溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
CPU高速緩存(Cache Memory)
CPU為何要有高速緩存
CPU在摩爾定律的指導下以每18個月翻一番的速度在發展,然而內存和硬盤的發展速度遠遠不及CPU。這就造成了高性能能的內存和硬盤價格及其昂貴。然而CPU的高度運算需要高速的數據。為了解決這個問題,CPU廠商在CPU中內置了少量的高速緩存以解決I\O速度和CPU運算速度之間的不匹配問題。
在CPU訪問存儲設備時,無論是存取數據抑或存取指令,都趨于聚集在一片連續的區域中,這就被稱為局部性原理。
時間局部性(Temporal Locality):如果一個信息項正在被訪問,那么在近期它很可能還會被再次訪問。比如循環、遞歸、方法的反復調用等。
空間局部性(Spatial Locality):如果一個存儲器的位置被引用,那么將來他附近的位置也會被引用。比如順序執行的代碼、連續創建的兩個對象、數組等。

帶有高速緩存的CPU執行計算的流程
程序以及數據被加載到主內存
指令和數據被加載到CPU的高速緩存
CPU執行指令,把結果寫到高速緩存
高速緩存中的數據寫回主內存

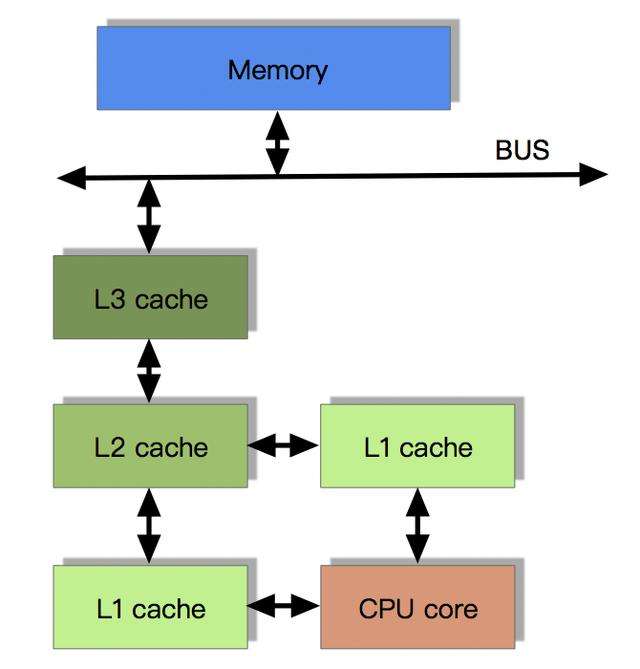
目前流行的多級緩存結構
由于CPU的運算速度超越了1級緩存的數據I\O能力,CPU廠商又引入了多級的緩存結構。
多級緩存結構
多核CPU多級緩存一致性協議MESI
多核CPU的情況下有多個一級緩存,如何保證緩存內部數據的一致,不讓系統數據混亂。這里就引出了一個一致性的協議MESI。
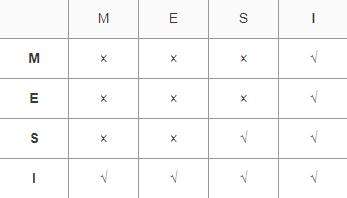
MESI協議緩存狀態
MESI 是指4中狀態的首字母。每個Cache line有4個狀態,可用2個bit表示,它們分別是:
緩存行(Cache line):緩存存儲數據的單元。

注意:
對于M和E狀態而言總是精確的,他們在和該緩存行的真正狀態是一致的,而S狀態可能是非一致的。如果一個緩存將處于S狀態的緩存行作廢了,而另一個緩存實際上可能已經獨享了該緩存行,但是該緩存卻不會將該緩存行升遷為E狀態,這是因為其它緩存不會廣播他們作廢掉該緩存行的通知,同樣由于緩存并沒有保存該緩存行的copy的數量,因此(即使有這種通知)也沒有辦法確定自己是否已經獨享了該緩存行。
從上面的意義看來E狀態是一種投機性的優化:如果一個CPU想修改一個處于S狀態的緩存行,總線事務需要將所有該緩存行的copy變成invalid狀態,而修改E狀態的緩存不需要使用總線事務。
MESI狀態轉換

理解該圖的前置說明:
1.觸發事件

2.cache分類:
前提:所有的cache共同緩存了主內存中的某一條數據。
本地cache:指當前cpu的cache。
觸發cache:觸發讀寫事件的cache。
其他cache:指既除了以上兩種之外的cache。
注意:本地的事件觸發 本地cache和觸發cache為相同。
上圖的切換解釋:

下圖示意了,當一個cache line的調整的狀態的時候,另外一個cache line 需要調整的狀態。
舉個栗子來說:
假設cache 1 中有一個變量x = 0的cache line 處于S狀態(共享)。
那么其他擁有x變量的cache 2、cache 3等x的cache line調整為S狀態(共享)或者調整為 I 狀態(無效)。
多核緩存協同操作
假設有三個CPU A、B、C,對應三個緩存分別是cache a、b、 c。在主內存中定義了x的引用值為0。

單核讀取
那么執行流程是:
CPU A發出了一條指令,從主內存中讀取x。
從主內存通過bus讀取到緩存中(遠端讀取Remote read),這是該Cache line修改為E狀態(獨享).

雙核讀取
那么執行流程是:
CPU A發出了一條指令,從主內存中讀取x。
CPU A從主內存通過bus讀取到 cache a中并將該cache line 設置為E狀態。
CPU B發出了一條指令,從主內存中讀取x。
CPU B試圖從主內存中讀取x時,CPU A檢測到了地址沖突。這時CPU A對相關數據做出響應。此時x 存儲于cache a和cache b中,x在chche a和cache b中都被設置為S狀態(共享)。

修改數據
那么執行流程是:
CPU A 計算完成后發指令需要修改x.
CPU A 將x設置為M狀態(修改)并通知緩存了x的CPU B, CPU B將本地cache b中的x設置為I狀態(無效)
CPU A 對x進行賦值。

同步數據
那么執行流程是:
CPU B 發出了要讀取x的指令。
CPU B 通知CPU A,CPU A將修改后的數據同步到主內存時cache a 修改為E(獨享)
CPU A同步CPU B的x,將cache a和同步后cache b中的x設置為S狀態(共享)。

MESI優化和他們引入的問題
緩存的一致性消息傳遞是要時間的,這就使其切換時會產生延遲。當一個緩存被切換狀態時其他緩存收到消息完成各自的切換并且發出回應消息這么一長串的時間中CPU都會等待所有緩存響應完成。可能出現的阻塞都會導致各種各樣的性能問題和穩定性問題。
CPU切換狀態阻塞解決-存儲緩存(Store Bufferes)
比如你需要修改本地緩存中的一條信息,那么你必須將I(無效)狀態通知到其他擁有該緩存數據的CPU緩存中,并且等待確認。等待確認的過程會阻塞處理器,這會降低處理器的性能。應為這個等待遠遠比一個指令的執行時間長的多。
Store Bufferes
為了避免這種CPU運算能力的浪費,Store Bufferes被引入使用。處理器把它想要寫入到主存的值寫到緩存,然后繼續去處理其他事情。當所有失效確認(Invalidate Acknowledge)都接收到時,數據才會最終被提交。
這么做有兩個風險
Store Bufferes的風險
第一、就是處理器會嘗試從存儲緩存(Store buffer)中讀取值,但它還沒有進行提交。這個的解決方案稱為Store Forwarding,它使得加載的時候,如果存儲緩存中存在,則進行返回。
第二、保存什么時候會完成,這個并沒有任何保證。
alue?=?3;
void?exeToCPUA(){
??value?=?10;
??isFinsh?=?true;
}
void?exeToCPUB(){
??if(isFinsh){
????//value一定等于10?!
????assert?value?==?10;
??}
}試想一下開始執行時,CPU A保存著finished在E(獨享)狀態,而value并沒有保存在它的緩存中。(例如,Invalid)。在這種情況下,value會比finished更遲地拋棄存儲緩存。完全有可能CPU B讀取finished的值為true,而value的值不等于10。
即isFinsh的賦值在value賦值之前。
這種在可識別的行為中發生的變化稱為重排序(reordings)。注意,這不意味著你的指令的位置被惡意(或者好意)地更改。
它只是意味著其他的CPU會讀到跟程序中寫入的順序不一樣的結果。
順便提一下NIO的設計和Store Bufferes的設計是非常相像的。
硬件內存模型
執行失效也不是一個簡單的操作,它需要處理器去處理。另外,存儲緩存(Store Buffers)并不是無窮大的,所以處理器有時需要等待失效確認的返回。這兩個操作都會使得性能大幅降低。為了應付這種情況,引入了失效隊列。它們的約定如下:
對于所有的收到的Invalidate請求,Invalidate Acknowlege消息必須立刻發送
Invalidate并不真正執行,而是被放在一個特殊的隊列中,在方便的時候才會去執行。
處理器不會發送任何消息給所處理的緩存條目,直到它處理Invalidate。
即便是這樣處理器已然不知道什么時候優化是允許的,而什么時候并不允許。
干脆處理器將這個任務丟給了寫代碼的人。這就是內存屏障(Memory Barriers)。歡迎大家關注我的公種浩【程序員追風】,整理了1000道2019年多家公司java面試題400多頁pdf文檔,文章都會在里面更新,整理的資料也會放在里面。

寫屏障 Store Memory Barrier(a.k.a. ST, SMB, smp_wmb)是一條告訴處理器在執行這之后的指令之前,應用所有已經在存儲緩存(store buffer)中的保存的指令。
讀屏障Load Memory Barrier (a.k.a. LD, RMB, smp_rmb)是一條告訴處理器在執行任何的加載前,先應用所有已經在失效隊列中的失效操作的指令。
void?executedOnCpu0()?{
????value?=?10;
????//在更新數據之前必須將所有存儲緩存(store?buffer)中的指令執行完畢。
????storeMemoryBarrier();
????finished?=?true;
}
void?executedOnCpu1()?{
????while(!finished);
????//在讀取之前將所有失效隊列中關于該數據的指令執行完畢。
????loadMemoryBarrier();
????assert?value?==?10;
}最后
歡迎大家一起交流,喜歡文章記得點個贊喲,感謝支持!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





