溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
許多網站在進行某些操作前會要求輸入驗證碼以此來抵御爬蟲和***。此篇主要講述如何通過代碼來識別一些常見的驗證碼。以此探究圖片識別的過程以及如何避免生成容易被識別的驗證碼。
圖片識別的過程
取樣本
清洗區分樣本
提取樣本特征
Java有豐富的圖片處理類,本次操作使用java語言。
一、取目標網站的驗證碼樣本。在web頁面中查看驗證碼請求的地址。通過http請求批量獲取驗證碼并保存在本地。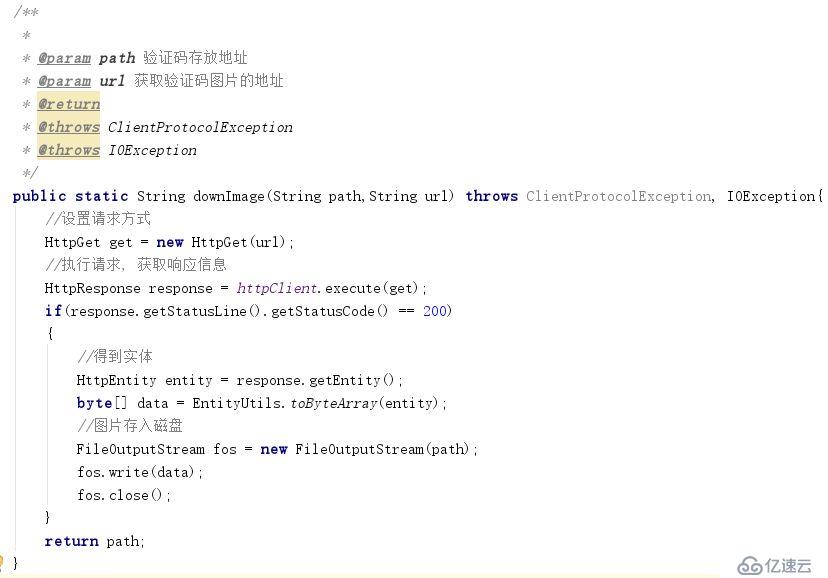
二、區分樣本。對每張驗證碼圖片進行人工識別區分,重命名為該圖片的驗證碼。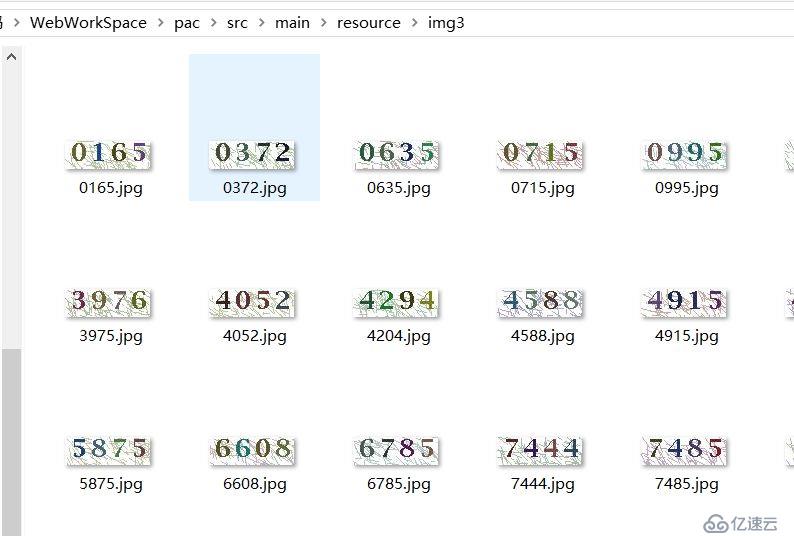
三、清洗切割樣本,提取樣本特征。圖片識別需要盡可能細地區分出特征點。我們觀察上圖的驗證碼圖片可以發現多個信息:
● 驗證碼的背景存在著許多干擾線。
● 每個數字分明,所占的位置幾乎是均等的。
● 驗證碼的數字顏色比較深,干擾因素顏色較淺。
我們可以嘗試通過顏色的深淺去除干擾因素。先通過灰度處理,將驗證碼中顏色較淺的點置換成白色,顏色較深的點置換成黑色。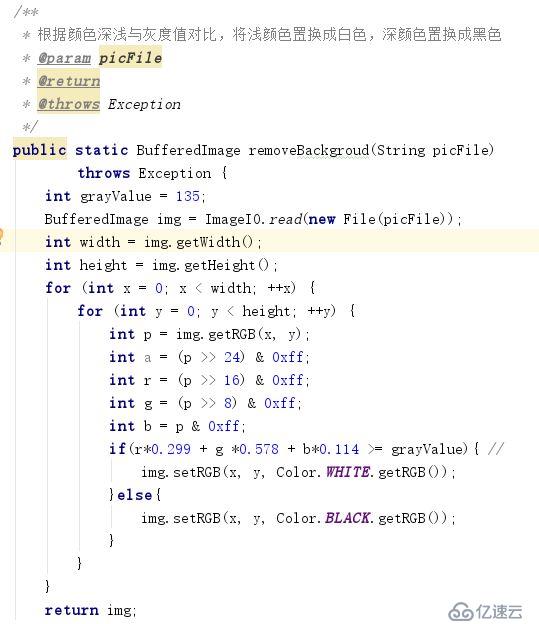
通過改變灰度閾值grayValue不斷嘗試去除干擾點。最后得到干凈的驗證碼。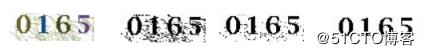
接下來通過識別圖片中的黑色點,使用下面的trainData()方法。
沿著黑色點進行矩形切割,得到單個數字的特征樣本。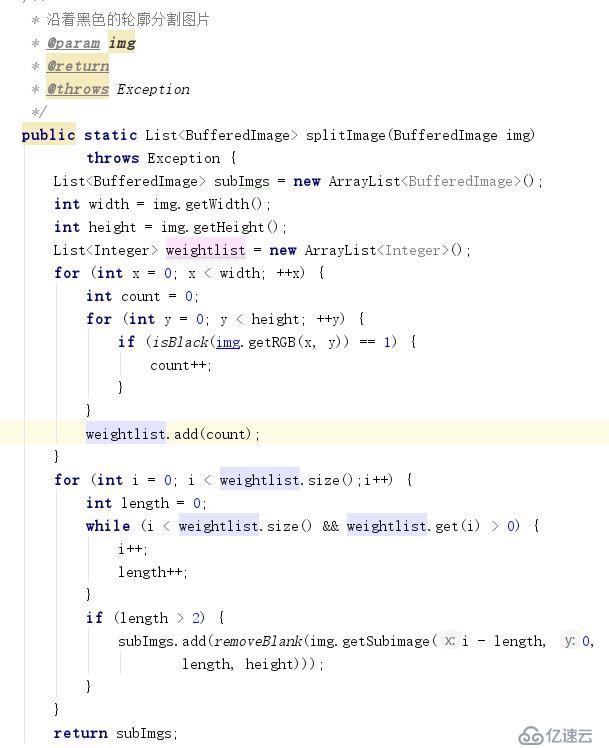

得到的驗證碼特征樣本訓練集合如下:
四、提取目標驗證碼的特征,與訓練集合做對比,識別目標驗證碼圖片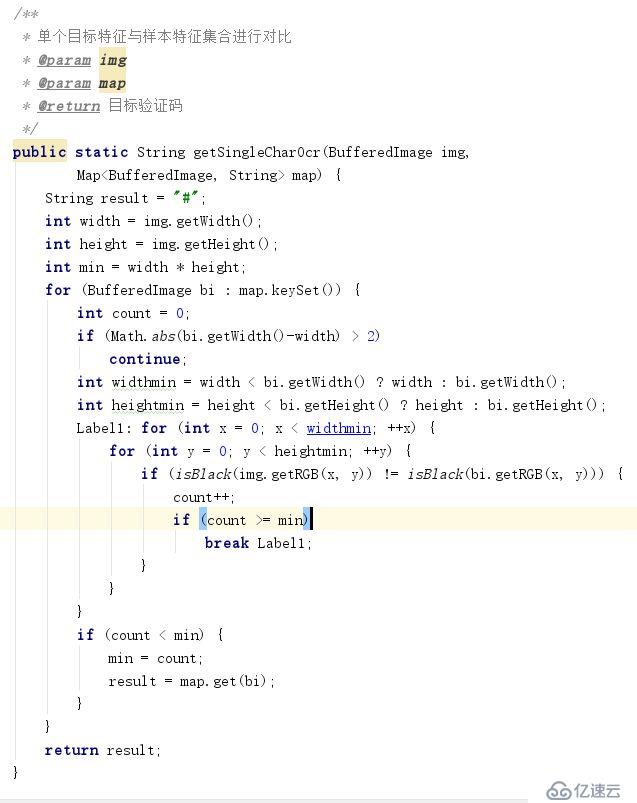
通過上面的三步,我們已經得到了一組樣本特征,接下來只需要把將目標驗證碼同樣執行上面的3步。把提取出來的目標驗證碼特征與樣本特征作對比。如果雙方絕大部分像素點的顏色相同,則可認為目標驗證碼與樣本內容一致。取樣本的文件名,即可等到目標驗證的內容了。以下為對比識別的代碼。
通過上面的四部操作,我們已經能夠識別出一些網站的驗證碼了。上面使用的方法是通過顏色的深淺,去除干擾素,再提取樣本特征進行對比。面對其他的一些驗證碼需要我們通過觀察掌握圖片的規律,靈活地使用其他的算法來識別去除干擾素,提取出樣本特征。
同樣地,在生成驗證碼的過程中,我們需要避免生成易于去除的干擾素。各個驗證碼之間在不影響人工識別的情況下盡可能粘連起來,避免被切割分類。
文章來自公眾號:睿江云計算
睿江云官網鏈接:https://www.eflycloud.com/home?from=RJ0024
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





