溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
想入門一下Kafka的(裝一下環境、看看Kafka一些概念啥的)。后來發現Kafka用到了ZooKeeper,而我又對ZooKeeper不了解,所以想先來學學什么是ZooKeeper,再去看看什么是Kafka。
ZooKeeper相信大家已經聽過這個詞了,不知道大家對他了解多少呢?我第一次聽到ZooKeeper的時候是在學Eureka的時候,同樣ZooKeeper也可以作為注冊中心。
后面聽到ZooKeeper的時候,是因為ZooKeeper可以作為分布式鎖的一種實現。
直至在了解Kafka的時候,發現Kafka也需要依賴ZooKeeper。Kafka使用ZooKeeper管理自己的元數據配置。
這篇文章來寫寫我學習ZooKeeper的筆記,如果有錯的地方希望大家可以在評論區指出。
從上面我們也可以發現,好像哪都有ZooKeeper的身影,那什么是ZooKeeper呢?我們先去官網看看介紹:

官網還有另一段話:
ZooKeeper:?A?Distributed?Coordination?Service?for?Distributed?Applications
相比于官網的介紹,我其實更喜歡Wiki中對ZooKeeper的介紹:
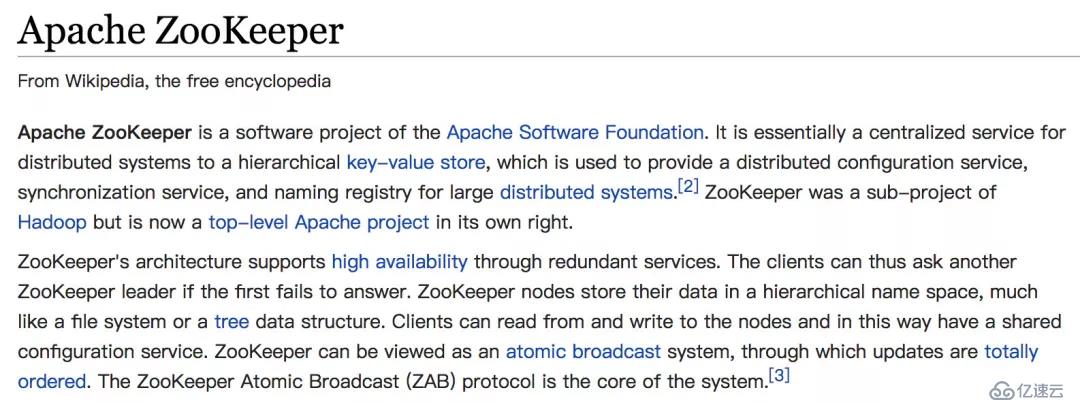
(留下不懂英語的淚水)
我簡單概括一下:
ZooKeeper主要服務于分布式系統,可以用ZooKeeper來做:統一配置管理、統一命名服務、分布式鎖、集群管理。
從上面我們可以知道,可以用ZooKeeper來做:統一配置管理、統一命名服務、分布式鎖、集群管理。
統一配置管理、統一命名服務、分布式鎖、集群管理每個具體的含義(后面會講)那為什么ZooKeeper可以干那么多事?來看看ZooKeeper究竟是何方神物,在Wiki中其實也有提到:
ZooKeeper nodes store their data in a hierarchical name space, much like a file system or a tree data structure
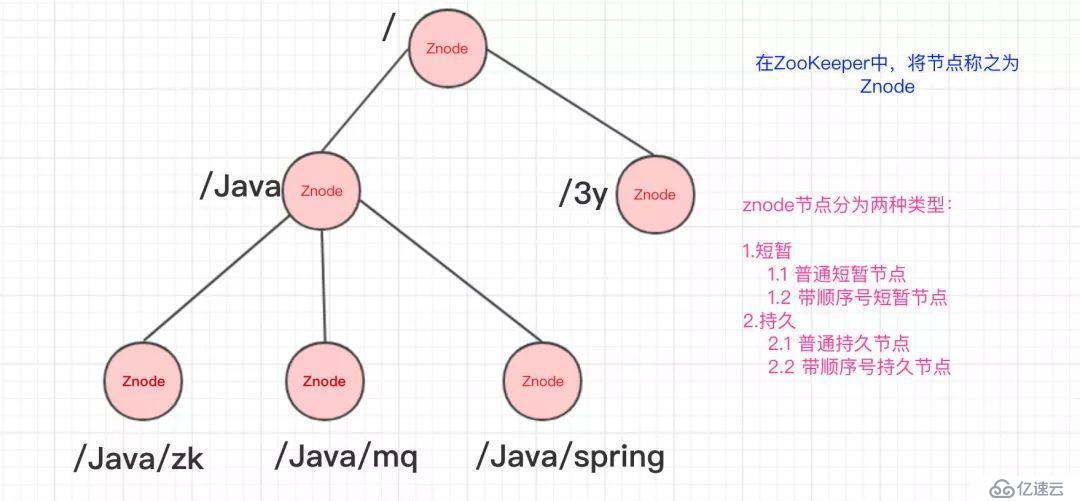
ZooKeeper的數據結構,跟Unix文件系統非常類似,可以看做是一顆樹,每個節點叫做ZNode。每一個節點可以通過路徑來標識,結構圖如下:
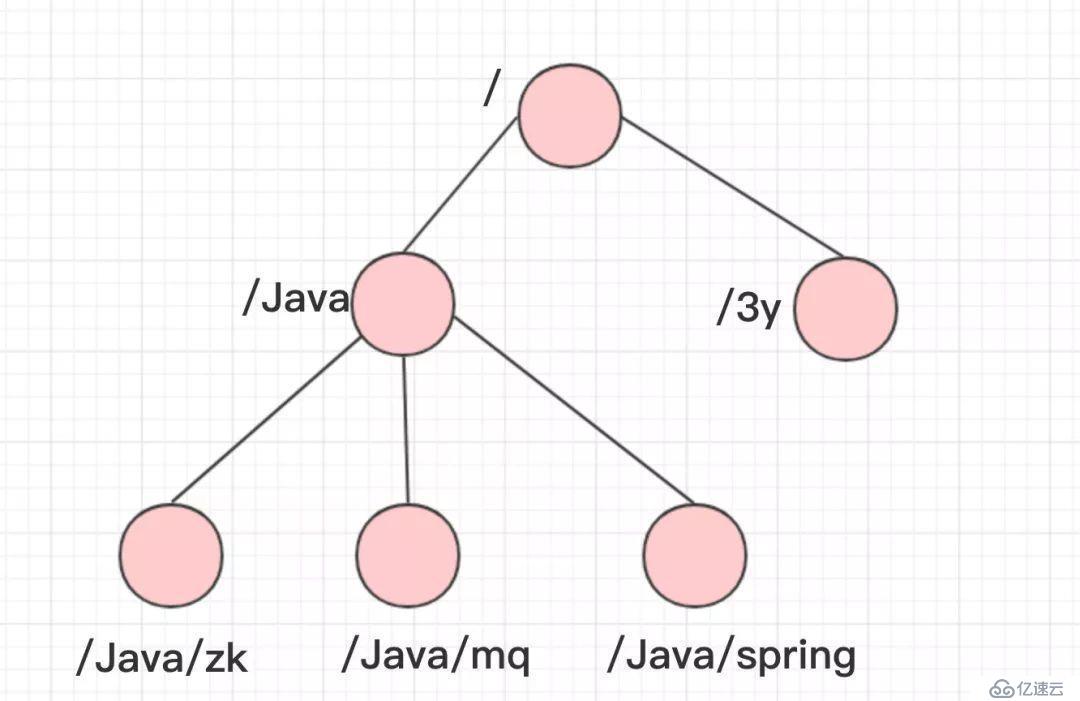
那ZooKeeper這顆"樹"有什么特點呢??ZooKeeper的節點我們稱之為Znode,Znode分為兩種類型:
短暫/臨時(Ephemeral):當客戶端和服務端斷開連接后,所創建的Znode(節點)會自動刪除
ZooKeeper和Redis一樣,也是C/S結構(分成客戶端和服務端)
在上面我們已經簡單知道了ZooKeeper的數據結構了,ZooKeeper還配合了監聽器才能夠做那么多事的。
常見的監聽場景有以下兩項:
監聽Znode節點的數據變化
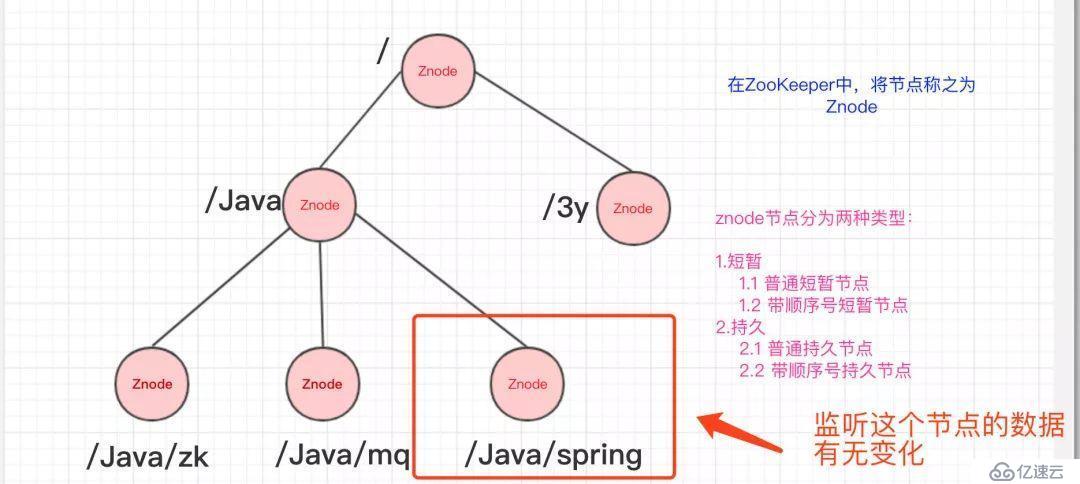
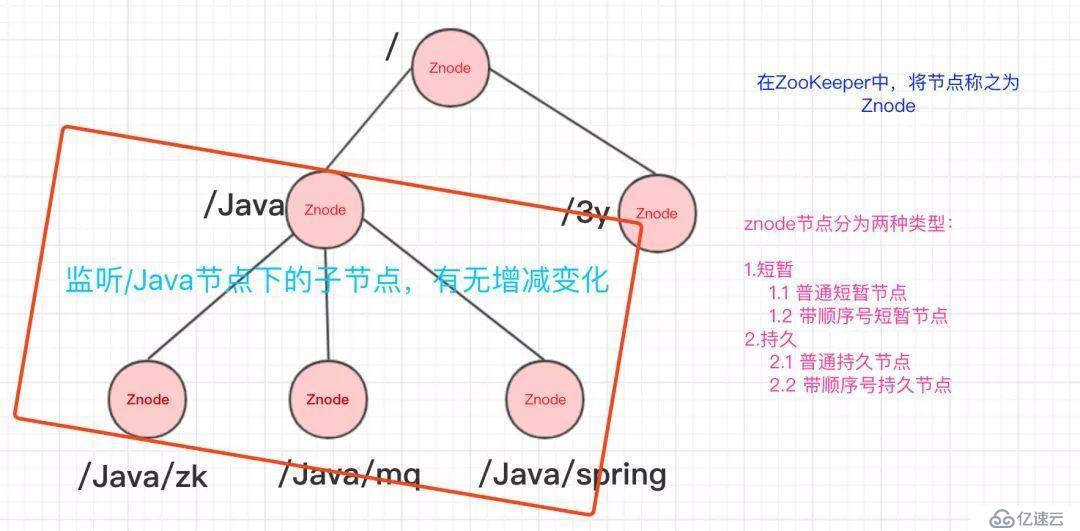
沒錯,通過監聽+Znode節點(持久/短暫[臨時]),ZooKeeper就可以玩出這么多花樣了。
下面我們來看看用ZooKeeper怎么來做:統一配置管理、統一命名服務、分布式鎖、集群管理。
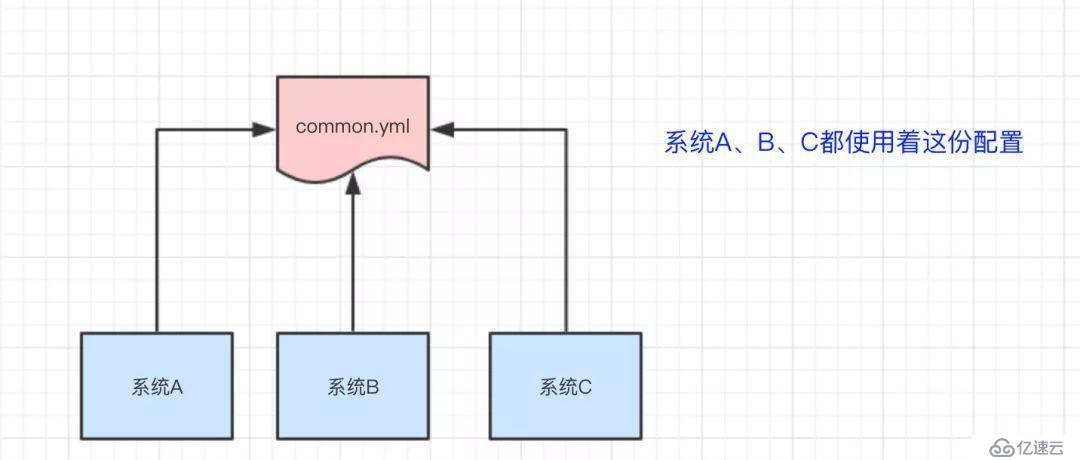
比如我們現在有三個系統A、B、C,他們有三份配置,分別是ASystem.yml、BSystem.yml、CSystem.yml,然后,這三份配置又非常類似,很多的配置項幾乎都一樣。
于是,我們希望把ASystem.yml、BSystem.yml、CSystem.yml相同的配置項抽取出來成一份公用的配置common.yml,并且即便common.yml改了,也不需要系統A、B、C重啟。
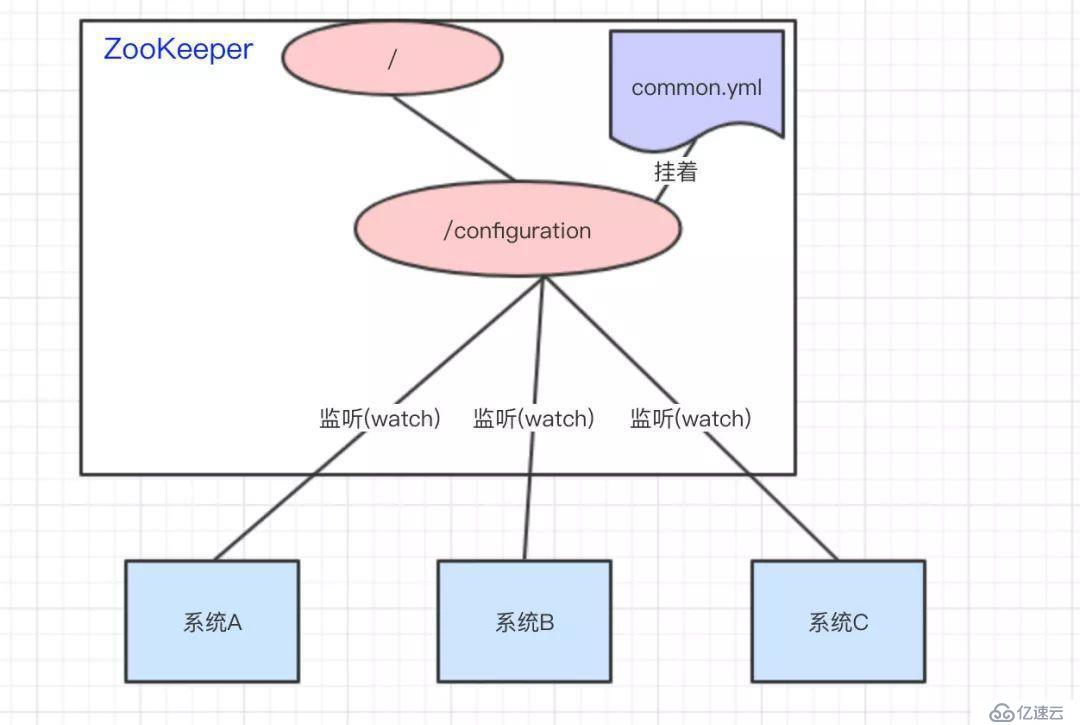
做法:我們可以將common.yml這份配置放在ZooKeeper的Znode節點中,系統A、B、C監聽著這個Znode節點有無變更,如果變更了,及時響應。
參考資料:
基于zookeeper實現統一配置管理
統一命名服務的理解其實跟域名一樣,是我們為這某一部分的資源給它取一個名字,別人通過這個名字就可以拿到對應的資源。
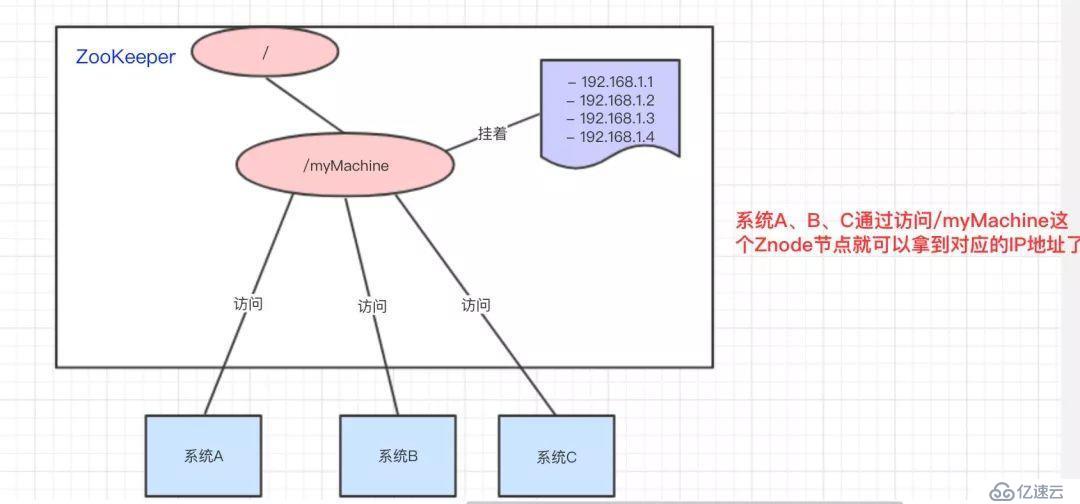
比如說,現在我有一個域名www.java3y.com,但我這個域名下有多臺機器:
192.168.1.1
192.168.1.2
192.168.1.3
別人訪問www.java3y.com即可訪問到我的機器,而不是通過IP去訪問。
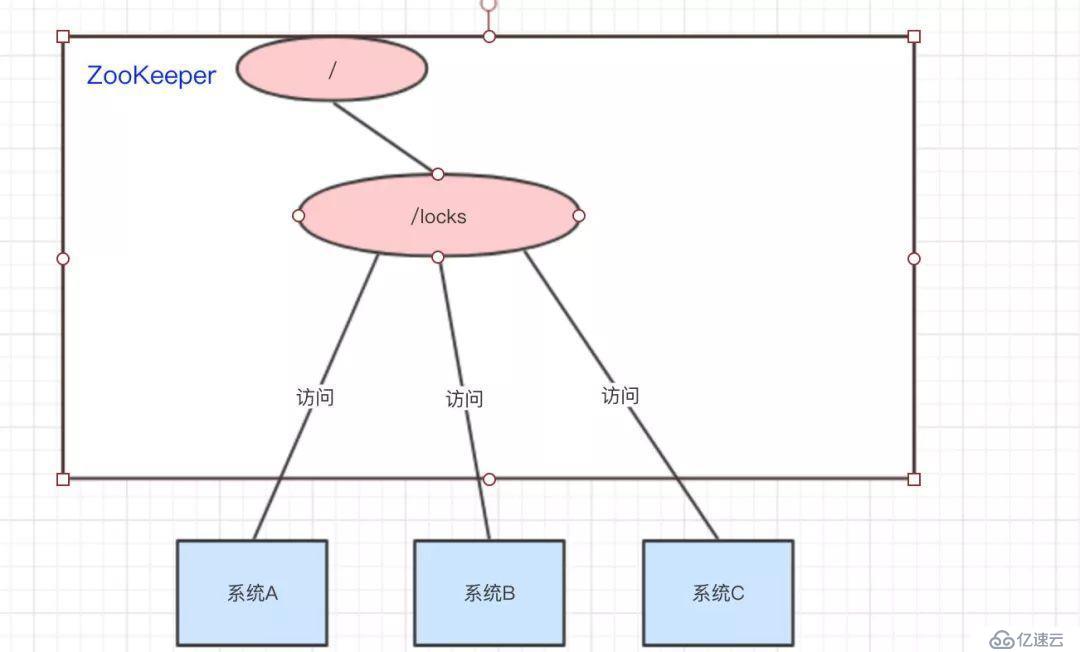
我們可以使用ZooKeeper來實現分布式鎖,那是怎么做的呢??下面來看看:
系統A、B、C都去訪問/locks節點
訪問的時候會創建帶順序號的臨時/短暫(EPHEMERAL_SEQUENTIAL)節點,比如,系統A創建了id_000000節點,系統B創建了id_000002節點,系統C創建了id_000001節點。
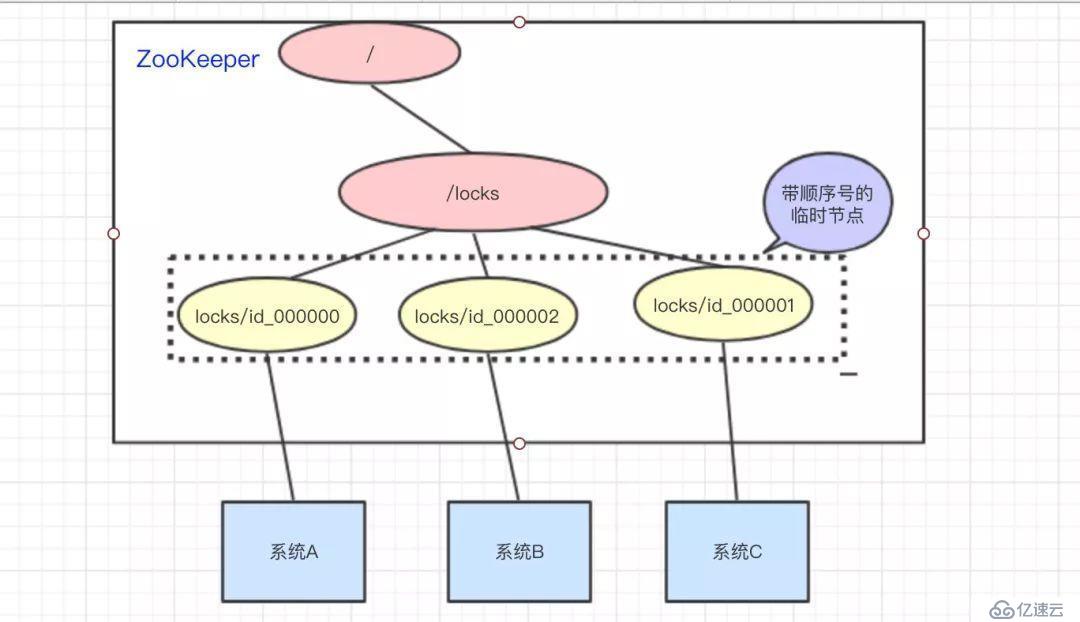
接著,拿到/locks節點下的所有子節點(id_000000,id_000001,id_000002),判斷自己創建的是不是最小的那個節點
如果是,則拿到鎖。
釋放鎖:執行完操作后,把創建的節點給刪掉
舉個例子:
系統A拿到/locks節點下的所有子節點,經過比較,發現自己(id_000000),是所有子節點最小的。所以得到鎖
系統B拿到/locks節點下的所有子節點,經過比較,發現自己(id_000002),不是所有子節點最小的。所以監聽比自己小1的節點id_000001的狀態
系統C拿到/locks節點下的所有子節點,經過比較,發現自己(id_000001),不是所有子節點最小的。所以監聽比自己小1的節點id_000000的狀態
……
等到系統A執行完操作以后,將自己創建的節點刪除(id_000000)。通過監聽,系統C發現id_000000節點已經刪除了,發現自己已經是最小的節點了,于是順利拿到鎖
經過上面幾個例子,我相信大家也很容易想到ZooKeeper是怎么"感知"節點的動態新增或者刪除的了。
還是以我們三個系統A、B、C為例,在ZooKeeper中創建臨時節點即可:
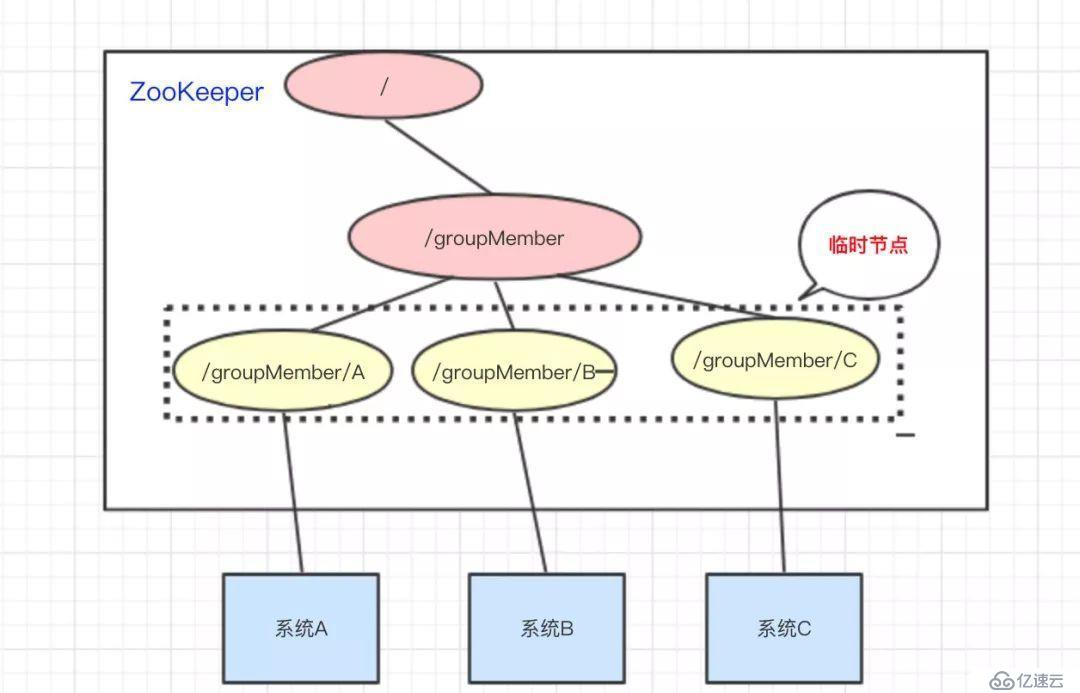
只要系統A掛了,那/groupMember/A這個節點就會刪除,通過監聽groupMember下的子節點,系統B和C就能夠感知到系統A已經掛了。(新增也是同理)
除了能夠感知節點的上下線變化,ZooKeeper還可以實現動態選舉Master的功能。(如果集群是主從架構模式下)
原理也很簡單,如果想要實現動態選舉Master的功能,Znode節點的類型是帶順序號的臨時節點(EPHEMERAL_SEQUENTIAL)就好了。
這篇文章主要講解了ZooKeeper的入門相關的知識,ZooKeeper通過Znode的節點類型+監聽機制就實現那么多好用的功能了!
當然了,ZooKeeper要考慮的事沒那么簡單的,后面有機會深入的話,我還會繼續分享,希望這篇文章對大家有所幫助~
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





