溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
JVM載執行Java程序的過程中會把它所管理的內存劃分為若干個不同的數據區域。這些區域都有各自的用途,以及創建和銷毀的時間,有的區域隨著虛擬機進程的啟動而存在,有些區域則是依賴用戶線程的啟動和結束而建立和銷毀。具體如下圖所示:
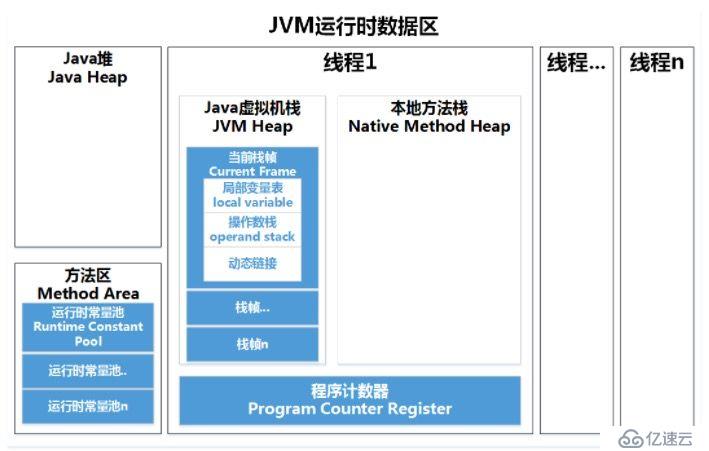
程序計數器(Program Counter Register)是一塊較小的內存空間,可以看作是當前線程所執行的字節碼的行號指示器。在虛擬機概念模型中,字節碼解釋器工作時就是通過改變計數器的值來選取下一條需要執行的字節碼指令,分支、循環、跳轉、異常處理、線程恢復等基礎功能都需要依賴這個計數器來完成。
程序計數器是一塊“線程私有”的內存,如上文的圖所示,每條線程都有一個獨立的程序計數器,各條線程之間的計數器互不影響,獨立存儲。這樣設計使得在多線程環境下,線程切換后能恢復到正確的執行位置。
如果線程正在執行的是一個Java方法,這個計數器記錄的是正在執行的虛擬機字節碼指令的地址;若執行的是Native方法,則計數器為空(Undefined)(因為對于Native方法而言,它的方法體并不是由Java字節碼構成的,自然無法應用上述的“字節碼指令的地址”的概念)。程序計數器也是唯一一個在Java虛擬機規范中沒有規定任何OutOfMemoryError情況的內存區域。
Java虛擬機棧(Java Virtual Machine Stacks)描述的是Java方法執行的內存模型:每個方法在執行的同時都會創建一個棧幀(Stack Frame),棧幀中存儲著局部變量表、操作數棧、動態鏈接、方法出口等信息。每一個方法從調用直至執行完成的過程,會對應一個棧幀在虛擬機棧中入棧到出棧的過程。與程序計數器一樣,Java虛擬機棧也是線程私有的。
函數的調用有完美的嵌套關系——調用者的生命期總是長于被調用者的生命期,并且后者在前者的之內。這樣,被調用者的局部信息所占空間的分配總是后于調用者的(后入),而其釋放則總是先于調用者的(先出),所以正好可以滿足棧的LIFO順序,選用棧這種數據結構來實現調用棧是一種很自然的選擇。
局部變量表中存放了編譯期可知的各種:
基本數據類型(boolen、byte、char、short、int、 float、 long、double)
對象引用(reference類型,它不等于對象本身,可能是一個指向對象起始地址的指針,也可能是指向一個代表對象的句柄或其他與此對象相關的位置)
returnAddress類型(指向了一條字節碼指令的地址)
其中64位長度的long和double類型的數據會占用2個局部變量空間(Slot),其余數據類型只占用1個。局部變量表所需的內存空間在編譯期間完成分配,當進入一個方法時,這個方法需要在幀中分配多大的局部變量空間是完全確定的,在方法運行期間不會改變局部變量表的大小。
Java虛擬機規范中對這個區域規定了兩種異常狀況:
StackOverflowError:線程請求的棧深度大于虛擬機所允許的深度,將會拋出此異常。
OutOfMemoryError:當可動態擴展的虛擬機棧在擴展時無法申請到足夠的內存,就會拋出該異常。
本地方法棧(Native Method Stack)與Java虛擬機棧作用很相似,它們的區別在于虛擬機棧為虛擬機執行Java方法(即字節碼)服務,而本地方法棧則為虛擬機使用到的Native方法服務。
在虛擬機規范中對本地方法棧中使用的語言、方式和數據結構并無強制規定,因此具體的虛擬機可實現它。甚至有的虛擬機(Sun HotSpot虛擬機)直接把本地方法棧和虛擬機棧合二為一。與虛擬機一樣,本地方法棧會拋出StackOverflowError和OutOfMemoryError異常。
對于大多數應用而言,Java堆(Heap)是Java虛擬機所管理的內存中最大的一塊,它被所有線程共享的,在虛擬機啟動時創建。此內存區域唯一的目的是存放對象實例,幾乎所有的對象實例都在這里分配內存,且每次分配的空間是不定長的。在Heap 中分配一定的內存來保存對象實例,實際上只是保存對象實例的屬性值,屬性的類型和對象本身的類型標記等,并不保存對象的方法(方法是指令,保存在Stack中),在Heap 中分配一定的內存保存對象實例和對象的序列化比較類似。對象實例在Heap 中分配好以后,需要在Stack中保存一個4字節的Heap 內存地址,用來定位該對象實例在Heap 中的位置,便于找到該對象實例。
Java虛擬機規范中描述道:所有的對象實例以及數組都要在堆上分配,但是隨著JIT編譯器的發展和逃逸分析技術逐漸成熟,棧上分配、標量替換優化技術將會導致一些微妙的變化發生,所有的對象都在堆上分配的定論也并不“絕對”了。
Java堆是垃圾收集器管理的主要區域,因此也被稱為“GC堆(Garbage Collected Heap)”。從內存回收的角度看內存空間可如下劃分:
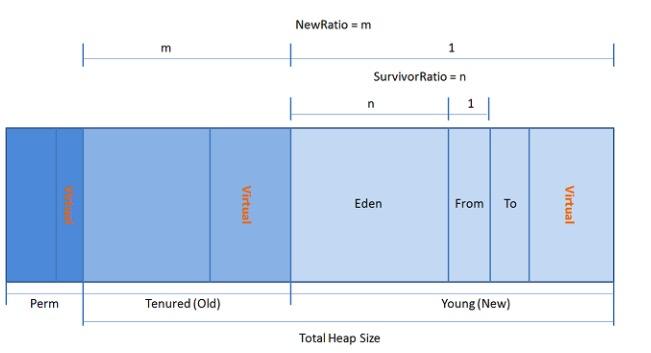
新生代(Young): 新生成的對象優先存放在新生代中,新生代對象朝生夕死,存活率很低。在新生代中,常規應用進行一次垃圾收集一般可以回收70% ~ 95% 的空間,回收效率很高。新生代又可細分為Eden空間、From Survivor空間、To Survivor空間,默認比例為8:1:1。它們的具體作用將在下一篇文章講解GC時介紹。
老年代(Tenured/Old):在新生代中經歷了多次(具體看虛擬機配置的閥值)GC后仍然存活下來的對象會進入老年代中。老年代中的對象生命周期較長,存活率比較高,在老年代中進行GC的頻率相對而言較低,而且回收的速度也比較慢。
永久代(Perm):永久代存儲類信息、常量、靜態變量、即時編譯器編譯后的代碼等數據,對這一區域而言,Java虛擬機規范指出可以不進行垃圾收集,一般而言不會進行垃圾回收。
其中新生代和老年代組成了Java堆的全部內存區域,而永久代不屬于堆空間,它在JDK 1.8以前被Sun HotSpot虛擬機用作方法區的實現,關于方法區的具體內容將在稍后介紹。
方法區(Method Area)與Java堆一樣,是各個線程共享的內存區域。Object Class Data(類定義數據)是存儲在方法區的,此外,常量、靜態變量、JIT編譯后的代碼也存儲在方法區。正因為方法區所存儲的數據與堆有一種類比關系,所以它還被稱為?Non-Heap。
JDK 1.8以前的永久代(PermGen)
Java虛擬機規范對方法區的限制非常寬松,除了和Java堆一樣不需要連續的內存和可以選擇固定大小或者可擴展外,還可以選擇不實現垃圾收集,也就是說,Java虛擬機規范只是規定了方法區的概念和它的作用,并沒有規定如何去實現它。對于JDK 1.8之前的版本,HotSpot虛擬機設計團隊選擇把GC分代收集擴展至方法區,即用永久代來實現方法區,這樣HotSpot的垃圾收集器可以像管理Java堆一樣管理這部分內存,能夠省去專門為方法區編寫內存管理代碼的工作。對于其他的虛擬機(如Oracle JRockit、IBM J9等)來說是不存在永久代的概念的。
如果運行時有大量的類產生,可能會導致方法區被填滿,直至溢出。常見的應用場景如:
Spring和ORM框架使用CGLib操縱字節碼對類進行增強,增強的類越多,就需要越大的方法區來保證動態生成的Class可以加載入內存。
大量JSP或動態產生JSP文件的應用(JSP第一次運行時需要編譯為Java類)。
基于OSGi的應用(即使是同一個類文件,被不同的類加載器加載也會視為不同的類)。 ……
這些都會導致方法區溢出,報出java.lang.OutOfMemoryError: PermGen space。
JDK 1.8的元空間(Metaspace)
在JDK 1.8中,HotSpot虛擬機設計團隊為了促進HotSpot與?JRockit的融合,修改了方法區的實現,移除了永久代,選擇使用本地化的內存空間(而不是JVM的內存空間)存放類的元數據,這個空間叫做元空間(Metaspace)。
做了這個改動以后,java.lang.OutOfMemoryError: PermGen的空間問題將不復存在,并且不再需要調整和監控這個內存空間。且虛擬機需要為方法區設計額外的GC策略:如果類元數據的空間占用達到參數“MaxMetaspaceSize”設置的值,將會觸發對死亡對象和類加載器的垃圾回收。 為了限制垃圾回收的頻率和延遲,適當的監控和調優元空間是非常有必要的。元空間過多的垃圾收集可能表示類、類加載器內存泄漏或對你的應用程序來說空間太小了。
元空間的內存管理由元空間虛擬機來完成。先前,對于類的元數據我們需要不同的垃圾回收器進行處理,現在只需要執行元空間虛擬機的C++代碼即可完成。在元空間中,類和其元數據的生命周期和其對應的類加載器是相同的。話句話說,只要類加載器存活,其加載的類的元數據也是存活的,因而不會被回收掉。
我們從行文到現在提到的元空間稍微有點不嚴謹。準確的來說,每一個類加載器的存儲區域都稱作一個元空間,所有的元空間合在一起就是我們一直說的元空間。當一個類加載器被垃圾回收器標記為不再存活,其對應的元空間會被回收。在元空間的回收過程中沒有重定位和壓縮等操作。但是元空間內的元數據會進行掃描來確定Java引用。
元空間虛擬機負責元空間的分配,其采用的形式為組塊分配。組塊的大小因類加載器的類型而異。在元空間虛擬機中存在一個全局的空閑組塊列表。當一個類加載器需要組塊時,它就會從這個全局的組塊列表中獲取并維持一個自己的組塊列表。當一個類加載器不再存活,那么其持有的組塊將會被釋放,并返回給全局組塊列表。類加載器持有的組塊又會被分成多個塊,每一個塊存儲一個單元的元信息。組塊中的塊是線性分配(指針碰撞分配形式)。組塊分配自內存映射區域。這些全局的虛擬內存映射區域以鏈表形式連接,一旦某個虛擬內存映射區域清空,這部分內存就會返回給操作系統。
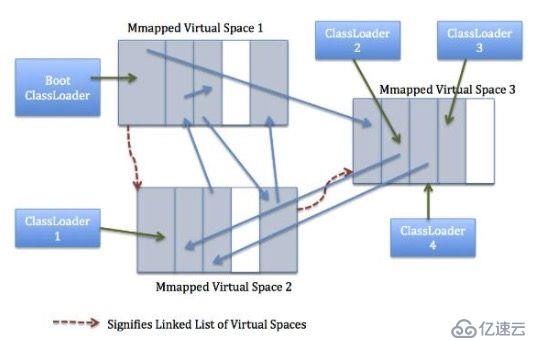
上圖展示的是虛擬內存映射區域如何進行元組塊的分配。類加載器1和3表明使用了反射或者為匿名類加載器,他們使用了特定大小組塊。 而類加載器2和4根據其內部條目的數量使用小型或者中型的組塊。
運行時常量池(Runtime Constant Pool)
運行時常量池(Runtime Constant Pool)是方法區的一部分。Class文件中除了有類的版本、字段、方法、接口等描述信息外,還有一項信息是常量池(Constant Pool Table),用于存放編譯期生成的各種字面量和符號引用,這部分內容將在類加載后進入方法區的運行時常量池存放。
Java虛擬機對Class文件每一部分(自然包括常量池)的格式有嚴格規定,每一個字節用于存儲那種數據都必須符合規范上的要求才會被虛擬機認可、裝載和執行。但對于運行時常量池,Java虛擬機規范沒有做任何有關細節的要求,不同的提供商實現的虛擬機可以按照自己的需求來實現此內存區域。不過一般而言,除了保存Class文件中的描述符號引用外,還會把翻譯出的直接引用也存儲在運行時常量池中。
運行時常量池相對于Class文件常量池的另外一個重要特征是具備動態性,Java語言并不要求常量一定只有編譯器才能產生,也就是并非置入Class文件中的常量池的內容才能進入方法區運行時常量池,運行期間也可能將新的常量放入池中,此特性被開發人員利用得比較多的便是String類的intern()?方法。
直接內存(Direct Memory)并不是虛擬機運行時數據區的一部分,也不是Java虛擬機規范中定義的內存區域。但這部分內存也被頻繁運用,而卻可能導致OutOfMemoryError異常出現,所以這里放到一起講解。
以NIO(New Input/Output)類為例,NIO引入了一種基于通道(Channel)與緩沖區(Buffer)的I/O方式,它可以使用Native函數庫直接分配堆外內存,然后通過一個存儲在Java堆中的DirectByteBuffer對象作為這塊內存的引用進行操作。這樣能避免在Java堆和Native堆中來回復制數據,在一些場景里顯著提高性能。
本機直接內存的分配不會受到Java堆大小的限制,但是既然是內存,還是會受到本機總內存(包括RAM以及SWAP區或分頁文件)大小以及處理器尋址空間的限制。服務器管理員在配置虛擬機參數時,會根據實際內存設置-Xmx等參數信息,但經常忽略直接內存,使得各個內存區域總和大于物理內存限制(包括物理的和操作系統的限制),從而導致動態擴展時出現OutOfMemoryError異常。
Java的對象創建大致有如下四種方式:
new關鍵字?這應該是我們最常見和最常用最簡單的創建對象的方式。
使用newInstance()方法?這里包括Class類的newInstance()方法和Constructor類的newInstance()方法(前者其實也是調用的后者)。
使用clone()方法?要使用clone()方法我們必須實現實現Cloneable接口,用clone()方法創建對象并不會調用任何構造函數。即我們所說的淺拷貝。
反序列化?要實現反序列化我們需要讓我們的類實現Serializable接口。當我們序列化和反序列化一個對象,JVM會給我們創建一個單獨的對象,在反序列化時,JVM創建對象并不會調用任何構造函數。即我們所說的深拷貝。
上面的四種創建對象的方法除了第一種使用new指令之外,其他三種都是使用invokespecial(構造函數的直接調用)。這里我們只說new創建對象的方式,關于invokespecial的內容將在后續文章中介紹。下面我們來看看當虛擬機遇到new指令的時候對象是如何創建的。
1. 類加載檢查
虛擬機遇到一條new指令時,首先將去檢查這個指令的參數是否能在常量池中定位到一個類的符號引用,并且檢查這個符號引用代表的類是否已被加載、解析和初始化過的,如果沒有,則必須先執行相應的類加載過程,關于類加載機制和類加載器的詳細內容將在后續文章中介紹。
2. 分配內存
在類加載檢查通過后,虛擬機就將為新生對象分配內存。對象所需內存的大小在類加載完成后便可完全確定(如何確定在下一節對象內存布局時再詳細講解),為對象分配空間的任務具體便等同于從Java堆中劃出一塊大小確定的內存空間,可以分如下兩種情況討論:
Java堆中內存絕對規整?所有用過的內存都被放在一邊,空閑的內存被放在另一邊,中間放著一個指針作為分界點的指示器,那所分配內存就僅僅是把那個指針向空閑空間那邊挪動一段與對象大小相等的距離,這種分配方式稱為“指針碰撞”(Bump The Pointer)。
Java堆中的內存不規整?已被使用的內存和空閑的內存相互交錯,那就沒有辦法簡單的進行指針碰撞了,虛擬機就必須維護一個列表,記錄哪些內存塊是可用的,在分配的時候從列表中找到一塊足夠大的空間劃分給對象實例,并更新列表上的記錄,這種分配方式稱為“空閑列表”(Free List)。
選擇哪種分配方式由Java堆是否規整決定,而Java堆是否規整又由所采用的垃圾收集器是否帶有壓縮整理功能決定。因此在使用Serial、ParNew等帶Compact過程的收集器時,系統采用的分配算法是指針碰撞,而使用CMS這種基于Mark-Sweep算法的收集器時(說明一下,CMS收集器可以通過UseCMSCompactAtFullCollection或CMSFullGCsBeforeCompaction來整理內存),就通常采用空閑列表。關于垃圾收集器的具體內容將在下一篇文章中介紹。
除如何劃分可用空間之外,另外一個需要考慮的問題是對象創建在虛擬機中是非常頻繁的行為,即使是僅僅修改一個指針所指向的位置,在并發情況下也并非線程安全的,可能出現正在給對象A分配內存,指針還沒來得及修改,對象B又同時使用了原來的指針來分配內存。解決這個問題有如下兩個方案:
對分配內存空間的動作進行同步?實際上虛擬機是采用CAS配上失敗重試的方式保證更新操作的原子性。
把內存分配的動作按照線程劃分在不同的空間之中進行?即每個線程在Java堆中預先分配一小塊內存,稱為本地線程分配緩沖(TLAB ,Thread Local Allocation Buffer),哪個線程要分配內存,就在哪個線程的TLAB上分配,只有TLAB用完,分配新的TLAB時才需要同步鎖定。虛擬機是否使用TLAB,可以通過-XX:+/-UseTLAB參數來設定。
3. 初始化
內存分配完成之后,虛擬機需要將分配到的內存空間都初始化為零值(不包括對象頭),如果使用TLAB的話,這一個工作也可以提前至TLAB分配時進行。這步操作保證了對象的實例字段在Java代碼中可以不賦初始值就直接使用。
4. 設置對象頭
接下來,虛擬機要設置對象的信息(如這個對象是哪個類的實例、如何才能找到類的元數據信息、對象的哈希碼、對象的GC分代年齡等信息)并存放在對象的對象頭(Object Header)中。根據虛擬機當前的運行狀態的不同,如是否啟用偏向鎖等,對象頭會有不同的設置方式。關于對象頭的具體內容,在下一節再詳細介紹。
5. 執行<init>方法
在上面工作都完成之后,在虛擬機的視角來看,一個新的對象已經產生了。但是在Java程序的視角看來,對象創建才剛剛開始——<init>方法還沒有執行,所有的字段都還為零值。所以一般來說(由字節碼中是否跟隨有invokespecial指令所決定),new指令之后會接著執行<init>方法,把對象按照程序員的意愿進行初始化,這樣一個真正可用的對象才算完全產生出來。
HotSpot虛擬機中,對象在內存中存儲的布局可以分為三塊區域:對象頭(Header)、實例數據(Instance Data)和對齊填充(Padding)。
1. 對象頭
HotSpot虛擬機的對象頭包括兩部分信息:
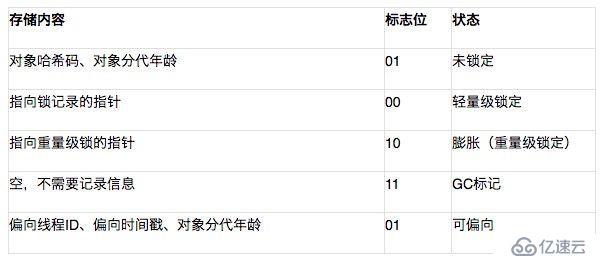
對象自身的運行時數據 “Mark Word”?如哈希碼(HashCode)、GC分代年齡、鎖狀態標志、線程持有的鎖、偏向線程ID、偏向時間戳等等,這部分數據的長度在32位和64位的虛擬機(暫不考慮開啟壓縮指針的場景)中分別為32個和64個Bits,官方稱它為“Mark Word”。對象需要存儲的運行時數據很多,其實已經超出了32、64位Bitmap結構所能記錄的限度,但是對象頭信息是與對象自身定義的數據無關的額外存儲成本,考慮到虛擬機的空間效率,Mark Word被設計成一個非固定的數據結構以便在極小的空間內存儲盡量多的信息,它會根據對象的狀態復用自己的存儲空間。例如在32位的HotSpot虛擬機中對象未被鎖定的狀態下,Mark Word的32個Bits空間中的25Bits用于存儲對象哈希碼(HashCode),4Bits用于存儲對象分代年齡,2Bits用于存儲鎖標志位,1Bit固定為0,在其他狀態(輕量級鎖定、重量級鎖定、GC標記、可偏向)下對象的存儲內容如下圖所示:
類型指針?類型指針即對象指向它的類元數據的指針,虛擬機通過這個指針來確定這個對象是哪個類的實例。并不是所有的虛擬機實現都必須在對象數據上保留類型指針,換句話說查找對象的元數據信息并不一定要經過對象本身,這點我們在下一節討論。另外,如果對象是一個Java數組,那在對象頭中還必須有一塊用于記錄數組長度的數據,因為虛擬機可以通過普通Java對象的元數據信息確定Java對象的大小,但是從數組的元數據中無法確定數組的大小。
2. 實例數據
實例數據是對象真正存儲的有效信息,也既是我們在程序代碼里面所定義的各種類型的字段內容,無論是從父類繼承下來的,還是在子類中定義的都需要記錄起來。這部分的存儲順序會受到虛擬機分配策略參數(FieldsAllocationStyle)和字段在Java源碼中定義順序的影響。HotSpot虛擬機默認的分配策略為longs/doubles、ints、shorts/chars、bytes/booleans、oops(Ordinary Object Pointers),從分配策略中可以看出,相同寬度的字段總是被分配到一起。在滿足這個前提條件的情況下,在父類中定義的變量會出現在子類之前。如果CompactFields參數值為true(默認為true),那子類之中較窄的變量也可能會插入到父類變量的空隙之中。
3. 對齊填充
對齊填充并不是必然存在的,也沒有特別的含義,它僅僅起著占位符的作用。由于HotSpot VM的自動內存管理系統要求對象起始地址必須是8字節的整數倍,換句話說就是對象的大小必須是8字節的整數倍。對象頭部分正好似8字節的倍數(1倍或者2倍),因此當對象實例數據部分沒有對齊的話,就需要通過對齊填充來補全。
我們的Java程序需要通過棧上的對象引用(reference)數據(存儲在棧上的局部變量表中)來操作堆上的具體對象。由于reference類型在Java虛擬機規范里面也只規定了是一個指向對象的引用,并沒有定義這個引用的具體實現,對象訪問方式也是取決于虛擬機實現而定的。主流的訪問方式有使用句柄和直接指針兩種。
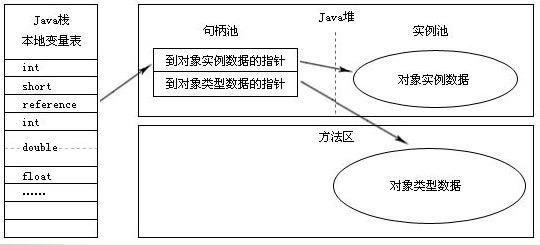
1. 使用句柄訪問
如果使用句柄訪問的話,Java堆中將會劃分出一塊內存來作為句柄池,reference中存儲的就是對象的句柄地址,而句柄中包含了對象實例數據與類型數據的各自的具體地址信息。如下圖所示:
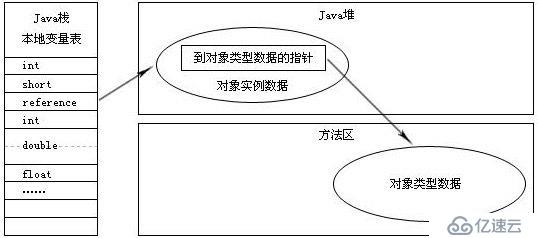
2. 使用直接指針訪問
如果使用直接指針訪問的話,Java堆對象的布局中就必須考慮如何放置訪問類型數據的相關信息,reference中存儲的直接就是對象地址,如下圖所示:
這兩種對象訪問方式各有優勢,下面分別來談一談:
句柄?使用句柄訪問的最大好處就是reference中存儲的是穩定的句柄地址,在對象被移動(垃圾收集時移動對象是非常普遍的行為)時只會改變句柄中的實例數據指針,而reference本身不需要被修改。
直接指針?使用直接指針來訪問最大的好處就是速度更快,它節省了一次指針定位的時間開銷,由于對象訪問的在Java中非常頻繁,因此這類開銷積小成多也是一項 非常可觀的執行成本。從上一部分講解的對象內存布局可以看出,HotSpot是使用直接指針進行對象訪問的,不過在整個軟件開發的范圍來 看,各種語言、框架中使用句柄來訪問的情況也十分常見。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





