溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
下文內容主要給大家帶來 MySQL 高性能如何巧妙實現優化,這里所講到的知識,與書籍略有不同,都是億速云專業技術人員在與用戶接觸過程中,總結出來的,具有一定的經驗分享價值,希望給廣大讀者帶來幫助。
最近公司項目添加新功能,上線后發現有些功能的列表查詢時間很久。原因是新功能用到舊功能的接口,而這些舊接口的 SQL 查詢語句關聯5,6張表且編寫不夠規范,導致 MySQL 在執行 SQL 語句時索引失效,進行全表掃描。原本負責優化的同事有事請假回家,因此優化查詢數據的問題落在筆者手中。筆者在查閱網上 SQL 優化的資料后成功解決了問題,在此從全局角度記錄和總結 MySQL 查詢優化相關技巧。
數據查詢慢,不代表 SQL 語句寫法有問題。 首先,我們需要找到問題的源頭才能“對癥下藥”。筆者用一張流程圖展示 MySQL 優化的思路:
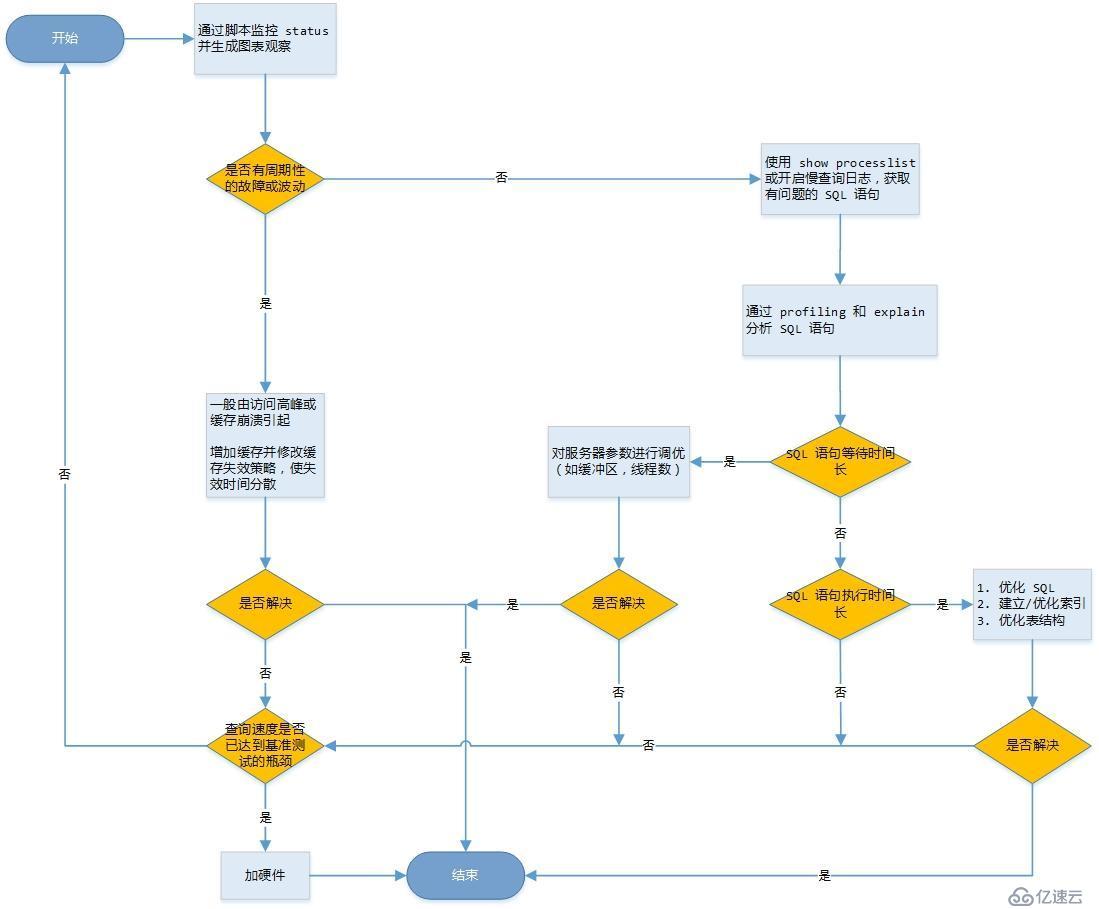
無需更多言語,從圖中可以清楚地看出,導致數據查詢慢的原因有多種,如:緩存失效,在此一段時間內由于高并發訪問導致 MySQL云服務器崩潰;SQL 語句編寫問題;MySQL 云服務器參數問題;硬件配置限制 MySQL 服務性能問題等。
如果系統的并發請求數不高,且查詢速度慢,可以忽略該步驟直接進行 SQL 語句調優步驟。
執行命令:
show status由于返回結果太多,此處不貼出結果。其中,再返回的結果中,我們主要關注 “Queries”、“Threads_connected” 和 “Threads_running” 的值,即查詢次數、線程連接數和線程運行數。
我們可以通過執行如下腳本監控 MySQL 服務器運行的狀態值
#!/bin/bash
while true
domysqladmin -uroot -p"密碼" ext | awk '/Queries/{q=$4}/Threads_connected/{c=$4}/Threads_running/{r=$4}END{printf("%d %d %d\n",q,c,r)}' >> status.txt
sleep 1
done執行該腳本 24 小時,獲取 status.txt 里的內容,再次通過 awk 計算每秒請求 MySQL 服務的次數
awk '{q=$1-last;last=$1}{printf("%d %d %d\n",q,$2,$3)}' status.txt復制計算好的內容到 Excel 中生成圖表觀察數據周期性。
如果觀察的數據有周期性的變化,如上圖的解釋,需要修改緩存失效策略。
例如:
通過隨機數在[3,6,9] 區間獲取其中一個值作為緩存失效時間,這樣分散了緩存失效時間,從而節省了一部分內存的消耗。
當訪問高峰期時,一部分請求分流到未失效的緩存,另一部分則訪問 MySQL 數據庫,這樣減少了 MySQL 服務器的壓力。
執行命令:
show processlist返回結果:
mysql> show processlist;
+----+------+-----------+------+---------+------+----------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+------+-----------+------+---------+------+----------+------------------+
| 9 | root | localhost | test | Query | 0 | starting | show processlist |
+----+------+-----------+------+---------+------+----------+------------------+
1 row in set (0.00 sec)從返回結果中我們可以了解該線程執行了什么命令/SQL 語句以及執行的時間。實際應用中,查詢的返回結果會有 N 條記錄。
其中,返回的 State 的值是我們判斷性能好壞的關鍵,其值出現如下內容,則該行記錄的 SQL 語句需要優化:
Converting HEAP to MyISAM # 查詢結果太大時,把結果放到磁盤,嚴重
Create tmp table #創建臨時表,嚴重
Copying to tmp table on disk #把內存臨時表復制到磁盤,嚴重
locked #被其他查詢鎖住,嚴重
loggin slow query #記錄慢查詢
Sorting result #排序State 字段有很多值,如需了解更多,可以參看文章末尾提供的鏈接。
在配置文件 my.cnf 中的 [mysqld] 一行下邊添加兩個參數:
slow_query_log = 1
slow_query_log_file=/var/lib/mysql/slow-query.log
long_query_time = 2
log_queries_not_using_indexes = 1其中,slow_query_log = 1 表示開啟慢查詢;
slow_query_log_file 表示慢查詢日志存放的位置;
long_query_time = 2 表示查詢 >=2 秒才記錄日志;
log_queries_not_using_indexes = 1 記錄沒有使用索引的 SQL 語句。
注意:slow_query_log_file 的路徑不能隨便寫,否則 MySQL 服務器可能沒有權限將日志文件寫到指定的目錄中。建議直接復制上文的路徑。
修改保存文件后,重啟 MySQL 服務。在 /var/lib/mysql/ 目錄下會創建 slow-query.log 日志文件。連接 MySQL 服務端執行如下命令可以查看配置情況。
show variables like 'slow_query%';
show variables like 'long_query_time';測試慢查詢日志:
mysql> select sleep(2);
+----------+
| sleep(2) |
+----------+
| 0 |
+----------+
1 row in set (2.00 sec)打開慢查詢日志文件
[root@localhost mysql]# vim /var/lib/mysql/slow-query.log
/usr/sbin/mysqld, Version: 5.7.19-log (MySQL Community Server (GPL)). started with:
Tcp port: 0 Unix socket: /var/lib/mysql/mysql.sock
Time Id Command Argument
# Time: 2017-10-05T04:39:11.408964Z
# User@Host: root[root] @ localhost [] Id: 3
# Query_time: 2.001395 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 0
use test;
SET timestamp=1507178351;
select sleep(2);我們可以看到剛才執行了 2 秒的 SQL 語句被記錄下來了。
雖然在慢查詢日志中記錄查詢慢的 SQL 信息,但是日志記錄的內容密集且不易查閱。因此,我們需要通過工具將 SQL 篩選出來。
MySQL 提供 mysqldumpslow 工具對日志進行分析。我們可以使用 mysqldumpslow --help 查看命令相關用法。
常用參數如下:
-s:排序方式,后邊接著如下參數
c:訪問次數
l:鎖定時間
r:返回記錄
t:查詢時間
al:平均鎖定時間
ar:平均返回記錄書
at:平均查詢時間
-t:返回前面多少條的數據
-g:翻遍搭配一個正則表達式,大小寫不敏感案例:
獲取返回記錄集最多的10個sql
mysqldumpslow -s r -t 10 /var/lib/mysql/slow-query.log
獲取訪問次數最多的10個sql
mysqldumpslow -s c -t 10 /var/lib/mysql/slow-query.log
獲取按照時間排序的前10條里面含有左連接的查詢語句
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/slow-query.log篩選出有問題的 SQL,我們可以使用 MySQL 提供的 explain 查看 SQL 執行計劃情況(關聯表,表查詢順序、索引使用情況等)。
用法:
explain select * from category;返回結果:
mysql> explain select * from category;
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | category | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)字段解釋:
1. id:select 查詢序列號。id相同,執行順序由上至下;id不同,id值越大優先級越高,越先被執行
2. select_type:查詢數據的操作類型,其值如下:
simple:簡單查詢,不包含子查詢或 union
primary:包含復雜的子查詢,最外層查詢標記為該值
subquery:在 select 或 where 包含子查詢,被標記為該值
derived:在 from 列表中包含的子查詢被標記為該值,MySQL 會遞歸執行這些子查詢,把結果放在臨時表
union:若第二個 select 出現在 union 之后,則被標記為該值。若 union 包含在 from 的子查詢中,外層 select 被標記為 derived
union result:從 union 表獲取結果的 select3. table:顯示該行數據是關于哪張表
4. partitions:匹配的分區
5. type:表的連接類型,其值,性能由高到底排列如下:
system:表只有一行記錄,相當于系統表
const:通過索引一次就找到,只匹配一行數據
eq_ref:唯一性索引掃描,對于每個索引鍵,表中只有一條記錄與之匹配。常用于主鍵或唯一索引掃描
ref:非唯一性索引掃描,返回匹配某個單獨值的所有行。用于=、< 或 > 操作符帶索引的列
range:只檢索給定范圍的行,使用一個索引來選擇行。一般使用between、>、<情況
index:只遍歷索引樹
ALL:全表掃描,性能最差注:前5種情況都是理想情況的索引使用情況。通常優化至少到range級別,最好能優化到 ref
6. possible_keys:指出 MySQL 使用哪個索引在該表找到行記錄。如果該值為 NULL,說明沒有使用索引,可以建立索引提高性能
7. key:顯示 MySQL 實際使用的索引。如果為 NULL,則沒有使用索引查詢
8. key_len:表示索引中使用的字節數,通過該列計算查詢中使用的索引的長度。在不損失精確性的情況下,長度越短越好 顯示的是索引字段的最大長度,并非實際使用長度
9. ref:顯示該表的索引字段關聯了哪張表的哪個字段
10. rows:根據表統計信息及選用情況,大致估算出找到所需的記錄或所需讀取的行數,數值越小越好
11. filtered:返回結果的行數占讀取行數的百分比,值越大越好
12. extra: 包含不合適在其他列中顯示但十分重要的額外信息,常見的值如下:
using filesort:說明 MySQL 會對數據使用一個外部的索引排序,而不是按照表內的索引順序進行讀取。出現該值,應該優化 SQL
using temporary:使用了臨時表保存中間結果,MySQL 在對查詢結果排序時使用臨時表。常見于排序 order by 和分組查詢 group by。出現該值,應該優化 SQL
using index:表示相應的 select 操作使用了覆蓋索引,避免了訪問表的數據行,效率不錯
using where:where 子句用于限制哪一行
using join buffer:使用連接緩存
distinct:發現第一個匹配后,停止為當前的行組合搜索更多的行注意:出現前 2 個值,SQL 語句必須要優化。
使用 profiling 命令可以了解 SQL 語句消耗資源的詳細信息(每個執行步驟的開銷)。
select @@profiling;返回結果:
mysql> select @@profiling;
+-------------+
| @@profiling |
+-------------+
| 0 |
+-------------+
1 row in set, 1 warning (0.00 sec)0 表示關閉狀態,1 表示開啟
set profiling = 1; 返回結果:
mysql> set profiling = 1;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> select @@profiling;
+-------------+
| @@profiling |
+-------------+
| 1 |
+-------------+
1 row in set, 1 warning (0.00 sec)在連接關閉后,profiling 狀態自動設置為關閉狀態。
show profiles;返回結果:
mysql> show profiles;
+----------+------------+------------------------------+
| Query_ID | Duration | Query |
+----------+------------+------------------------------+
| 1 | 0.00062925 | select @@profiling |
| 2 | 0.00094150 | show tables |
| 3 | 0.00119125 | show databases |
| 4 | 0.00029750 | SELECT DATABASE() |
| 5 | 0.00025975 | show databases |
| 6 | 0.00023050 | show tables |
| 7 | 0.00042000 | show tables |
| 8 | 0.00260675 | desc role |
| 9 | 0.00074900 | select name,is_key from role |
+----------+------------+------------------------------+
9 rows in set, 1 warning (0.00 sec)該命令執行之前,需要執行其他 SQL 語句才有記錄。
show profile for query Query_ID;返回結果:
mysql> show profile for query 9;
+----------------------+----------+
| Status | Duration |
+----------------------+----------+
| starting | 0.000207 |
| checking permissions | 0.000010 |
| Opening tables | 0.000042 |
| init | 0.000050 |
| System lock | 0.000012 |
| optimizing | 0.000003 |
| statistics | 0.000011 |
| preparing | 0.000011 |
| executing | 0.000002 |
| Sending data | 0.000362 |
| end | 0.000006 |
| query end | 0.000006 |
| closing tables | 0.000006 |
| freeing items | 0.000011 |
| cleaning up | 0.000013 |
+----------------------+----------+
15 rows in set, 1 warning (0.00 sec)每行都是狀態變化的過程以及它們持續的時間。Status 這一列和 show processlist 的 State 是一致的。因此,需要優化的注意點與上文描述的一樣。
其中,Status 字段的值同樣可以參考末尾鏈接。
show profile block io,cpu for query Query_ID;
show profile cpu,block io,memory,swaps,context switches,source for query Query_ID;
show profile all for query Query_ID;主要以查詢優化、索引使用和表結構設計方面進行講解。
避免 SELECT *,需要什么數據,就查詢對應的字段。
當 B 表的數據集小于 A 表時,用 in 優化 exist;使用 in ,兩表執行順序是先查 B 表,再查 A 表
select * from A where id in (select id from B)
當 A 表的數據集小于 B 表時,用 exist 優化 in;使用 exists,兩表執行順序是先查 A 表,再查 B 表
select * from A where exists (select 1 from B where B.id = A.id)一些情況下,可以使用連接代替子查詢,因為使用 join,MySQL 不會在內存中創建臨時表。
適當添加冗余字段,減少表關聯。
主鍵自動創建唯一索引
頻繁作為查詢條件的字段
查詢中與其他表關聯的字段
查詢中排序的字段
頻繁更新的字段
where 條件中用不到的字段
表記錄太少
經常增刪改的表
單表查詢:哪個列作查詢條件,就在該列創建索引
多表查詢:left join 時,索引添加到右表關聯字段;right join 時,索引添加到左表關聯字段
不要對索引列進行任何操作(計算、函數、類型轉換)
索引列中不要使用 !=,<> 非等于
索引列不要為空,且不要使用 is null 或 is not null 判斷
違背上述原則可能會導致索引失效,具體情況需要使用 explain 命令進行查看
除了違背索引創建和使用原則外,如下情況也會導致索引失效:
模糊查詢時,以 % 開頭
使用 or 時,如:字段1(非索引)or 字段2(索引)會導致索引失效。
index(a,b,c) ,以字段 a,b,c 作為復合索引為例:
| 語句 | 索引是否生效 |
|---|---|
| where a = 1 | 是,字段 a 索引生效 |
| where a = 1 and b = 2 | 是,字段 a 和 b 索引生效 |
| where a = 1 and b = 2 and c = 3 | 是,全部生效 |
| where b = 2 或 where c = 3 | 否 |
| where a = 1 and c = 3 | 字段 a 生效,字段 c 失效 |
| where a = 1 and b > 2 and c = 3 | 字段 a,b 生效,字段 c 失效 |
| where a = 1 and b like 'xxx%' and c = 3 | 字段 a,b 生效,字段 c 失效 |
使用可以存下數據最小的數據類型
使用簡單的數據類型。int 要比 varchar 類型在mysql處理簡單
盡量使用 tinyint、smallint、mediumint 作為整數類型而非 int
盡可能使用 not null 定義字段,因為 null 占用4字節空間
盡量少用 text 類型,非用不可時最好考慮分表
盡量使用 timestamp 而非 datetime
當數據庫中的數據非常大時,查詢優化方案也不能解決查詢速度慢的問題時,我們可以考慮拆分表,讓每張表的數據量變小,從而提高查詢效率。
1. 垂直拆分:將表中多個列分開放到不同的表中。例如用戶表中一些字段經常被訪問,將這些字段放在一張表中,另外一些不常用的字段放在另一張表中。 插入數據時,使用事務確保兩張表的數據一致性。
2. 水平拆分:按照行進行拆分。例如用戶表中,使用用戶ID,對用戶ID取10的余數,將用戶數據均勻的分配到0~9的10個用戶表中。查找時也按照這個規則查詢數據。
一般情況下對數據庫而言都是“讀多寫少”。換言之,數據庫的壓力多數是因為大量的讀取數據的操作造成的。我們可以采用數據庫集群的方案,使用一個庫作為主庫,負責寫入數據;其他庫為從庫,負責讀取數據。這樣可以緩解對數據庫的訪問壓力。
sort_buffer_size 排序緩沖區內存大小
join_buffer_size 使用連接緩沖區大小
read_buffer_size 全表掃描時分配的緩沖區大小
Innodb_log_file_size 事務日志大小
Innodb_log_files_in_group 事務日志個數
Innodb_log_buffer_size 事務日志緩沖區大小
Innodb_flush_log_at_trx_commit 事務日志刷新策略,其值如下:
0:每秒進行一次 log 寫入 cache,并 flush log 到磁盤
1:在每次事務提交執行 log 寫入 cache,并 flush log 到磁盤
2:每次事務提交,執行 log 數據寫到 cache,每秒執行一次 flush log 到磁盤
expire_logs_days 指定自動清理 binlog 的天數
max_allowed_packet 控制 MySQL 可以接收的包的大小
skip_name_resolve 禁用 DNS 查找
read_only 禁止非 super 權限用戶寫權限
skip_slave_start 級你用 slave 自動恢復
### 7.4 其他
max_connections 控制允許的最大連接數
tmp_table_size 臨時表大小
max_heap_table_size 最大內存表大小
筆者并沒有使用這些參數對 MySQL 服務器進行調優,具體詳情介紹和性能效果請參考文章末尾的資料或另行百度。
硬件的性能直接決定 MySQL 數據庫的性能瓶頸,直接決定 MySQL 數據庫的運行數據和效率。
作為軟件開發程序員,我們主要關注軟件方面的優化內容,以下硬件方面的優化作為了解即可
內存的 IO 比硬盤的速度快很多,可以增加系統的緩沖區容量,使數據在內存停留的時間更長,以減少磁盤的 IO
使用 SSD 或 PCle SSD 設備,至少獲得數百倍甚至萬倍的 IOPS 提升
購置陣列卡同時配備 CACHE 及 BBU 模塊,可以明顯提升 IOPS
### 8.3 配置 CUP 相關
在服務器的 BIOS 設置中,調整如下配置:
選擇 Performance Per Watt Optimized(DAPC)模式,發揮 CPU 最大性能
關閉 C1E 和 C States 等選項,提升 CPU 效率
對于以上關于 MySQL 高性能如何巧妙實現優化,如果大家還有更多需要了解的可以持續關注我們億速云的行業推新,如需獲取專業解答,可在官網聯系售前售后的,希望該文章可給大家帶來一定的知識更新。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





