溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關Regular Expression怎么在python項目中使用,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
一、導入re庫
python使用正則表達式要導入re庫。
import re
在re庫中。正則表達式通常被用來檢索查找、替換那些符合某個模式(規則)的文本。
二、使用正則表達式步驟
1、尋找規律;
2、使用正則符號表示規律;
3、提取信息,如果每一個字符都能匹配,則匹配成功;一旦有匹配不成功的字符則匹配失敗。
三、正則表達式中常見的基本符號
1.點號“.”
一個點號可以代替除了換行符(\n)以外的任何一個字符,包括但不限于英文字母、數字、漢字、英文標點符號和中文標點符號。
2.星號“*”
一個星號可以表示它前面的一個子表達式(普通字符、另一個或幾個正則表達式符號)0次到無限次。
3.問號“?”
問號表示它前面的子表達式0次或者1次。注意,這里的問號是英文問號。
4.反斜杠“\”
反斜杠在正則表達式里面不能單獨使用,甚至在整個Python里都不能單獨使用。反斜杠需要和其他的字符配合使用來把特殊符號變成普通符號,把普通符號變成特殊符號。如:“\n”。
5.數字“\d”
正則表達式里面使用“\d”來表示一位數字。再次強調一下,“\d”雖然是由反斜杠和字母d構成的,但是要把“\d”看成一個正則表達式符號整體。
6.小括號“()”
小括號可以把括號里面的內容提取出來。
四、常見的正則表達式舉例
1. .*?(匹配所有內容)
例如:'<title>(.*?)</title>' 將網頁的標題爬取下來。
2、\w 單詞字符[A-Za-z0-9_], "+" 匹配前一個字符1次或無限次 例如:一個人的郵箱是這樣的lixiaomei@qq.com,那么我們如何從一大堆的字符串把它提取出來呢?
pattern: \w+@\w+\.com
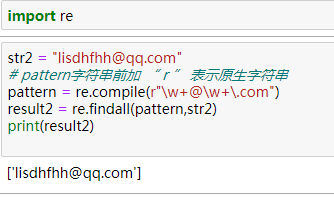
思考:若郵箱為hello123@heuet.edu.com,如何匹配?
pattern:\w+@(\w+\.)?\w+\.com
?代表了匹配0次或者1次括號分組內的匹配內容,"()"則表示被括內容是一個分組,分組序號從pattern字符串起始往后依次排列。因為是匹配0次或1次,那么就意味著括號內的部分是可有可無的,所以這個pattern就可能匹配以上兩種郵箱格式。
擴展: \w+@(\w+\.)*\w+\.com 模式就更厲害了," * " 可以匹配0次或無限次。
五、re庫的核心函數

1、compile()函數 (可有可無)
函數定義: compile(pattern, flag=0)
函數描述:編譯正則表達式pattern,然后返回一個正則表達式對象。
為什么要對pattern進行編譯呢?《Python核心編程》里面是這樣解釋的:
使用預編譯的代碼對象比直接使用字符串要快,因為解釋器在執行字符串形式的代碼前都必須把字符串編譯成代碼對象。
2、match()函數
函數定義: match(pattern, string, flag=0)
函數描述:只從字符串的最開始與pattern進行匹配,匹配成功返回匹配對象(只有一個結果),否則返回None。

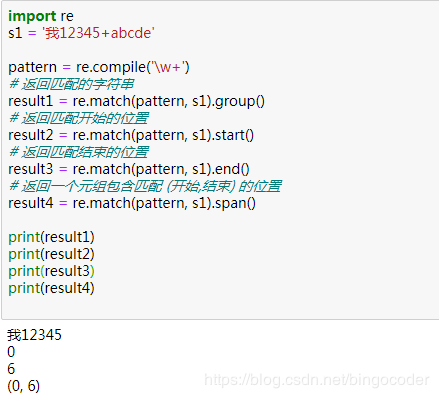
問題來了,為什么result1結果有這么多的東西啊?貌似最后一個才是要匹配的對象。這個要怎么提取出來呀?
別著急,我們現在得到的是匹配對象,需要用一定的方法提取,后面會在《匹配對象的方法》章節來解決這個問題,繼續往下看。
3、search()函數
函數定義: search(pattern, string, flag=0)
函數描述:與match()工作的方式一樣,但是search()不是從最開始匹配的,而是從任意位置查找第一次匹配的內容。如果所有的字串都沒有匹配成功,返回None,否則返回匹配對象。

4、findall()函數
函數定義: findall(pattern, string [,flags])
函數描述:查找字符串中所有出現的正則表達式模式,并返回一個匹配列表

上面同時列出了match、search、findall三個函數用法。findall與match和search不同的地方是它會返回一個所有無重復匹配的列表。如果沒找到匹配部分,就返回一個空列表。六、匹配對象的方法(提取)
以上re模塊函數的返回內容可以分為兩種:
返回匹配對象:就是上面如 <_sre.SRE_Match object; span=(0, 5), match='12345'>這樣的對象,可返回匹配對象的函數有match、search、finditer。
返回一個匹配的列表:返回列表的就是 findall。
因此匹配對象的方法只適用match、search、finditer,而不適用與findall。
常用的匹配對象方法有這兩個:group、groups、還有幾個關于位置的如 start、end、span就在代碼里描述了。
1、group方法
方法定義:group(num=0)
方法描述:返回整個的匹配對象,或者特殊編號的字組
再看下面的實例:

這里就需要用到我們之前提到的分組概念。
分組的意義在于:我們不僅僅想得到匹配的整個字符串,我們還想得到整個字符串里面的特定子字符串。如上例中,整個字符串是“我12345+abcde”,但是想得到 “abcde”,我們就可以用()括起來。因此,你可以對pattern進行任何的分組,提取你想得到的內容。
2、groups方法
方法定義:groups(default =None)
方法描述:返回一個含有所有匹配子組的元組,匹配失敗則返回空元組

七、re模塊的屬性(flag)
re模塊的常用屬性有以下幾個:
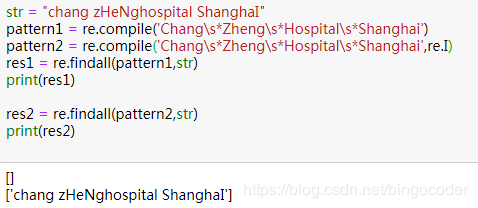
re.I: 匹配不分大小寫;(常用)
re.L: 根據使用的本地語言環境通過\w, \W, \b, \B, \s, \S實現匹配;
re.M: ^和$分別匹配目標字符串中行的起始和結尾,而不是嚴格匹配整個字符串本身的起始和結尾;
re.S: “.”(點號)通常匹配除了\n(換行符)之外的所有單個字符,該標記表示“.”(點號)能夠匹配全部字符;(常用)
re.X: 通過反斜線轉義,否則所有空格加上#(以及在該行中所有后續文字)都被忽略,除非在一個字符類中或者允許注釋并且提高可讀性;

注意:
如果我們定義了compile編譯,需要先將flag填到compile函數中,否則填到匹配函數中會報錯; 如果沒有定義compile,則可以直接在匹配函數findall中填寫flag。
附錄:
正則表達式中語法一覽表

以上就是Regular Expression怎么在python項目中使用,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





