溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
工作的這些年發現一個比較奇怪的現象就是身邊無論是工作十多年的老兵,還是初級剛入行的程序員,在高談闊論技術和趨勢的時候都是人工智能,大數據,區塊鏈,各種框架,語言,算法,AI,BI,CI,DI…… 等等,倒是發現很少有人關注數據庫,不知道是因為數據庫感覺太低端還是太低調,總是不容易被人提起
技術就是這樣,不太關注的地方就不會重視,越是不被重視的地方,掉進坑里的概率就會越大,所以就在這里給大家簡單聊聊在使用數據庫過程中有哪些防掉坑指南,也可以對剛入行的小朋友有一個提醒的作用,萬丈高樓平地起,一定要先打好基礎再去考慮上層的建筑,不要舍本逐末
本章主要分以下四個小節(預計讀完 5 分鐘左右):
很多人在開發過程中不太關注數據庫,對于表結構的設計也沒什么講究大多屬于“能用就行”,但是根據作者將近十年的開發經驗來看的話,只要你是從事 Web 相關領域開發你就無法避免不和數據庫打交道,在Web開發中大多功能操作本質上都是對數據庫進行操作,不管你用是 Pythod,Java,Ruby 等語言進行 Web 開發,你其實都是在面向數據庫進行編程,很多 Web 框架作者為了避免程序員接觸數據庫的相關知識甚至還封裝了一層 ORM (Object Relational Mapping 對象關系映射),把數據庫當做一個黑盒子,然后通過操作對象的形式來操作數據庫
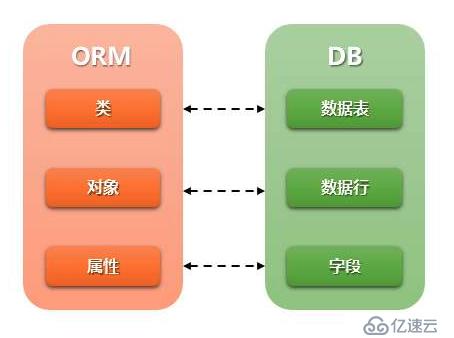
雖然某種意義上是簡化的開發,對此我是持有保留意見的,因為對于程序員來說很有必要了解你的 SQL 語言在數據庫是怎么執行的,你不僅需要使用 explain 執行計劃來查看你的 SQL 是否高效(掃描行數,命中索引,回表,排序等),對比不同 SQL 的寫法外,你還需要知道如何使用 show index 來查看你的索引是否高效(通過 Cardinality 由數據庫評估),這些技巧很大程度依賴你對 SQL 的了解,SQL 對于程序員來說也是一門非常重要的技能,沒錯 SQL 就是操作數據庫的語言,據我了解大多數的公司在面試的時候都會考察程序員的 SQL 功底,扎實的 SQL 功底不僅可以讓你寫出高性能的查詢語言外,對于數據分析,報表統計也是有非常大的幫助
大多數商業公司的核心資產其實就是數據庫里面的數據,是非常寶貴的財富,程序和系統掛了,最多就是一段時間不可用,大多是情況重啟就可以恢復,但是是數據庫不小心被誤刪了,如果是運維能力差的中小企業可能會面臨倒閉的地步,從商業角度上來說數據庫大多數軟件公司的核心
很多程序員從菜鳥成長到高手,接觸的項目從學校的"某某管理系統"到剛加入公司內部系統,然后再到大型分布式系統,在大型系統中,大多數人程序員通常遇到的第一個問題通常不是線程不夠用,不是CPU負載過高,不是內存不夠快,通常都是數據庫扛不住壓力了,為什么呢?數據庫本身就基于磁盤的文件系統,每次讀取數據都是通過 I/O 去訪問磁盤,了解計算機原理的同學應該都知道,在馮諾依曼計算機體系結構里磁盤 I/O 號稱是最慢的 I/O (毫秒級),通常在你的系統只有幾千上萬的數據量時,全表掃描通常不會有很大的延遲感,但是當你的存量數據達到百萬千萬時,那么一次普通的查詢就會把你的數據庫服務器撐爆,做過應用的人都知道,數據庫掛了,不管是什么分布式,微服務的牛逼架構都基本沒啥用了,嘮嘮叨叨說到這里,相信大家應該已經知道數據庫的重要性的,后面我們再從數據庫設計的角度來看下問題
這里我們簡單做一個對比,良好的數據庫設計可以為你帶來什么 ?
糟糕的設計 ?

糟糕的設計(圖)
比如說對于一個簡單的年齡字段,嚴謹來說應該使用 tinyint(1字節)或者 smallint(2字節),但是你偏偏要用 int (4字節) 這就屬于糟糕的字段選擇,看到這里很多剛入門的同學就可能就會反駁了,這么在意空間利用是不是有點矯枉過正?包括存儲已經很便宜了,還這么斤斤計較般的選擇,反正最終實現的功能都是相同的,別人也看不出什么差別呀。對于這種觀點其實我想反駁一下,這是典型的新手思維,你只在看到在單個字段上的空間節省,但是沒有考慮過數據也是在持續增長,糟糕的設計越到后期增長成本會越高(這里就類似于 Java 的經典面試題,集合類 ArrayList 和 LinkedList 在少量數據對比時看不出時間上的差距,但是隨著計算數據量的上升,消耗數據的差距也會越拉越大),等到了千萬級數據量的時候,可能你設計的表和別人設計的表是相同的內容,但是你的表無端的多出幾百G的存儲空間,如果你的應用還是多數據中心的話,那么這種無端的空間浪費還會被拷貝幾十倍到不同的數據中心,而且只要你的應用還在線上運行,那么這種增長所帶來的成本還會持續上升,這里也僅僅只是說對空間的浪費,下面在分析表結構存儲上,還會具體說一下糟糕的設計對于性能會有多大的影響,這對企業來說就是邊際成本的遞增,從技術和架構上來說就會讓你的系統不具備可擴展性
MySQL 的開放性架構設計兼容了很多不種類的存儲引擎(要是你足夠厲害的話,也可以自己寫一套存儲引擎),存儲引擎的設計初衷就是應對不同類型的數據倉庫,工作中有見過不管什么表都直接用 Innodb(MySQL 5.0 的默認存儲引擎,雖然大多數場景是不錯的選擇,但不是所有類型的表結構都適用)也見過根本不知道什么是存儲引擎的同學,如果這些同學來設計數據庫的話,那么你的系統就很容易踩到坑,出現很多你自己的預料不到的問題,合理的存儲引擎的選擇是應該結合實際業務場景,從目前最主流的 MySQL 來說,最常用的存儲引擎主要是 MyISAM, Innodb,當然還有很多其他的存儲引擎,例如 NDB(集群存儲引擎),Memory(基于內存的存儲引擎),Archive(歸檔存儲引擎),因為這些平時使用不多,并不主流,工作中也很少用得到,意義不大,所以就不展開來講,這里主要簡單將下 MyISAM,Innodb 的區別,主要有以下特點:
MyISAM
Innodb
因為不了解數據庫的基本原理,所以很多初級程序員在選擇數據庫字段類型的時候比較迷茫,主要還是沒有明確指導原則,工作中我見過在只有十幾條數據的基礎信息表中使用 long(8字節)作為 id 主鍵類型,還有就像上面說的狀態類型字段只有 0,1 值的字段使用 int (4字節),還見過字符類型字段統一使用 varchar(255),數值類型字段統一使用 int,這種不基于數據庫原理規則去隨意選擇字段的行為也只會出現在你 LocalHost 里的一些小項目或者玩具,基本上不了什么大臺面
據我所知,主流的數據庫大多都提供非常豐富的字段類型給開發者使用,老司機都是基于業務類型的判斷從而選擇合適的字段類型,最終收獲的是性能(時間)和存儲(空間)都非常低的高性能數據庫,具體數據庫有哪些字段類型,文章里面就不多數了,這方面的資料簡直太多了,有興趣的小伙伴可以自己去搜索,例如這里 MySQL Data Types,那么對于新手而言如何選擇字段類型呢?
簡單的基本原則如下:(后面會具體將原因)
遵循基本規范能帶來什么好處?
為什么要把“選擇盡可能小的字段”作為基本原則?我們可以先看下 innodb 的邏輯存儲結構
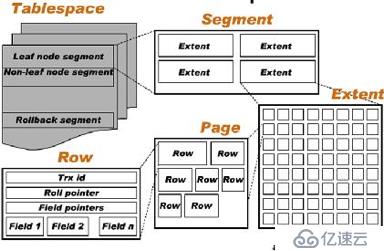
innodb 邏輯存儲結構(圖)
innodb 的存儲結構如下:
上圖可以看到讀取最小單元 Page,匹配的數據都是從 Page 里面取出,按照這個簡單的邏輯來說頁中存儲的行數據越多,數據庫的性能就越高,怎么算出來的呢?按最小類型 2B 來計算 Row,那么 Page 的默認大小(16KB)是可以匹配到 7992 行記錄,相反,如果你的 Row 行數據過大,假如一行 32 KB,那么數據庫就需要 2 個連續的 Page 來保存你一行的數據,那么性能可想而知會有多低,前后性能差距差不多 1.6 萬倍,這塊也不深入講了,有興趣的小伙伴推薦去閱讀經典書籍,這里的內容也只是書里的冰山一角
索引是一種用空間換時間的優化手段,是數據庫最重要的優化手段,也是最后的殺手锏,索引是否高效取決數據庫設計是否良好,字段類型選擇是否合理,索引是一把雙刃劍,在提升檢索速度的時候,也會減低插入,修改的性能(維護索引樹的開銷),在工作中這些年面試了不下幾百人發現能把數據庫索引原理講明白的候選人非常的少,大多數情況下我們說索引通常默認指的是 BTREE 索引,BTREE 結構是特意為磁盤 I/O 這種緩慢的讀取存儲設計的數據結構,是一棵多路多叉樹,和二叉樹相反,每層的元素非常多,但是樹的高度很矮(通常不會超過三層),從而可以保證最多不超過三次磁盤 I/O 即可定位到匹配的元素,所以說 BTREE 是一種非常適合磁盤的數據結構,也是 MySQL 默認索引類型是 BREE 的原因,如果能把這塊吃透的話,那么去面試肯定是很大的加分項,索引在數據庫可以簡單參考下圖:
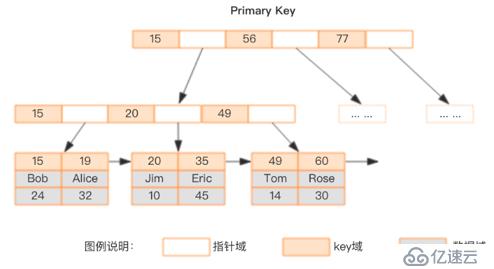
簡單說了下索引的結構,那么新手程序員在使用數據庫所以的時候可以遵循以下原則:
索引這塊可以玩的還有很多,例如如何通過 SHOW INDEX 查看數據庫為索引做出的評級(通過 Cardinality 統計),通過 Explain 查看 SQL 是否命中索引,rows 列可以看到 SQL 掃描的數據行數,Extra 列還可以查看索引匹配的類型,例如 Using index 代表完全匹配索引(無需回到 Primary Key 表查詢數據,也稱回表,甚至直接使用索引的排序,無需排序)往往說明性能不錯,Using temporary 代表查詢有使用臨時表,一般出現于排序,多表 join 的情況,查詢效率不高,建議優化
人生總會遇到很多坑,與其自己去踩坑不如去總結別人踩過的坑,自己少走一些彎路也許可以更快的成功,這里是最后一章,不想把文章拉的太長,所以我在這里就直接拋出結論,不會再說明原因,如果對數據庫有興趣推薦看到最后我推薦的書籍
避免使用觸發器/存儲過程
避免使用預留字段
反范式設計
盡量避免使用 Null 字段
關于常見的數據庫避坑指南就分享到這里了,當然并不止以上和大家分析的辦法,不過小編可以保證其準確性是絕對沒問題的。希望以上內容可以對大家有一定的參考價值,可以學以致用。如果喜歡本篇文章,不妨把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





