溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下如何使用Python自動爬取圖片并保存,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
用python來實現對百度圖片的爬取并保存,以情緒圖片為例,百度搜索可得到下圖所示
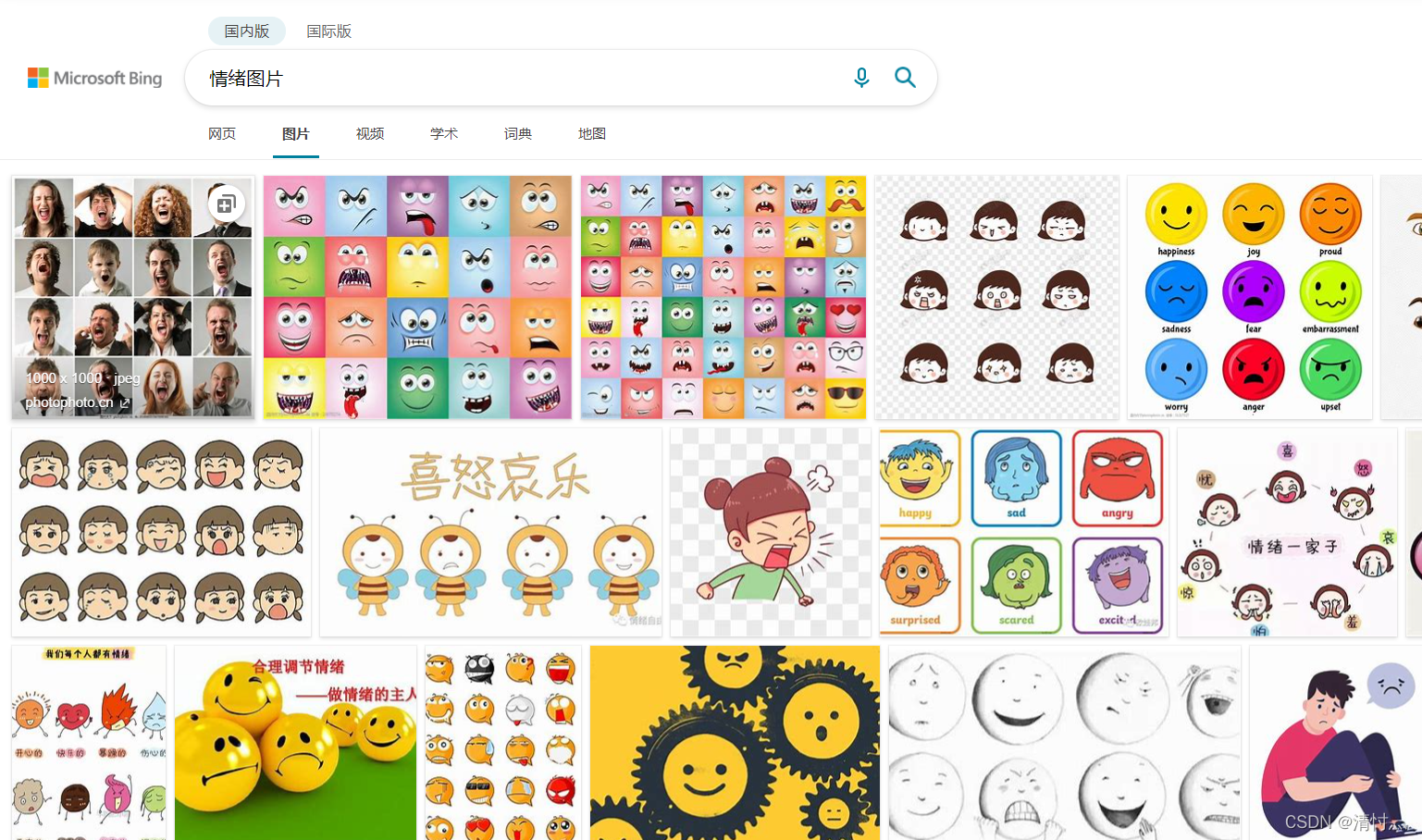
f12打開源碼

在此處可以看到這次我們要爬取的圖片的基本信息是在img - scr中
這次的爬取主要用了如下的第三方庫
import re import time import requests from bs4 import BeautifulSoup import os
簡單構思可以分為三個小部分
1.獲取網頁內容
2.解析網頁
3.保存圖片至相應位置
下面來看第一部分:獲取網頁內容
baseurl = 'https://cn.bing.com/images/search?q=%E6%83%85%E7%BB%AA%E5%9B%BE%E7%89%87&qpvt=%e6%83%85%e7%bb%aa%e5%9b%be%e7%89%87&form=IGRE&first=1&cw=418&ch=652&tsc=ImageBasicHover'
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.67"}
response = requests.get(baseurl, headers=head) # 獲取網頁信息
html = response.text # 將網頁信息轉化為text形式是不是so easy
第二部分解析網頁才是大頭
來看代碼
Img = re.compile(r'img.*src="(.*?)"') # 正則表達式匹配圖片
soup = BeautifulSoup(html, "html.parser") # BeautifulSoup解析html
#i = 0 # 計數器初始值
data = [] # 存儲圖片超鏈接的列表
for item in soup.find_all('img', src=""): # soup.find_all對網頁中的img—src進行迭代
item = str(item) # 轉換為str類型
Picture = re.findall(Img, item) # 結合re正則表達式和BeautifulSoup, 僅返回超鏈接
for b in Picture:
data.append(b)
#i = i + 1
return data[-1]
# print(i)這里就運用到了BeautifulSoup以及re正則表達式的相關知識,需要有一定的基礎哦
下面就是第三部分:保存圖片
for m in getdata(
baseurl='https://cn.bing.com/images/search?q=%E6%83%85%E7%BB%AA%E5%9B%BE%E7%89%87&qpvt=%e6%83%85%e7%bb%aa%e5%9b%be%e7%89%87&form=IGRE&first=1&cw=418&ch=652&tsc=ImageBasicHover'):
resp = requests.get(m) #獲取網頁信息
byte = resp.content # 轉化為content二進制
print(os.getcwd()) # os庫中輸出當前的路徑
i = i + 1 # 遞增
# img_path = os.path.join(m)
with open("path{}.jpg".format(i), "wb") as f: # 文件寫入
f.write(byte)
time.sleep(0.5) # 每隔0.5秒下載一張圖片放入D://情緒圖片測試
print("第{}張圖片爬取成功!".format(i))各行代碼的解釋已經給大家寫在注釋中啦,不明白的地方可以直接私信或評論哦~
下面是完整的代碼
import re
import time
import requests
from bs4 import BeautifulSoup
import os
# m = 'https://tse2-mm.cn.bing.net/th/id/OIP-C.uihwmxDdgfK4FlCIXx-3jgHaPc?w=115&h=183&c=7&r=0&o=5&pid=1.7'
'''
resp = requests.get(m)
byte = resp.content
print(os.getcwd())
img_path = os.path.join(m)
'''
def main():
baseurl = 'https://cn.bing.com/images/search?q=%E6%83%85%E7%BB%AA%E5%9B%BE%E7%89%87&qpvt=%e6%83%85%e7%bb%aa%e5%9b%be%e7%89%87&form=IGRE&first=1&cw=418&ch=652&tsc=ImageBasicHover'
datalist = getdata(baseurl)
def getdata(baseurl):
Img = re.compile(r'img.*src="(.*?)"') # 正則表達式匹配圖片
datalist = []
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.67"}
response = requests.get(baseurl, headers=head) # 獲取網頁信息
html = response.text # 將網頁信息轉化為text形式
soup = BeautifulSoup(html, "html.parser") # BeautifulSoup解析html
# i = 0 # 計數器初始值
data = [] # 存儲圖片超鏈接的列表
for item in soup.find_all('img', src=""): # soup.find_all對網頁中的img—src進行迭代
item = str(item) # 轉換為str類型
Picture = re.findall(Img, item) # 結合re正則表達式和BeautifulSoup, 僅返回超鏈接
for b in Picture: # 遍歷列表,取最后一次結果
data.append(b)
# i = i + 1
datalist.append(data[-1])
return datalist # 返回一個包含超鏈接的新列表
# print(i)
'''
with open("img_path.jpg","wb") as f:
f.write(byte)
'''
if __name__ == '__main__':
os.chdir("D://情緒圖片測試")
main()
i = 0 # 圖片名遞增
for m in getdata(
baseurl='https://cn.bing.com/images/search?q=%E6%83%85%E7%BB%AA%E5%9B%BE%E7%89%87&qpvt=%e6%83%85%e7%bb%aa%e5%9b%be%e7%89%87&form=IGRE&first=1&cw=418&ch=652&tsc=ImageBasicHover'):
resp = requests.get(m) #獲取網頁信息
byte = resp.content # 轉化為content二進制
print(os.getcwd()) # os庫中輸出當前的路徑
i = i + 1 # 遞增
# img_path = os.path.join(m)
with open("path{}.jpg".format(i), "wb") as f: # 文件寫入
f.write(byte)
time.sleep(0.5) # 每隔0.5秒下載一張圖片放入D://情緒圖片測試
print("第{}張圖片爬取成功!".format(i))最后的運行截圖
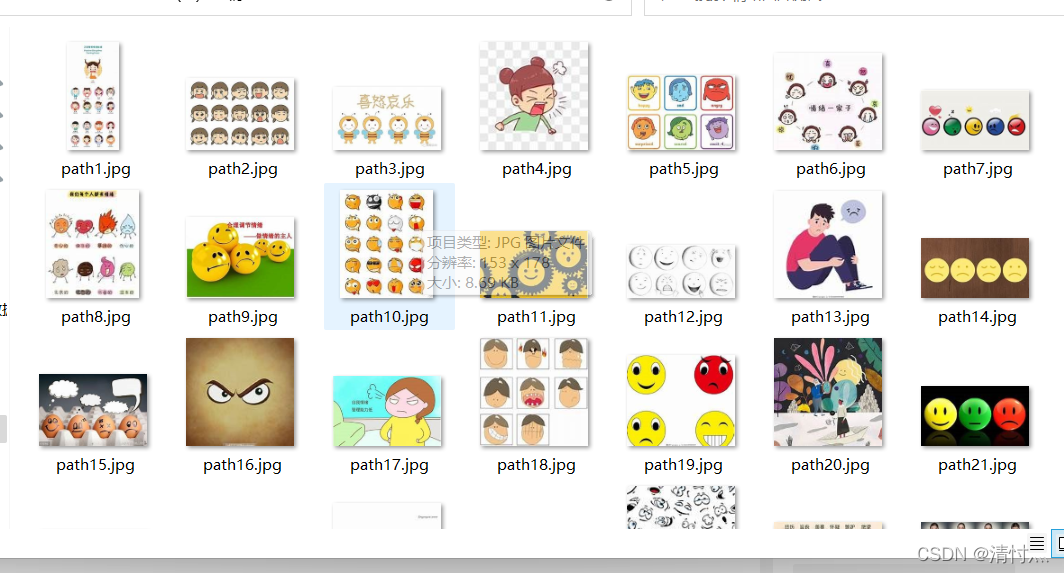
以上是“如何使用Python自動爬取圖片并保存”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





