溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關Pytorch中自動求導函數backward()所需參數的含義是什么的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
首先,如果out.backward()中的out是一個標量的話(相當于一個神經網絡有一個樣本,這個樣本有兩個屬性,神經網絡有一個輸出)那么此時我的backward函數是不需要輸入任何參數的。
import torch
from torch.autograd import Variable
a = Variable(torch.Tensor([2,3]),requires_grad=True)
b = a + 3
c = b * 3
out = c.mean()
out.backward()
print('input:')
print(a.data)
print('output:')
print(out.data.item())
print('input gradients are:')
print(a.grad)運行結果:
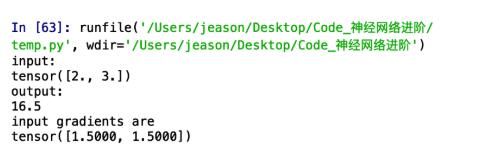
不難看出,我們構建了這樣的一個函數:
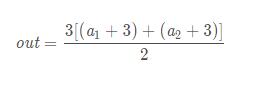
所以其求導也很容易看出:
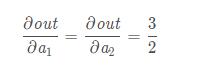
這是對其進行標量自動求導的結果.
對向量自動求導
如果out.backward()中的out是一個向量(或者理解成1xN的矩陣)的話,我們對向量進行自動求導,看看會發生什么?
先構建這樣的一個模型(相當于一個神經網絡有一個樣本,這個樣本有兩個屬性,神經網絡有兩個輸出):
import torch
from torch.autograd import Variable
a = Variable(torch.Tensor([[2.,4.]]),requires_grad=True)
b = torch.zeros(1,2)
b[0,0] = a[0,0] ** 2
b[0,1] = a[0,1] ** 3
out = 2 * b
#其參數要傳入和out維度一樣的矩陣
out.backward(torch.FloatTensor([[1.,1.]]))
print('input:')
print(a.data)
print('output:')
print(out.data)
print('input gradients are:')
print(a.grad)模型也很簡單,不難看出out求導出來的雅克比應該是:
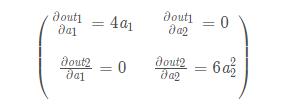
因為a1 = 2,a2 = 4,所以上面的矩陣應該是:
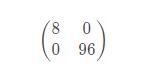
運行的結果:

嗯,的確是8和96,但是仔細想一想,和咱們想要的雅克比矩陣的形式也不一樣啊。難道是backward自動把0給省略了?
咱們繼續試試,這次在上一個模型的基礎上進行小修改,如下:
import torch
from torch.autograd import Variable
a = Variable(torch.Tensor([[2.,4.]]),requires_grad=True)
b = torch.zeros(1,2)
b[0,0] = a[0,0] ** 2 + a[0,1]
b[0,1] = a[0,1] ** 3 + a[0,0]
out = 2 * b
#其參數要傳入和out維度一樣的矩陣
out.backward(torch.FloatTensor([[1.,1.]]))
print('input:')
print(a.data)
print('output:')
print(out.data)
print('input gradients are:')
print(a.grad)可以看出這個模型的雅克比應該是:
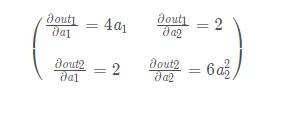
運行一下:

等等,什么鬼?正常來說不應該是
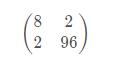
么?我是誰?我再哪?為什么就給我2個數,而且是 8 + 2 = 10 ,96 + 2 = 98 。難道都是加的 2 ?想一想,剛才咱們backward中傳的參數是 [ [ 1 , 1 ] ],難道安裝這個關系對應求和了?咱們換個參數來試一試,程序中只更改傳入的參數為[ [ 1 , 2 ] ]:
import torch
from torch.autograd import Variable
a = Variable(torch.Tensor([[2.,4.]]),requires_grad=True)
b = torch.zeros(1,2)
b[0,0] = a[0,0] ** 2 + a[0,1]
b[0,1] = a[0,1] ** 3 + a[0,0]
out = 2 * b
#其參數要傳入和out維度一樣的矩陣
out.backward(torch.FloatTensor([[1.,2.]]))
print('input:')
print(a.data)
print('output:')
print(out.data)
print('input gradients are:')
print(a.grad)
嗯,這回可以理解了,我們傳入的參數,是對原來模型正常求導出來的雅克比矩陣進行線性操作,可以把我們傳進的參數(設為arg)看成一個列向量,那么我們得到的結果就是:
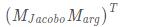
在這個題目中,我們得到的實際是:
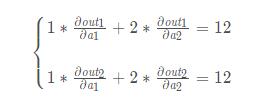
看起來一切完美的解釋了,但是就在我剛剛打字的一刻,我意識到官方文檔中說k.backward()傳入的參數應該和k具有相同的維度,所以如果按上述去解釋是解釋不通的。哪里出問題了呢?
仔細看了一下,原來是這樣的:在對雅克比矩陣進行線性操作的時候,應該把我們傳進的參數(設為arg)看成一個行向量(不是列向量),那么我們得到的結果就是:
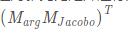
也就是:
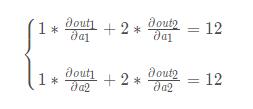
這回我們就解釋的通了。
現在我們來輸出一下雅克比矩陣吧,為了不引起歧義,我們讓雅克比矩陣的每個數值都不一樣(一開始分析錯了就是因為雅克比矩陣中有相同的數據),所以模型小改動如下:
import torch
from torch.autograd import Variable
a = Variable(torch.Tensor([[2.,4.]]),requires_grad=True)
b = torch.zeros(1,2)
b[0,0] = a[0,0] ** 2 + a[0,1]
b[0,1] = a[0,1] ** 3 + a[0,0] * 2
out = 2 * b
#其參數要傳入和out維度一樣的矩陣
out.backward(torch.FloatTensor([[1,0]]),retain_graph=True)
A_temp = copy.deepcopy(a.grad)
a.grad.zero_()
out.backward(torch.FloatTensor([[0,1]]))
B_temp = a.grad
print('jacobian matrix is:')
print(torch.cat( (A_temp,B_temp),0 ))如果沒問題的話咱們的雅克比矩陣應該是 [ [ 8 , 2 ] , [ 4 , 96 ] ]
好了,下面是見證奇跡的時刻了,不要眨眼睛奧,千萬不要眨眼睛… 3 2 1 砰…
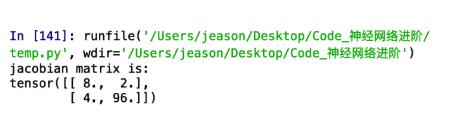
好了,現在總結一下:因為經過了復雜的神經網絡之后,out中每個數值都是由很多輸入樣本的屬性(也就是輸入數據)線性或者非線性組合而成的,那么out中的每個數值和輸入數據的每個數值都有關聯,也就是說【out】中的每個數都可以對【a】中每個數求導,那么我們backward()的參數[k1,k2,k3…kn]的含義就是:
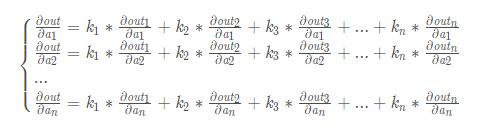
也可以理解成每個out分量對an求導時的權重。
對矩陣自動求導
現在,如果out是一個矩陣呢?
下面的例子也可以理解為:相當于一個神經網絡有兩個樣本,每個樣本有兩個屬性,神經網絡有兩個輸出。
import torch
from torch.autograd import Variable
from torch import nn
a = Variable(torch.FloatTensor([[2,3],[1,2]]),requires_grad=True)
w = Variable( torch.zeros(2,1),requires_grad=True )
out = torch.mm(a,w)
out.backward(torch.FloatTensor([[1.],[1.]]),retain_graph=True)
print("gradients are:{}".format(w.grad.data))如果前面的例子理解了,那么這個也很好理解,backward輸入的參數k是一個2x1的矩陣,2代表的就是樣本數量,就是在前面的基礎上,再對每個樣本進行加權求和。結果是:

感謝各位的閱讀!關于“Pytorch中自動求導函數backward()所需參數的含義是什么”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





