溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
復制的過程步驟如下:
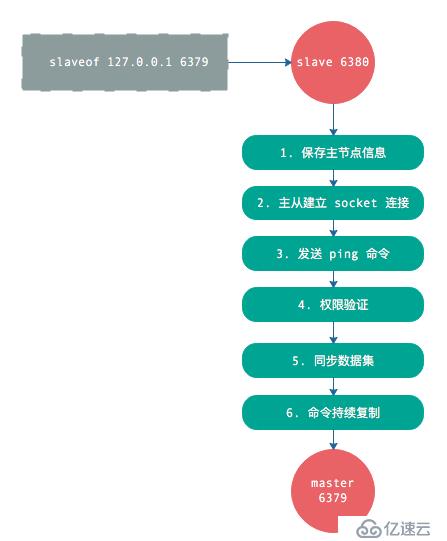
上面說的復制過程,其中有一個步驟是“同步數據集”,這個就是現在講的‘數據間的同步’。
redis 同步有 2 個命令:
sync 和 psync,前者是 redis 2.8 之前的同步命令,后者是 redis 2.8 為了優化 sync 新設計的命令。我們會重點關注 2.8 的 psync 命令。
psync 命令需要 3 個組件支持:
主從節點各自復制偏移量:
主節點復制積壓緩沖區:
主節點運行 ID:
如果在重啟時不改變運行 ID 呢?
psync 命令的使用方式:
命令格式為psync{runId}{offset}
runId:從節點所復制主節點的運行 id
offset:當前從節點已復制的數據偏移量
psync 執行流程: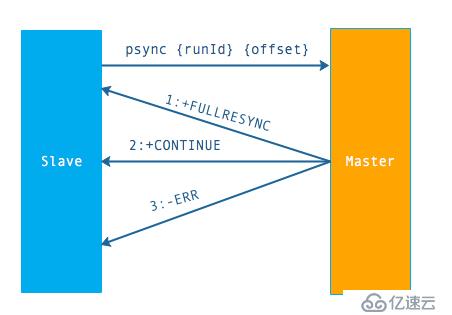
流程說明:從節點發送 psync 命令給主節點,runId 就是目標主節點的 ID,如果沒有默認為 -1,offset 是從節點保存的復制偏移量,如果是第一次復制則為 -1.
主節點會根據 runid 和 offset 決定返回結果:
到這里,數據之間的同步就講的差不多了,篇幅還是比較長的。主要是針對 psync 命令相關之間的介紹。
全量復制是 Redis 最早支持的復制方式,也是主從第一次建立復制時必須經歷的的階段。觸發全量復制的命令是 sync 和 psync。之前說過,這兩個命令的分水嶺版本是 2.8,redis 2.8 之前使用 sync 只能執行全量不同,2.8 之后同時支持全量同步和部分同步。
流程如下:
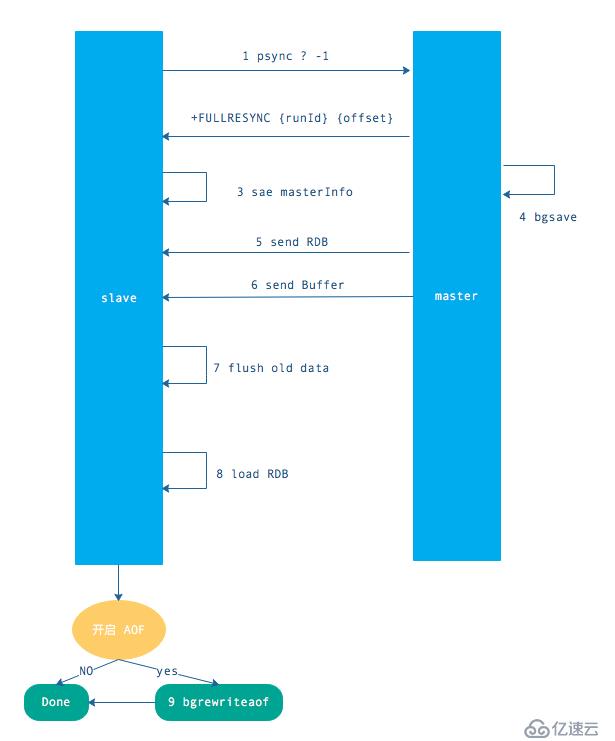
介紹一下上圖步驟:
以上加粗的部分是整個全量同步耗時的地方。
注意:
當從節點正在復制主節點時,如果出現網絡閃斷和其他異常,從節點會讓主節點補發丟失的命令數據,主節點只需要將復制緩沖區的數據發送到從節點就能夠保證數據的一致性,相比較全量復制,成本小很多。
步驟如下:
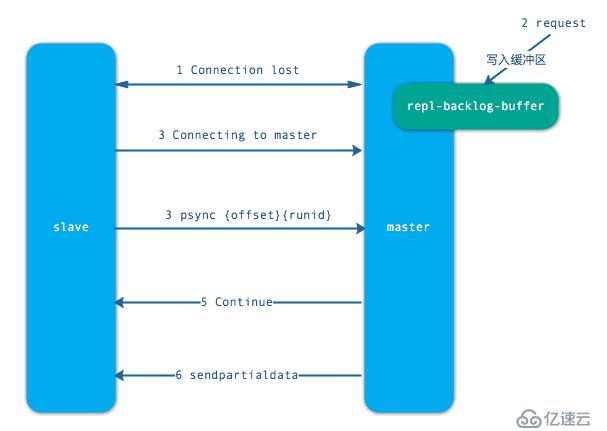
主從節點在建立復制后,他們之間維護著長連接并彼此發送心跳命令。
心跳的關鍵機制如下:
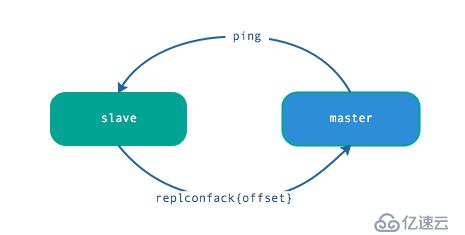
注意:為了降低主從延遲,一般把 redis 主從節點部署在相同的機房/同城機房,避免網絡延遲帶來的網絡分區造成的心跳中斷等情況。
主節點不但負責數據讀寫,還負責把寫命令同步給從節點,寫命令的發送過程是異步完成,也就是說主節點處理完寫命令后立即返回客戶度,并不等待從節點復制完成。
異步復制的步驟很簡單,如下:
本文主要分析了 Redis 的復制原理,包括復制過程,數據之間的同步,全量復制的流程,部分復制的流程,心跳設計,異步復制流程。
其中,可以看出,RDB 數據之間的同步非常耗時。所以,Redis 在 2.8 版本退出了類似增量復制的 psync 命令,當 Redis 主從直接發生了網絡中斷,不會進行全量復制,而是將數據放到緩沖區(默認 1MB)里,在通過主從之間各自維護復制 offset 來判斷緩存區的數據是否溢出,如果沒有溢出,只需要發送緩沖區數據即可,成本很小,反之,則要進行全量復制,因此,控制緩沖區大小非常的重要。
好了,關于redis 主從復制的原理就介紹到這里 ,篇幅有限,難免疏漏。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





