溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關Python中字符編碼轉碼之GBK,UTF8互轉的示例分析的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
1、須知:
在python 2中默認編碼是 ASCII,而在python 3中默認編碼是 unicode
unicode 分為utf-32 (占4個字節),utf-16(占兩個字節),utf-8(占1-4個字節),所以utf-16 是最常用的unicode版本,但是在文件里存的還是utf-8,因為utf8省空間
在python 3,encode編碼的同時會把stringl變成bytes類型,decode解碼的同時會把bytes類型變成string類型
在unicode編碼中 1個中文字符=2個字節,1個英文字符 = 1個字節,切記:ASCII是不能存中文字符的
utf-8是可變長字符編碼,它是unicode的優化,所有的英文字符依然按ASCII形式存儲,所有的中文字符統一是3個字節
unicode包含了所有國家的字符編碼,不同字符編碼之間的轉換都需要經過unicode的過程
python本身的默認編碼是utf-8
2、py2中的編碼和轉碼的過程,如圖:
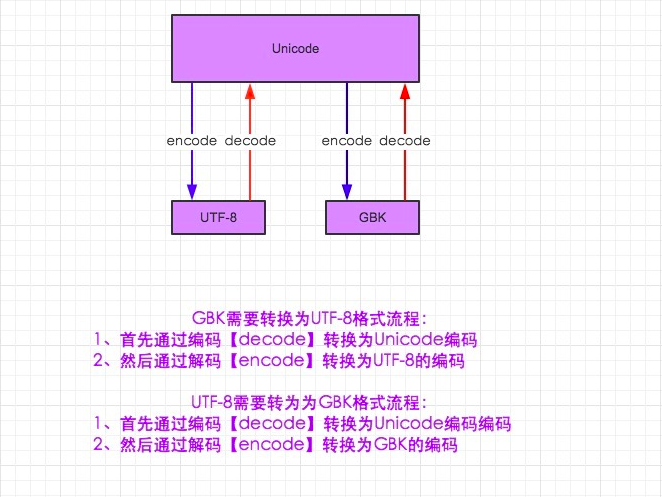
注:因為unicode是中間編碼,任何字符編碼之前的轉換都必須解碼成unicode,在編碼成需要轉的字符編碼
1、py2字符編碼的轉換,代碼如下:
#! /usr/bin/env python
# -*- coding:utf-8 -*-
# __auther__ == luoahong
s = "我是學員"
#utf-8解碼成unicode編碼
s_to_unicode = s.decode("utf-8")
print("--------s_to_unicode-----")
print(s_to_unicode)
#然后unicode再編碼成gbk
s_to_gbk = s_to_unicode.encode("gbk")
print("-----s_to_gbk------")
print(s_to_gbk)
#gbk解碼成unicode再編碼成utf-8
gbk_to_utf8 = s_to_gbk.decode("gbk").encode("utf-8")
print("------gbk_to_utf8-----")
print(gbk_to_utf8)
#輸出
--------s_to_unicode-----
我是學員
-----s_to_gbk------
??????
------gbk_to_utf8-----
我是學員注:以上這種情況適合字符是非unicode編碼請款下,但是如果字符編碼已經是Unicode的了咋辦呢?廣告回來,更加精彩。。。。。
2、字符編碼已經是unicode情況下,代碼如下:
#! /usr/bin/env python
# -*- coding:utf-8 -*-
# __auther__ == luoahong
#u代碼字符編碼是unicode
s = u'你好'
#已經是unicode,所以這邊直接是編碼成gbk
s_to_gbk = s.encode("gbk")
print("----s_to_gbk----")
print(s_to_gbk)
#這邊再解碼成unicode然后再編碼成utf-8
gbk_to_utf8 = s_to_gbk.decode("gbk").encode("utf-8")
print("-----gbk_to_utf8---")
print(gbk_to_utf8)
#輸出
----s_to_gbk----
???
-----gbk_to_utf8---
你好注:在python2中,在文件的開頭指定字符編碼,是要告訴解釋器我現在的字符編碼使用的是utf-8,那我在打印的中文時候,那么在utf-8中包含中文字符,那么可以打印出來。那么如果你不制定字符編碼,默認使用系統編碼,如果你的系統編碼是ASCII,那么就會報錯,因為ASCII不能存中文字符。
3、py3的字符編碼轉換
在須知中已經說到python 3的編碼,默認是unicode,所以字符編碼之間的轉換不需要decode過程,直接encode即可,代碼如下:
#! /usr/bin/env python
# __auther__ == luoahong
#無需聲明字符編碼,當然你聲明也不會報錯
s = '你好'
# 字符串s已經是unicode編碼,無需decode,直接encode
s_to_gbk = s.encode("gbk")
print("----s_to_gbk----")
print(s_to_gbk)
#這邊還是一樣,gbk需要先解碼成unicode,再編碼成utf-8
gbk_to_utf8 = s_to_gbk.decode("gbk").encode("utf-8")
print("-----gbk_to_utf8---")
print(gbk_to_utf8)
#解碼成unicode字符編碼
utf8_decode = gbk_to_utf8.decode("utf-8")
print("-------utf8_decode----")
print(utf8_decode)
#輸出
----s_to_gbk----
b'\xc4\xe3\xba\xc3'
-----gbk_to_utf8---
b'\xe4\xbd\xa0\xe5\xa5\xbd'
-------utf8_decode----
你好注:在python 3,encode編碼的同時會把stringl變成bytes類型,decode解碼的同時會把bytes類型變成string類型,所以你就不難看出encode后的把它變成了一個bytes類型的數據。還有需要特別注意的是:不管是否在python 3的文件開頭申明字符編碼,只能表示,這個python文件是這個字符編碼,文件中的字符串還是unicode。
感謝各位的閱讀!關于“Python中字符編碼轉碼之GBK,UTF8互轉的示例分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





