溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Apache Kafka 是 LinkedIn 基礎設施的核心組件,最初是作為內部流式處理平臺而誕生的,后來被開源出來,并得到了外部的廣泛采用。雖然有很多公司和項目在使用 Kafka,但他們的數據規模很少能夠達到 LinkedIn 這樣。Kafka 被廣泛地應用在 LinkedIn 的軟件棧中,用于活動追蹤、消息交換、指標收集,等等。LinkedIn 有 100 多個 Kafka 集群,其中包含了 4000 多個 broker,總共有 10 萬多個 topic 和 700 萬個分區。截止到目前,LinkedIn 的 Kafka 集群每天處理的消息數量超過了 7 萬億條。
如此大規模的處理容量不斷給 LinkedIn 的 Kafka 生態系統帶來伸縮性和運維方面的挑戰。為了解決這方面的問題,LinkedIn 定制了一個 Kafka 版本。現在,這個分支也正式開源,并托管在 GitHub 上。這個分支的版本號與 Apache Kafka 的區別是后面加了 -li 后綴。
在這篇文章里,作者將介紹 LinkedIn 定制的 Kafka 版本的更多細節、補丁的開發流程、如何將變更傳回上游,并介紹了一些補丁的大概情況和他們如何發布新版本。
LinkedIn 的 Kafka 生態系統
基于 Apache Kafka 的流式處理生態系統是 LinkedIn 技術棧的一個關鍵組成部分。這個生態系統包含以下這些組件:
Kafka 集群;
使用了 Kafka 客戶端的應用程序;
為非 Java 客戶端提供服務的 REST 代理;
用于維護 Avro schema 的 schema 注冊表;
用于鏡像集群的 Brooklin
用于維護 Apache Kafka 集群的 Cruise Control
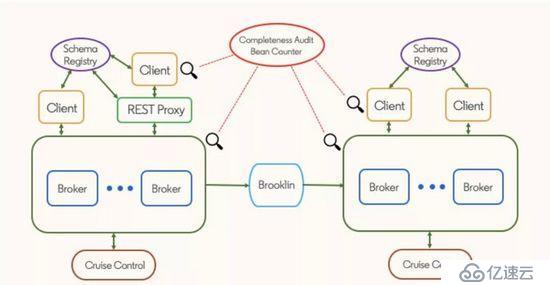
LinkedIn 的 Kafka 版本分支
正如之前所述,LinkedIn 內部的版本分支用于創建被部署在 LinkedIn 生產環境的 Kafka 版本。每一個版本分支都是從對應的 Apache Kafka 上游分支拉取出來的。畢竟,LinkedIn 并不是要對 Apache Kafka 進行 fork,只是要維護一個盡量與上游保持接近的版本。
因此,LinkedIn 通過兩種方式提交補丁。
上游優先
LinkedIn 優先(也就是緊急修復)
先提交到 LinkedIn 的版本分支;
嘗試提交到上游,但需要注意的是,提交到上游有可能因為各種原因不被接受;
除了自己創建的補丁,有時候 LinkedIn 也需要從上游擇優挑選一些補丁。因此,LinkedIn 的版本分支包含了以下幾種補丁:
Apache Kafka 補丁:提交到上游的補丁;
擇優挑選的補丁:提交到上游之后再加入當前發布版本,它們可能是內部提交到上游的,也可能是來自外部的補丁;
緊急修復補丁:先是在內部創建,然后提交到上游;
換句話說,在過了分支點之后,每個 LinkedIn 的發布版本都會有兩種補丁:優選補丁和緊急修復補丁。緊急修復補丁又包含只在 LinkedIn 內部使用和嘗試提交到上游的補丁。從下圖可以看出,盡管每一個提交補丁都會創建一個內部版本,但發布版本是按需創建的,而且可能包含多個補丁。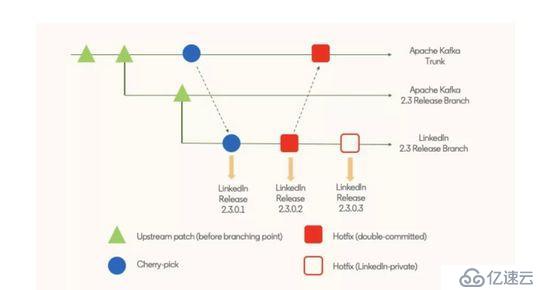
開發流程
LinkedIn 的 Kafka 補丁開發流程如下圖所示。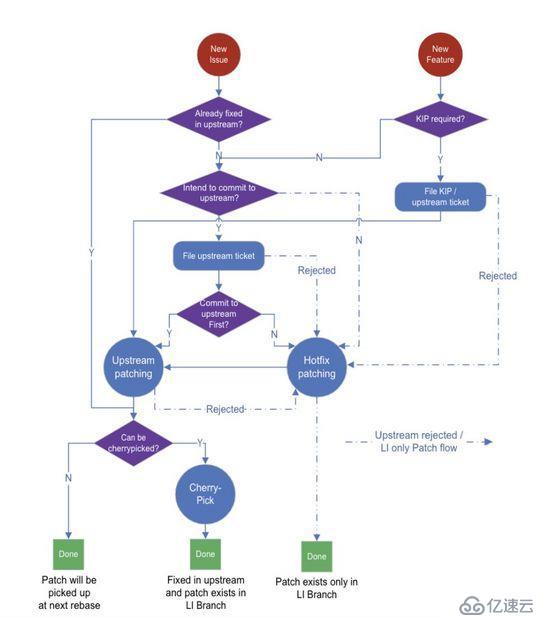
這里最關鍵的地方在于是選擇“上游優先”還是“LinkedIn 優先”(也就是圖中的“Commit to upstream first?”)。補丁開發者應該根據緊急程度慎重地做出決定。通常,用于解決生產環境問題的補丁先是作為緊急修復補丁,除非可以被快速提交到上游(比如在一周內)。有 KIP 的功能補丁應該先提交到上游。
補丁示例
下面將給出一些有代表性的補丁示例,有些已經提交到上游,有些只在 LinkedIn 內部使用。
伸縮性方面的改進
LinkedIn 內部有一些大集群,單個集群可能包含 140 多 broker 和 1 百萬個副本。因為集群規模太大,導致控制器速度變慢,或者因為內存壓力導致控制器發生故障。這些問題對生產環境造成了嚴重影響,還可能導致控制器級聯故障。LinkedIn 提供了一些緊急補丁來解決這些問題,例如,使用 UpdateMetadataRequest 對象減少控制器的內存使用,并避免打印過多的日志。
因為單個集群包含的 broker 數量比較多,單個 broker 啟動和關閉時間變慢也會導致整個集群的部署延遲嚴重增加。因此,為了保證 Kafka 集群的可用性,在部署時每次只能關掉一個 broker。為了解決這個部署問題,LinkedIn 提供了一些補丁,用于減少 broker 的啟動和關閉時間(例如,通過減少鎖競爭來縮短關閉時間)。
運維方面的改進
這些補丁主要用來解決 Kafka 的部署問題。例如,SRE 經常需要移除發生故障的 broker(例如,有些 broker 磁盤壞掉了),并向集群中加入新的 broker。在移除 broker 時需要保持同樣水準的數據冗余,以便確保數據不會丟失。SRE 需要先將副本從發生故障的 broker 中移出,但這樣做其實是很困難的,因為集群一直在創建新的 topic,新的副本有可能會被分配給發生故障的 broker。為了解決這個問題,LinkedIn 引入了維護模式。一個 broker 在進入維護模式后就不會被分配新的 topic 分區或副本。有了這個特性,就可以很容易地將一個 broker 的所有副本遷移給另一個 broker,然后把發生故障的 broker 完全關閉掉。
直接提交到上游的新特性
最近提交到上游的新特性包括 KIP-219、KIP-380、KIP-291 和 KIP-354。
還有一些在原先的 Apache Kafka 中不存在的新特性:
支持生產和消費計數,用于計費。
在創建 topic 時強制要求設定最小的副本系數,避免因為 broker 發生故障而丟失數據。
創建新的版本分支
之前已經介紹了 LinkedIn 的 Kafka 版本分支包含了哪些補丁和特性,接下來將介紹如何創建新的版本分支。首先是從 Apache Kafka 版本分支創建新的分支(例如,從 Apache Kafka 的 2.3.0 分支創建 LinkedIn Kafka 的 2.3.0.x 分支),然后將還未提交到上游的緊急修復從之前的 LinkedIn 版本分支(例如 2.0.0.x)合并到新的分支上。下圖顯示了這一過程: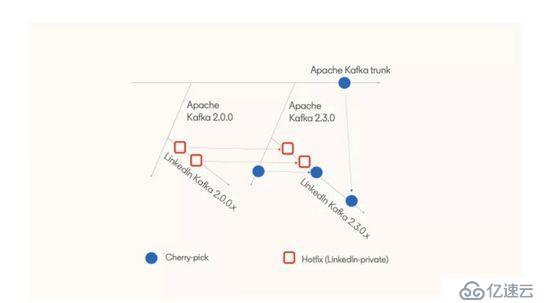
在這個過程中會在提交注釋里指明一個緊急補丁是否需要被合并到新的分支上。例如,提交注釋里可能會包含 Apache Kafka 的 ticket 號,通過這個 ticket 號就可以知道這個補丁是否已經被合并到 Apache Kafka 的分支上了。另外,Apache Kafka 分支上的補丁也會被定期擇優合并到當前的 LinkedIn Kafka 分支上。
最后,新的版本分支會有一個驗證過程。LinkedIn 使用了一個專門的驗證框架,基于真實的生產流量針對新的版本進行各種測試。驗證的項目包括再均衡、部署、回退、穩定性和降級。在通過驗證之后,就可以發布新版本了。簡單地說,LinkedIn 的每一個 Kafka 版本都會經過大規模的性能和正確性測試和驗證。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





