溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編這次要給大家分享的是詳解Python爬蟲谷歌Chrome F12抓包過程,文章內容豐富,感興趣的小伙伴可以來了解一下,希望大家閱讀完這篇文章之后能夠有所收獲。
瀏覽器打開網頁的過程就是爬蟲獲取數據的過程,兩者是一樣一樣的。瀏覽器渲染的網頁是豐富多彩的數據集合,而爬蟲得到的是網頁的源代碼htm有時候,我們不能在網頁的html代碼里面找到想要的數據,但是瀏覽器打開的網頁上面卻有這些數據。這就是瀏覽器通過ajax技術異步加載(偷偷下載)了這些數據。
大家禁不住要問:那么該如何看到瀏覽器偷偷下載的那些數據呢?
答案就是谷歌Chrome瀏覽器的F12快捷鍵,也可以通過鼠標右鍵菜單“檢查”(Inspect)打開Chrome自帶的開發者工具,開發者工具會出現在瀏覽器網頁的左側或者是下面(可調整),它的樣子就是這樣的:
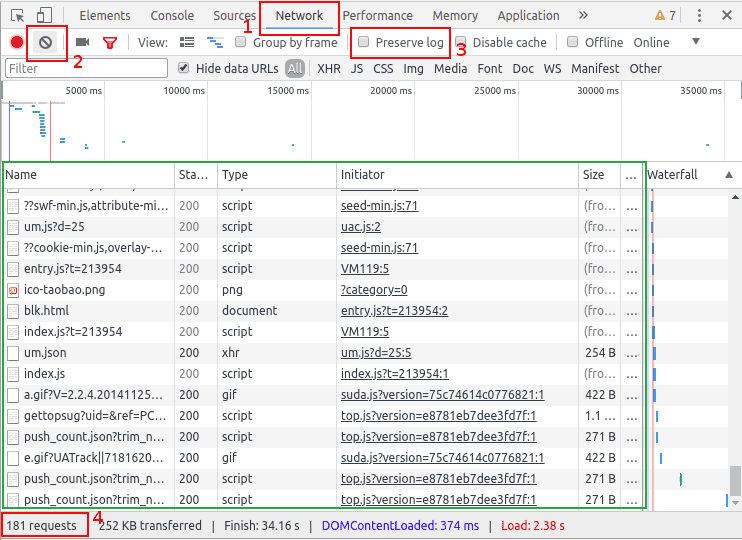
讓我們簡單了解一下它如何使用:
谷歌Chrome抓包:1. 最上面一行菜單
左上角箭頭 用來點擊查看網頁的元素
第二個手機、平板圖標是用來模擬移動端顯示網頁
Elements 查看渲染后的網頁標簽元素
提醒 是渲染后(包括異步加載的圖片、數據等)的完整網頁的html,不是最初下載的那個html。
Console 查看JavaScript的console log信息,寫網頁時比較有用
Sources 顯示網頁源碼、CSS、JavaScript代碼
Network 查看所有加載的請求,對爬蟲很有幫助
后面的暫且不管。
谷歌Chrome抓包:2. 重要區域
圖中紅框的兩個按鈕比較有用,編號為2的是清空請求記錄;編號3的是保持記錄,這在網頁有重定向的時候很有用
圖中綠色區域就是加載完整個網頁,瀏覽器的全部請求記錄,包括網址、狀態、類型等。寫爬蟲時,我們就要在這里尋找線索,提煉金礦。
最下面編號為4的紅框顯示了加載這個網頁,一共請求了181次,數量是多么地驚人,讓人不禁心疼七瀏覽器來。
點擊一條請求的網址,右側就會出現新的窗口顯示該條請求的相信信息:
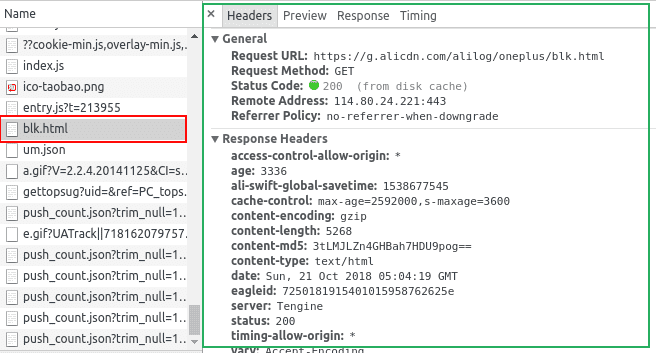
圖中左邊紅框就是點擊的請求網址;綠框就是詳情窗口。
詳情窗口包括,Headers(請求頭)、Preview(預覽響應)、Response(服務器響應內容)和Timing(耗時)。
Preview、Response 幫助我們查看該條請求是不是有爬蟲想要的數據;
Headers幫助我們在爬蟲中重建http請求,以便爬蟲得到和瀏覽器一樣的數據。
了解和熟練使用Chrome的開發者工具,大家就如虎添翼可以順利寫出自己的爬蟲啦。
看完這篇關于詳解Python爬蟲谷歌Chrome F12抓包過程的文章,如果覺得文章內容寫得不錯的話,可以把它分享出去給更多人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





