溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關使用PyTorch怎么訓練一個圖像分類器,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
如下所示:
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
print("torch: %s" % torch.__version__)
print("tortorchvisionch: %s" % torchvision.__version__)
print("numpy: %s" % np.__version__)Out:
torch: 1.0.0 tortorchvisionch: 0.2.1 numpy: 1.15.4
數據從哪兒來?
通常來說,你可以通過一些python包來把圖像、文本、音頻和視頻數據加載為numpy array。然后將其轉換為torch.*Tensor。
圖像。Pillow、OpenCV是用得比較多的
音頻。scipy和librosa
文本。純Python或者Cython就可以完成數據加載,可以在NLTK和SpaCy找到數據
對于計算機視覺而言,我們有torchvision包,它可以用來加載一下常用數據集如Imagenet、CIFAR10、MINIST等等,也有一些常用的為圖像準備數據轉換例如torchvision.datasets和torch.utils.data.DataLoader。
這次的教程中,我們使用CIFAR10數據集,他有‘airplane', ‘automobile', ‘bird', ‘cat', ‘deer', ‘dog', ‘frog', ‘horse', ‘ship', ‘truck'這幾個類別的圖像。圖像大小都是3x32x32的。也就是說,圖像都是三通道的,每一張圖的尺寸都是32x32。

訓練一個圖像分類器
步驟如下:
使用torchvision加載、歸一化訓練集和測試集
定義卷積神經網絡
定義損失函數
使用訓練集訓練網絡
使用測試集測試網絡
1. 加載、歸一化CIFAR10
我們可以使用torchvision很輕松的完成
torchvision的數據集是基于PILImage的,數值是[0, 1],我們需要將其轉成范圍為[-1, 1]的Tensor
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=4)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=True, num_workers=4)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')Out:
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data/cifar-10-python.tar.gz Files already downloaded and verified
讓我們來看看訓練集的圖片
# 顯示一張圖片
def imshow(img):
img = img / 2 + 0.5 # 逆歸一化
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# 任意地拿到一些圖片
dataiter = iter(trainloader)
images, labels = dataiter.next()
# 顯示圖片
imshow(torchvision.utils.make_grid(images))
# 顯示類標
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))Out:
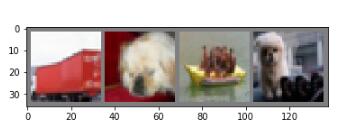
truck dog ship dog
2. 定義卷積神經網絡
可以直接復制神經網絡的代碼,修改里面的幾層即可。
import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x net = Net()
3. 定義損失函數和優化器
使用多分類交叉熵損失函數,和帶有momentum的SGD作為優化器
import torch.optim as optim criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=1e-3, momentum=0.9)
4. 訓練網絡
我們直接使用循環語句遍歷數據集即可完成訓練
nums_epoch = 2
for epoch in range(nums_epoch):
_loss = 0.0
for i, (inputs, labels) in enumerate(trainloader, 0):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_loss += loss.item()
if i % 2000 == 1999: # 每2000步打印一次損失值
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, _loss / 2000))
_loss = 0.0
print('Finished Training')Out:
[1, 2000] loss: 1.178 [1, 4000] loss: 1.200 [1, 6000] loss: 1.168 [1, 8000] loss: 1.175 [1, 10000] loss: 1.185 [1, 12000] loss: 1.165 [2, 2000] loss: 1.073 [2, 4000] loss: 1.066 [2, 6000] loss: 1.100 [2, 8000] loss: 1.107 [2, 10000] loss: 1.083 [2, 12000] loss: 1.103 Finished Training
5. 測試網絡
這個網絡已經訓練了兩個epoch,我們現在來看看這個網絡是不是學到了一些什么東西。
我們讓這個神經網絡預測幾張圖片,看看它的答案與真實答案的差別。
下面我們選取一些測試數據集中的數據,看看他們的真實標簽。
# 展示測試數據集
dataiter = iter(testloader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print('GraoundTruth: ', ' '.join(['%5s' % classes[labels[j]] for j in range(4)]))Out:

GraoundTruth: ship ship deer ship
接著我們讓神經網絡來給出預測標簽
神經網絡的輸出是10個信號值,信號值最高的那個神經元表示整個網絡的預測值,所以我們需要拿到信號最強的那個節點的索引值
# 展示預測值
outputs = net(images)
_, predicted = torch.max(outputs, 1)
print('Predicted: ', ' '.join(['%5s' % classes[predicted[j]] for j in range(4)]))Out:
Predicted: car ship horse ship
下面我們對整個測試集做一次評估:
# 評估測試數據集
correct, total = 0, 0
with torch.no_grad():
for images, labels in testloader:
outputs = net(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (labels == predicted).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))Out:
Accuracy of the network on the 10000 test images: 58 %
整個結果比隨機猜要好得多(隨機猜是10%的概率)。看來我們的神經網絡還是學到了點東西。
下面我們來看看它在哪一個類別的分類上做得最好:
# 按類標評估
n_classes = len(classes)
class_correct, class_total = [0]*n_classes, [0]* n_classes
with torch.no_grad():
for images, labels in testloader:
outputs = net(images)
_, predicted = torch.max(outputs, 1)
is_correct = (labels == predicted).squeeze()
for i in range(len(labels)):
label = labels[i]
class_total[label] += 1
class_correct[label] += is_correct[i].item()
for i in range(n_classes):
print('Accuracy of %5s: %.2f %%' % (
classes[i], 100.0 * class_correct[i] / class_total[i]
))Out:
Accuracy of plane: 67.00 % Accuracy of car: 71.50 % Accuracy of bird: 55.20 % Accuracy of cat: 45.60 % Accuracy of deer: 38.20 % Accuracy of dog: 47.00 % Accuracy of frog: 78.80 % Accuracy of horse: 55.90 % Accuracy of ship: 72.70 % Accuracy of truck: 57.50 %
在GPU上訓練
就像把Tensor從CPU轉移到GPU一樣,神經網絡也可以轉移到GPU上
首先需要檢查是否有可用的GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 假設我們在支持CUDA的機器上,我們可以打印出CUDA設備:
print(device)Out:
cuda:0
我們假設device已經是CUDA設備了
下面命令將遞歸的將所有模塊和參數、緩存轉移到CUDA設備上去
net.to(device)
Out:
Net( (conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1)) (pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1)) (fc1): Linear(in_features=400, out_features=120, bias=True) (fc2): Linear(in_features=120, out_features=84, bias=True) (fc3): Linear(in_features=84, out_features=10, bias=True) )
注意,在訓練過程中的傳入輸入數據時,也需要轉移到GPU上
并且,需要重新實例化優化器,否則會報錯
inputs, labels = inputs.to(device), labels.to(device)
關于使用PyTorch怎么訓練一個圖像分類器就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





