溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關使用PyTorch怎么讀取數據,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
pandas 用于方便操作含有字符串的表文件,如csv
zipfile python內置的文件解壓包
cv2 用于圖片處理的模塊,讀入的圖片模塊為BGR,N H W C
torchvision.transforms 用于圖片的操作庫,比如隨機裁剪、縮放、模糊等等,可用于數據的增廣,但也不僅限于內置的圖片操作,也可以自行進行圖片數據的操作,這章也會講解
torch.utils.data.Dataset torch內置的對象類型
torch.utils.data.DataLoader 和Dataset配合使用可以實現數據的加速讀取和隨機讀取等等功能
import zipfile # 解壓 import pandas as pd # 操作數據 import os # 操作文件或文件夾 import cv2 # 圖像操作庫 import matplotlib.pyplot as plt # 圖像展示庫 from torch.utils.data import Dataset # PyTorch內置對象 from torchvision import transforms # 圖像增廣轉換庫 PyTorch內置 import torch
數據下載到此處
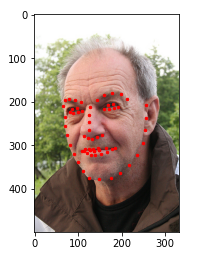
我們先初步編寫一個腳本來實現圖片的展示
# 解壓文件到指定目錄 def unzip_file(root_path, filename): full_path = os.path.join(root_path, filename) file = zipfile.ZipFile(full_path) file.extractall(root_path) unzip_file(root_path, zip_filename) # 讀入csv文件 face_landmarks = pd.read_csv(os.path.join(extract_path, csv_filename)) # pandas讀出的數據如想要操作索引 使用iloc image_name = face_landmarks.iloc[:,0] landmarks = face_landmarks.iloc[:,1:] # 展示 def show_face(extract_path, image_file, face_landmark): plt.imshow(plt.imread(os.path.join(extract_path, image_file)), cmap='gray') point_x = face_landmark.to_numpy()[0::2] point_y = face_landmark.to_numpy()[1::2] plt.scatter(point_x, point_y, c='r', s=6) show_face(extract_path, image_name.iloc[1], landmarks.iloc[1])
實現MyDataset
使用內置庫是我們的代碼更加的規范,并且可讀性也大大增加
繼承Dataset,需要我們實現的有兩個地方:
實現__len__返回數據的長度,實例化調用len()時返回
__getitem__給定數據的索引返回對應索引的數據如:a[0]
transform 數據的額外操作時調用
class FaceDataset(Dataset):
def __init__(self, extract_path, csv_filename, transform=None):
super(FaceDataset, self).__init__()
self.extract_path = extract_path
self.csv_filename = csv_filename
self.transform = transform
self.face_landmarks = pd.read_csv(os.path.join(extract_path, csv_filename))
def __len__(self):
return len(self.face_landmarks)
def __getitem__(self, idx):
image_name = self.face_landmarks.iloc[idx,0]
landmarks = self.face_landmarks.iloc[idx,1:].astype('float32')
point_x = landmarks.to_numpy()[0::2]
point_y = landmarks.to_numpy()[1::2]
image = plt.imread(os.path.join(self.extract_path, image_name))
sample = {'image':image, 'point_x':point_x, 'point_y':point_y}
if self.transform is not None:
sample = self.transform(sample)
return sample測試功能是否正常
face_dataset = FaceDataset(extract_path, csv_filename)
sample = face_dataset[0]
plt.imshow(sample['image'], cmap='gray')
plt.scatter(sample['point_x'], sample['point_y'], c='r', s=2)
plt.title('face')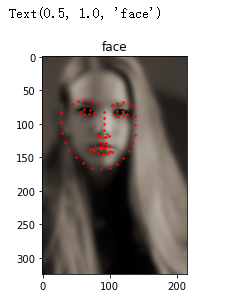
內置的在torchvision.transforms模塊下,由于我們的數據結構不能滿足內置模塊的要求,我們就必須自己實現
圖片的縮放,由于縮放后人臉的標注位置也應該發生對應的變化,所以要自己實現對應的變化
class Rescale(object):
def __init__(self, out_size):
assert isinstance(out_size,tuple) or isinstance(out_size,int), 'out size isinstance int or tuple'
self.out_size = out_size
def __call__(self, sample):
image, point_x, point_y = sample['image'], sample['point_x'], sample['point_y']
new_h, new_w = self.out_size if isinstance(self.out_size,tuple) else (self.out_size, self.out_size)
new_image = cv2.resize(image,(new_w, new_h))
h, w = image.shape[0:2]
new_y = new_h / h * point_y
new_x = new_w / w * point_x
return {'image':new_image, 'point_x':new_x, 'point_y':new_y}將數據轉換為torch認識的數據格式因此,就必須轉換為tensor注意: cv2和matplotlib讀出的圖片默認的shape為N H W C,而torch默認接受的是N C H W因此使用tanspose轉換維度,torch轉換多維度使用permute
class ToTensor(object):
def __call__(self, sample):
image, point_x, point_y = sample['image'], sample['point_x'], sample['point_y']
new_image = image.transpose((2,0,1))
return {'image':torch.from_numpy(new_image), 'point_x':torch.from_numpy(point_x), 'point_y':torch.from_numpy(point_y)}測試
transform = transforms.Compose([Rescale((1024, 512)), ToTensor()])
face_dataset = FaceDataset(extract_path, csv_filename, transform=transform)
sample = face_dataset[0]
plt.imshow(sample['image'].permute((1,2,0)), cmap='gray')
plt.scatter(sample['point_x'], sample['point_y'], c='r', s=2)
plt.title('face')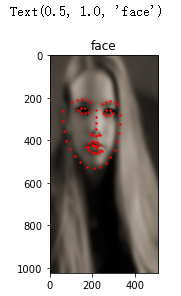
data_loader = DataLoader(face_dataset, batch_size=4, shuffle=True, num_workers=0) for i in data_loader: print(i['image'].shape) break
torch.Size([4, 3, 1024, 512])
注意: windows環境盡量不使用num_workers會發生報錯
以上就是使用PyTorch怎么讀取數據,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





