溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如果這是第二次看到我的文章,歡迎文末掃碼訂閱我喲~
本文長度為4069字,建議閱讀11分鐘。
也許你對降級已經有了一些認識,認真看完,我想這篇文章可能會給你帶來一些新的收獲~
前面兩篇我們已經聊過了「熔斷」(如何在到處是“雷”的系統中「明哲保身」?這是第一招)和「限流」(想通關「限流」?只要這一篇),這次我們聊的就是「高可用三劍客」中剩下的「降級」。
不知道這里有多少小伙伴接觸過阿里的開放平臺。在每次大促的時候,阿里都會發布這樣的一個公告。
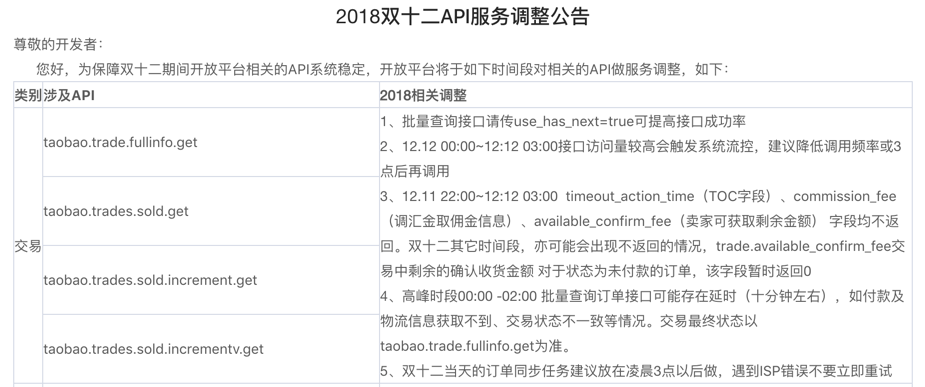
▲2018年雙12的公告內容
這些調整就是「降級」工作,目的是為了騰出更多資源給核心程序使用,以最大化保證核心業務的可用性,因此就必然需要對非核心業務執行一些降級處理。
降級的目的用一句話概括就是:將有限的資源效益最大化。
什么樣才是效益最大化呢?就像下面這個例子:
z哥有3個東西要買,一個3000的A、一個700的B、一個1200的C,對z哥的重要程度A>B>C。但此時,z哥手里只有3000塊錢,你說z哥該怎么選才能把錢花的最多?必然是選A咯。
根據28原則,我們知道一個系統80%的效益是由最核心的20%的功能產出的。剩下的20%效益需要投入80%的資源才能達到。
這就意味著,假如系統平時需要花費100%資源做100%的事情,如果現在訪問量增多3倍的話必定扛不住(需要300%的資源)。那么,在不增加資源的情況下,我希望系統不能宕機,依舊能正常工作,必然需要讓出那解決剩下20%問題的80%資源。如此一來,理論上這100%的資源就可以支撐原先5倍的訪問量。副作用是功能的完整性上受損80%。
當然,在實際的場景中不會降級掉80%的功能這么夸張,畢竟還得為用戶的體驗考慮。
舉個電商場景典型的例子,在大促的時候,最重要的是什么?轉化咯~賺錢咯~ 那么這個時候如果說「評論」功能占用了很多資源,你會怎么處理?其實我們可以選擇臨時關閉提交評論入口、關閉翻頁功能等等,讓下單的過程有更多的資源來處理。
常見的降級方案表現形式無非以下三種類型。
為了減少對「冷數據」的獲取,禁用列表的翻頁功能。
為了放緩流量進入的速率,增加驗證碼機制。
為了減少“大查詢”浪費過多的資源,提高篩選條件要求(禁用模糊查詢、部分條件必選等)。
用通用的靜態化數據代替「千人千面」的動態數據。
甚至更簡單粗暴的,直接掛一個頁面顯示「XX功能在XX時間內暫時關閉」。
此類方案雖然或多或少降低了用戶的體驗,但是在某些時期,有些功能并不是「剛需」。以此換取對系統的保護是筆劃算的買賣。
還有一些功能是「防御性」的,如果愿意冒險“裸奔”一段時間也會帶來可觀的資源節約。
比如通過臨時關閉「風控」、取消部分「條件是否滿足」的判斷(如,將積分商品添加到購物車時判斷積分夠不夠)等操作,減少這類「驗證」動作以釋放更多的資源。
又或者將原本info、warning級別的日志采集關閉或者直接不采集,僅采集error以及fault級別的日志。
一個事件發生后立馬看到效果是一個很符合「思維慣性」的東西。但是根據之前的一篇文章(分布式系統關注點——數據一致性(上篇))我們知道,時效性這個東西一旦涉及到網絡傳輸是不存在真正的“實時”的。但是為了盡可能快的將處理后的結果反映到相關的地方,你會做很多努力。比如庫存的及時同步。
如果在特殊時期,能夠臨時降低對時效性的要求(3秒內生效變成30秒生效),也是一個有不錯收益的方案。
比如原先在商品頁會顯示當前還剩多少個庫存,現在可以調整成固定顯示「有貨」。
以及將一些原本就是異步進行的操作,處理效率放緩,甚至暫緩一段時間。如,送積分、送券等等。
講了這么多,降級具體實施起來要怎么做呢?
主要分為兩個環節:定級定序和降級實現。
就像前面的例子中提到的一樣,首先我們得先確定每個功能的「重要程度」,它決定了在什么情況下可以拋棄它以保證剩下的功能可用。
類似于給日志定義級別一樣,比如我們可以定義1~5五個級別,1的級別最高,要拼死保護。5的級別最低最先可以被降級掉。
一旦當系統壓力過大的時候,先把級別5的功能降級掉。如果還不夠再降級別4、級別3,以此類推。
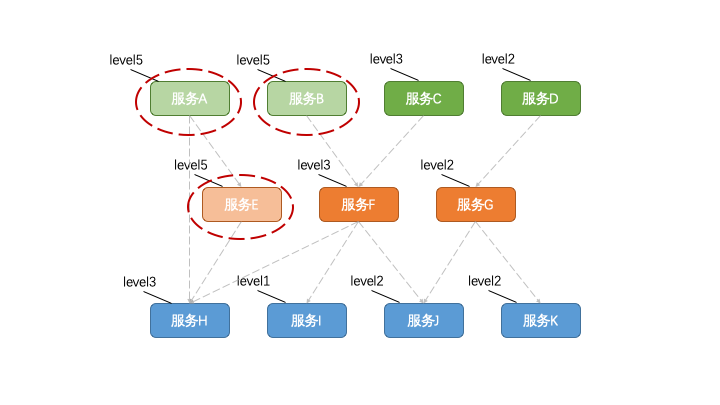
但實際上光這樣定級還不夠,比如被定義為4級的有100個功能,需要降級的時候是一起降級嗎?很明顯粒度太粗了。
如果「定級」好比是橫著切蛋糕的話,「定序」就是再來豎著切。

我們也可以來定義一些數字,比如序號1~9,序號9最先被降級。
然后,你可以以每個程序所支撐的上游程序/功能數量作為一個參考標準。比如,同樣是級別5的程序,一個支撐了上游5個功能,一個支撐了10個功能,很顯然前者的序號應該更大,更先被降級。
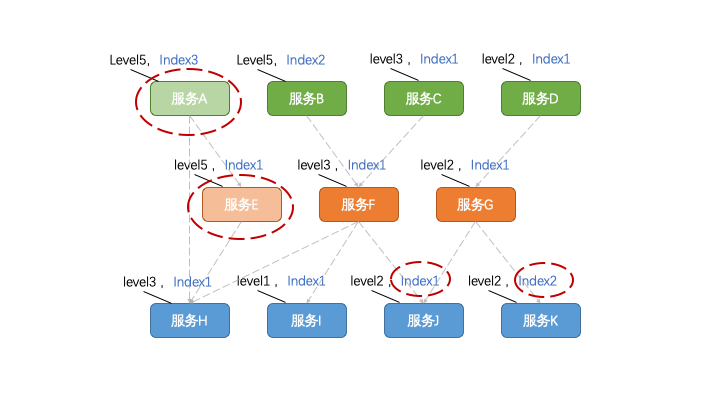
當然,根據所支撐的功能數量只是一個「業務無關性」的通用辦法。如果想精益求精,還需要對每個功能做「作用」上的分析,畢竟不同功能之間的相對重要性還是有所差異的。(這里可以擴展了解一下Analytic Hierarchy Process,層次分析法,簡稱AHP)
對了,定級定序的時候有一點是需要格外注意的:某個程序所依賴的下游程序的級別不能低于該程序的級別。
為什么呢?因為一旦所依賴的程序被降級了,自然會導致其所支撐的所有上游程序不可用。所以,其上游程序的等級再高也是沒有意義的。
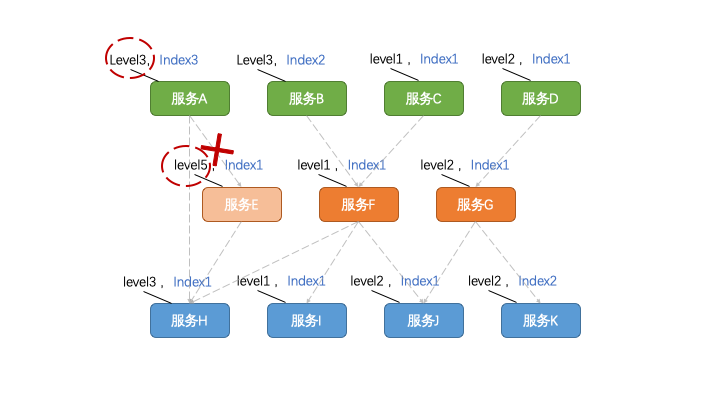
至此,完成了“排兵布陣”,接下來就是“實施運作”了。
首先要制定觸發機制。這同熔斷、限流一樣,什么時候該觸發「降級」這個動作也需要依賴提前制定的一些策略。這部分內容和前面兩篇(熔斷、限流)類似,無非是接口的超時率、錯誤率,或者系統的資源耗用率等,這里就不重復展開了。
當程序發現滿足了降級條件進入「降級模式」后,程序該如何處理請求呢?
全局變量 int _runLevel = 3; //運行系統級別,默認值5
全部變量 int _runIndex = 7; //運行系統序號,默認值9
//以下是一個level=4、index=8的功能示例。
if(myLevel > _runLevel and myIndex > _runIndex){
// 進入降級模式。
}
else{
// do something...
}
題外話:通過Aop+注解(特性)的方式來做上面的if判斷是一個爽的事情。
雖然處理請求的方式有很多,但特別強調的是,要實現的降級策略要盡可能的簡單。因為「邊際效應」的存在,為了應對突發狀況把事情反而搞復雜了就得不償失了。
那么在實現部分,如果是前端。我們比較常見的是:
在返回的http報文中通過Cache-Control的設置,讓后續的請求直接走瀏覽器緩存。
頁面中原本需要異步加載的數據,直接不加載。
禁用部分操作按鈕,甚至直接告知“臨時關閉”。
動態頁面的url通過反響代理切換到靜態頁面返回。
這里面除了禁用按鈕外,大部分事情都可以在接入層,如nginx中處理掉,這樣可以避免對業務項目的代碼侵入。
如果是后端程序的話,針對「讀」類型的操作,可以將“// 進入降級模式”部分代碼寫成下面的樣子:
如果是無返回值方法。默認return或者throw一個異常。
如果是有返回值方法。默認返回本地mock的數據或者throw一個異常。
后端部分如果有使用一些中間件的話,直接在中間件(rpc、mq代理等)中處理掉是極好的(一般會內置一個fallback接口待實現),如此也可以避免對業務代碼的侵入。
最后我們來聊聊后端程序的「寫」問題。
緩存是大型系統中的常客,隨著系統規模越大,為了在性能和成本上尋求更優,不可避免的會增加復雜度引入多級緩存。如此就會變成:本地緩存 --> 分布式緩存 --> DB/源服務,這樣的一個層層遞進的關系。
平時的代碼可能是這樣的:
if(write數據庫(data) == true){
if(write分布式緩存(data) == true){
write本地緩存(data);
return success;
}
else{
rollback數據庫(data);
return fail;
}
}
else{
return fail;
}
在高負載時期,我們可以降低對一致性的要求。將耗時的「數據落盤」操作降級為「異步」進行。
if(write分布式緩存(data) == true){
write本地緩存(data);
pushMessage(data);
//發出的消息可以通過集中式的MQ、也可以直接寫本地磁盤。
return success;
}
else{
return fail;
}
甚至,如果可以的話能做的更徹底,同步到分布式緩存也異步進行。
write本地緩存(data); pushMessage(data); //發出的消息可以通過集中式的MQ、也可以直接寫本地磁盤。 return success;
數據庫是系統的最后一座堡壘,非非非常極端的情況下,我們可以把一些「寫數據」操作在「數據庫訪問框架」中給禁用了,讓給所有資源都給到「讀數據」。使得系統從表象上來看至少還是“活著站在那”的,雖然很多功能操作一下就是返回失敗(這不也是實在沒辦法了嘛,面子得要啊,死撐~)。
至此我們聊了做降級的思路以及最常見的一些實現方式,但是真正要把降級最好是一個任重而道遠的過程。
從方案的角度來說,如果降級的過程需對每個功能/程序逐一進行,那么理論上10個功能點就可以產生P(10,10)= 3628800種方案。
再從現實的角度來說,流量又是不可預測的。某些功能可能這次需要作為level2來看待,下次其實作為level3就夠了。
所以這是一個需要長期不斷打磨和調優的過程。
最后,希望近期的「高可用三劍客」可以作為你了解「高可用」的起點,可以先收藏防身(當然再分享一下也是極好的:)),歡迎后續一起交流探討~
Question:
你曾經是否有遇到過什么場景,當時是通過馬上改代碼來「降級」呢?歡迎來吐槽~
相關文章:
如何在到處是“雷”的系統中「明哲保身」?這是第一招
想通關「限流」?只要這一篇
分布式系統關注點——數據一致性(上篇)
作者:Zachary
出處:https://www.cnblogs.com/Zachary-Fan/p/degradation.html
?關于作者:張帆(Zachary,個人微信號:Zachary-ZF)。堅持用心打磨每一篇高質量原創。歡迎掃描下方的二維碼~。
定期發表原創內容:架構設計丨分布式系統丨產品丨運營丨一些思考。
如果你是初級程序員,想提升但不知道如何下手。又或者做程序員多年,陷入了一些瓶頸想拓寬一下視野。歡迎關注我的公眾號「跨界架構師」,回復「技術」,送你一份我長期收集和整理的思維導圖。
如果你是運營,面對不斷變化的市場束手無策。又或者想了解主流的運營策略,以豐富自己的“倉庫”。歡迎關注我的公眾號「跨界架構師」,回復「運營」,送你一份我長期收集和整理的思維導圖。

免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





