溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
一個老外的有關Redis的博客文章中提到一個有趣的事情:它們在測試期間獲得的延遲圖。為了持久化Redis的數據到磁盤(例如:RDB持久化),Redis需要調用fork()系統命令。
通常使用物理服務器和大多數虛擬機管理程序進行fork是很快的,即使很大的進程也是如此。 然而,Xen的fork()速度很慢,因此對于某些EC2實例類型(以及其他虛擬服務器提供程序),每次父進程調用fork()以便進行RDB持久化時,可能會出現嚴重的延遲峰值。 如下圖所示,清晰的展示了延遲峰值:
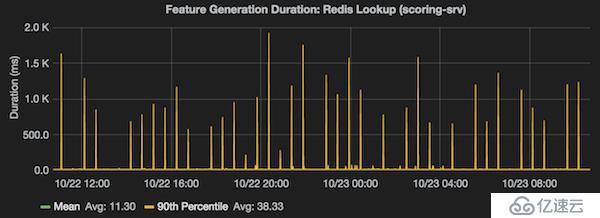
您可以想象一下,如果您在fork()的時候做一個延遲測試,那么在父進程fork()的時候,所有請求將延遲一秒(以上圖為例)。 這將產生大量具有高延遲的樣本,并且將影響99%的結果。
要更改實例類型,配置,設置或其他任何內容以改善此行為是一個好主意,并且有些用例即使單個請求具有過高延遲也是不可接受的。然而很明顯的是,每30分鐘發生1秒的延遲峰值不是很明顯,因為這與在請求中均勻分布延遲峰值有很大不同。
如果是均勻分布的峰值,如果訪問某個頁面需要對Redis服務器執行大量請求,則訪問頁面很可能會碰到延遲:這會嚴重影響服務質量。
然而,如上圖所示,每運行30分鐘后1秒的延遲是完全不同的事情。具有良好延遲表現的百分比隨著請求數量的增加而變得更好,因為請求越多,這個延遲就越不可能在樣本中過度表示出來,反而會被隱藏。如果您每分鐘只有1個請求,并且其中一個請求恰好碰到fork()導致的高延遲,那就會讓延遲測試結果非常難看。
另外:大多數頁面瀏覽不受影響。 因為唯一那幾個用戶碰到1秒延遲的,是剛好他們的請求和fork()在同一時間,其他用戶的請求只會有極低的概率碰到這樣糟糕的事情。 另外請注意,與fork()撞上的頁面訪問(即使由100個請求組成)也不會延遲超過一秒,因為fork()完成后請求就會完成,并不需要等到RDB持久化完成。
只有fork()會導致延遲毛刺,fork出來的子進程在生成RDB文件過程中,并不會對系統有很大的影響。除非子進程生成RDB文件的過程中(這個過程使用了操作系統的copy-on-write機制)有大量的寫入,而且服務器可用內存不多,這時候可能會發生swapping導致出現延遲。
在當今最流行的運行時環境EC2實例中,fork延遲是Redis用戶最糟糕的體驗之一,所以redis作者正著手測試Redis和EC2:相信很快就會在Redis官方文檔中有對EC2進行特定優化的說明 ,到時候會有比在master-slaves中禁用持久性操作更安全的方案。
如果您現在需要EC2 + Redis主機并且已禁用持久性,則最簡單的部署方式是禁用Redis實例的自動重啟,并使用Sentinel進行故障轉移,以便崩潰的主服務器不會自動返回可用狀態。 在檢查故障轉移成功并且有新的可用的master后,系統管理員可以手動重新啟動實例。
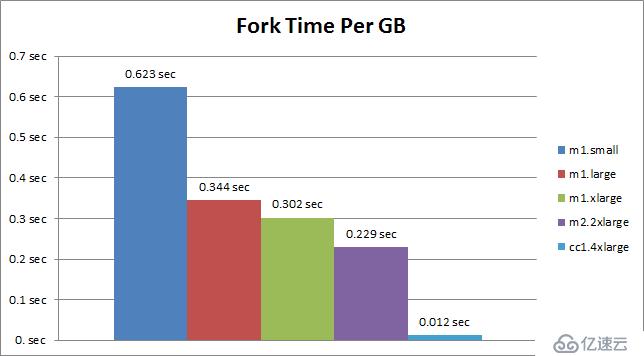
需要說明的是,并非所有EC2實例都是相同的,恰恰相反,各種EC2實例fork表現差異還很大。如下圖所示,是老外做的一些測試:
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





