溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
方法: 使用urlencode函數
urllib.request.urlopen()
import urllib.request
import urllib.parse
url = 'https://www.sogou.com/web?'
#將get請求中url攜帶的參數封裝至字典中
param = {
'query':'周杰倫'
}
#對url中的非ascii進行編碼
param = urllib.parse.urlencode(param)
#將編碼后的數據值拼接回url中
url += param
response = urllib.request.urlopen(url=url)
data = response.read()
with open('./周杰倫1.html','wb') as fp:
fp.write(data)
print('寫入文件完畢')
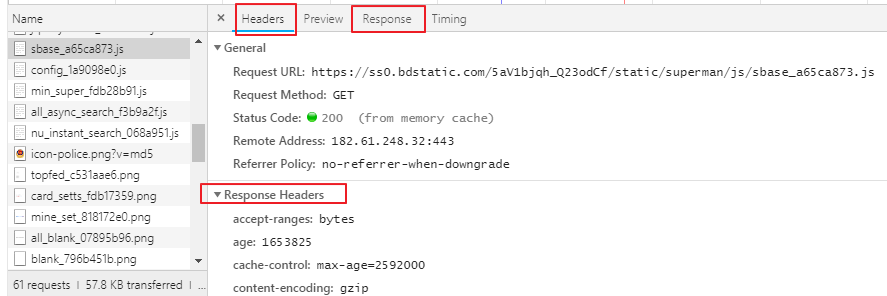
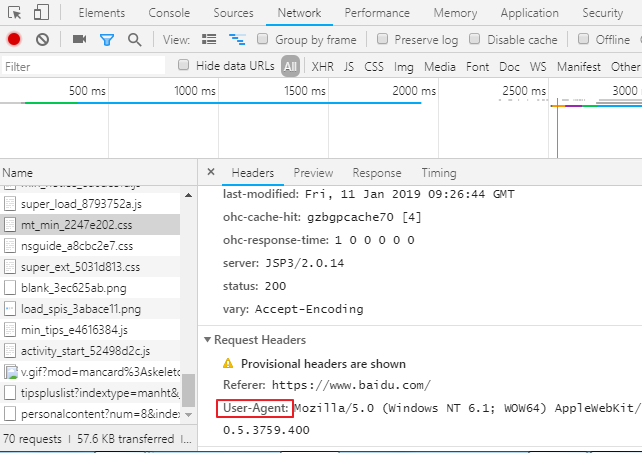
開發者工具瀏覽器按F12或者右鍵按檢查 ,有個抓包工具network,刷新頁面,可以看到網頁資源,可以看到請求頭信息,UA
在抓包工具點擊任意請求,可以看到所有請求信息,向應信息,
主要用到headers,response,response headers存放響應頭信息,request headers 存放請求信息
反爬出機制:網站會檢查請求的UA,如果發現UA是爬蟲程序,會拒絕提供網站頁面數據。
如果網站檢查發現請求UA是基于某一款瀏覽器標識(瀏覽器發起的請求),網站會認為請求是正常請求,會把頁面數據響應信息給客戶端
User-Agent(UA):請求載體的身份標識
反反爬蟲機制:
偽造爬蟲程序的請求的UA,把爬蟲程序的請求UA偽造成谷歌標識,火狐標識
通過自定義請求對象,用于偽裝爬蟲程序請求的身份。
User-Agent參數,簡稱為UA,該參數的作用是用于表明本次請求載體的身份標識。如果我們通過瀏覽器發起的請求,則該請求的載體為當前瀏覽器,則UA參數的值表明的是當前瀏覽器的身份標識表示的一串數據。
如果我們使用爬蟲程序發起的一個請求,則該請求的載體為爬蟲程序,那么該請求的UA為爬蟲程序的身份標識表示的一串數據。
有些網站會通過辨別請求的UA來判別該請求的載體是否為爬蟲程序,如果為爬蟲程序,則不會給該請求返回響應,那么我們的爬蟲程序則也無法通過請求爬取到該網站中的數據值,這也是反爬蟲的一種初級技術手段。那么為了防止該問題的出現,則我們可以給爬蟲程序的UA進行偽裝,偽裝成某款瀏覽器的身份標識。
上述案例中,我們是通過request模塊中的urlopen發起的請求,該請求對象為urllib中內置的默認請求對象,我們無法對其進行UA進行更改操作。urllib還為我們提供了一種自定義請求對象的方式,我們可以通過自定義請求對象的方式,給該請求對象中的UA進行偽裝(更改)操作。
自定義請求頭信息字典可以添加谷歌瀏覽器的UA標識,自定義請求對象來偽裝成谷歌UA
1.封裝自定義的請求頭信息的字典,
2.注意:在headers字典中可以封裝任意的請求頭信息
3.將瀏覽器的UA數據獲取,封裝到一個字典中。該UA值可以通過抓包工具或者瀏覽器自帶的開發者工具中獲取某請求,
從中獲取UA的值
import urllib.request
import urllib.parse
url = 'https://www.sogou.com/web?query='
# url的特性:url不可以存在非ASCII編碼字符數據
word = urllib.parse.quote("周杰倫")
# 將編碼后的數據值拼接回url中
url = url+word # 有效url
# 發請求之前對請求的UA進行偽造,偽造完再對請求url發起請求
# UA偽造
# 1 子制定一個請求對象,headers是請求頭信息,字典形式
# 封裝自定義的請求頭信息的字典,
# 注意:在headers字典中可以封裝任意的請求頭信息
headers = {
# 存儲任意的請求頭信息
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
# 該請求對象的UA進行了成功的偽裝
request = urllib.request.Request(url=url, headers=headers)
# 2.針對自定義請求對象發起請求
response = urllib.request.urlopen(request)
# 3.獲取響應對象中的頁面數據:read函數可以獲取響應對象中存儲的頁面數據(byte類型的數據值)
page_text = response.read()
# 4.持久化存儲:將爬取的頁面數據寫入文件進行保存
with open("周杰倫.html","wb") as f:
f.write(page_text)
print("寫入數據成功")
這樣就可以突破網站的反爬機制
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





