擊下載鏈接,如下圖所示:
我們用正則表達式解析 得到我們下載鏈接地址,如下圖所示:

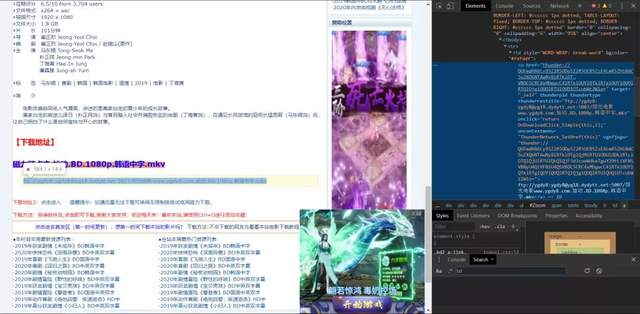
得到結果,如下圖所示:
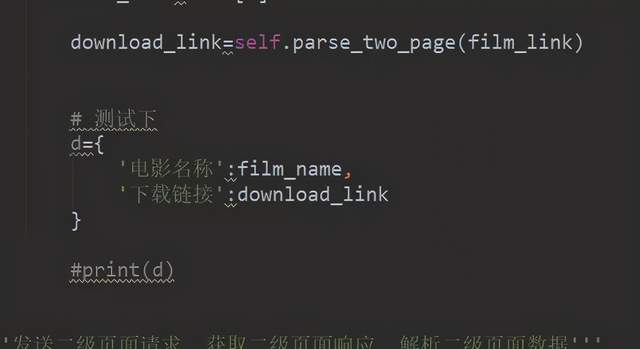
最后我們優化一下請求的代碼有點重復 我們優化一下;
用一個值去保存說明請求頭的內容以后請求我們只有調用這個方法進行請求就好,如下圖所示:
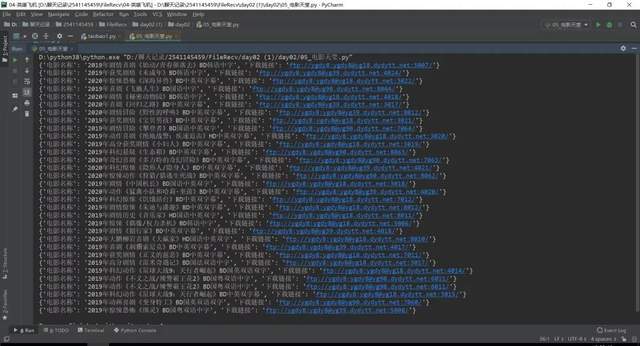
上述就是小編為大家分享的Python中怎么爬取電影天堂數據了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





