溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
一、Nagios概述
1、簡介
Nagios是插件式的結構,它本身沒有任何監控功能,所有的監控都是通過插件進行的,因此其是高度模塊化和富于彈性的。Nagios監控的對象可分為兩類:主機和服務。主機通常指的是物理主機,如服務器、路由器、工作站和打印機等,這里的主機也可以是虛擬設備,如xen虛擬出的Linux系統;而服務通常指某個特定的功能,如提供http服務的httpd進程等。而為了管理上的方便,主機和服務還可以分別被規劃為主機組和服務組等。
Nagios不監控任何具體數值指標(如操作系統上的進程個數),它僅用四種抽象屬性對被監控對象的狀態進行描述:OK、WARNING,CRITICAL和UNKNOWN。于是,管理員只需要對某種被監控對象的WARNING和CRITICAL狀態的閾值進行關注和定義即可。Nagios通過將WARNING和CRITCAL的閾值傳遞給插件,并由插件負責某具體對象的監控及結果分析,其輸出信息為狀態信息(OK,WARNING,CRITICAL或UNKOWN)以及一些附加的詳細說明信息。
2、特性
由上述說明可以,Nagios是極富彈性的,其監控功能完全可以按照管理員的期望進行。此外,它外提供了對問題的自動響應能力和一個功能強大的通知系統。所有這些功能的實現是基于一個結構明晰的對象定義系統和少數幾個對象類型實現的。
1) 命令(Commands)
“命令”用于定義Nagios如何執行某特定的監控工作。它是基于某特定的Nagios插件定義出的一個抽象層,通常包含一組要執行的操作。
2)時段(Time periods)
“時段”用于定義某“操作”可以執行或不能執行的日期和時間跨度,如工作日內的每天8:00-18:00等;
3)聯系人和聯系人組(Contactsand contact groups)
“聯系人”用于定義某監控事件的通知對象、要通知的信息以及這些接收通知者何時及如何接收通知;一個或多個聯系人可以定義為聯系人組,而一個聯系人也可以屬于多個組;
4) 主機和主機組(host andhost groups)
“主機”通常指某物理主機,其包括此主機相關的通知信息的接收者(即聯系人)、如何及何時進行監控的定義。主機也可以分組,即主機組(hostgroups),一個主機可同時屬于多個組;
5) 服務(Services)
“服務”通常指某主機上可被監控的特定的功能或資源,其包括此服務相關的通知信息的接收者、如何及何時進行監控等。服務也可以分組,即服務組(Serviceg
roups),一個服務可同時屬于多個服務組;
3、依賴關系
Nagios的強大功能還表現在其成熟的依賴關系系統上。比如,某路由設備故障必然會導致關聯在其上的其它主機無法被正常訪問,如果不能定義這些設備間的依賴關系,那么監控系統上必然會出現大量的設備故障信息。而Nagios則通過依賴關系來描述網絡設備的拓撲結構,并能夠實現在某設備故障時不再對依賴于此設備的其它設備進行檢測,從而避免了無謂的故障信息,方便管理員及時定位并排除故障。此外,Nagios的依賴關系還可以在服務級別上實現,如果某服務依賴于其它服務時,也能實現類似主機依賴關系的功能。
4、宏
Nagios還能夠使用宏,并且宏的定義在整個Nagios系統中具有一致性。宏是能夠用于對象定義中的變量,其值通常依賴于上下文。在“命令”中定義的宏,相對于主機、服務或其它許多參數來說,其值會隨之不同。比如,某命令可以根據向其傳遞的IP地址的不同來監控不同的主機。
5、計劃中宕機
Nagios還提供了調度性計劃中的宕機機制,管理員可以周期性的設定某主機或服務為計劃中的不可用狀態。這種功能可以阻止Nagios在調度宕機時段通知任何信息。當然,這也可以讓Nagios自動通知管理員該進行主機或服務維護了。
6、軟狀態和硬狀態(Soft andHard States)
如上所述,Nagios的主要工作是檢測主機或服務的狀態,并將其存儲下來。某一時刻,主機或服務狀態僅可以是四種可用狀態之一,因此,其狀態能夠正確反映主機或服務的實際狀況就顯得特別關鍵。為了避免某偶然的臨時性或隨機性問題,Nagios引入了軟狀態和硬狀態。在實際的檢測中,Nagios一旦發現某主機或服務的狀態為UNKOWN或不同于上一次檢測時的狀態,其將會對此主機或服務進行多次測試以確保此狀態的變動是非偶然性的。具體共要做出幾次測試是可以配置的,在這個指定次數的測試時段內,Nagios假設此變化后的狀態為軟狀態。一旦測試完成后狀態仍然為新變的狀態時,此狀態就成了硬狀態。
Nagios工作模式:
組織架構:
Nagios各組件調用:
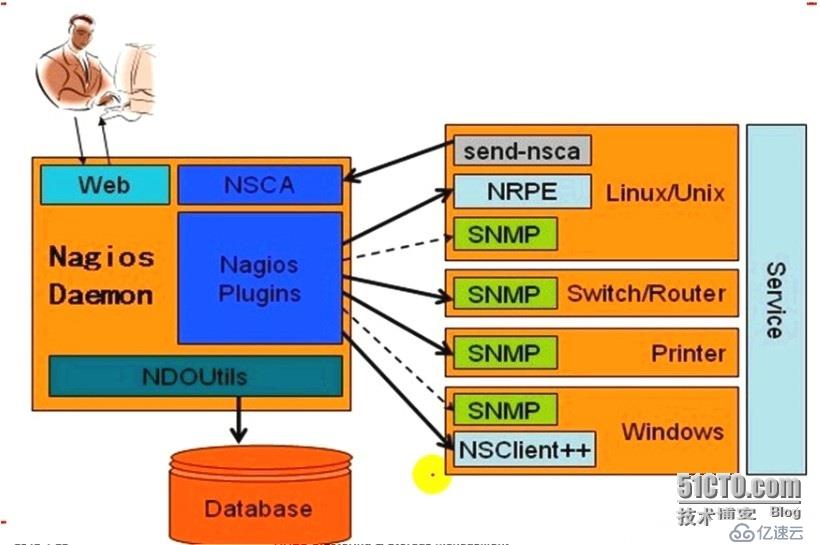
Nagios支持的插件類型:
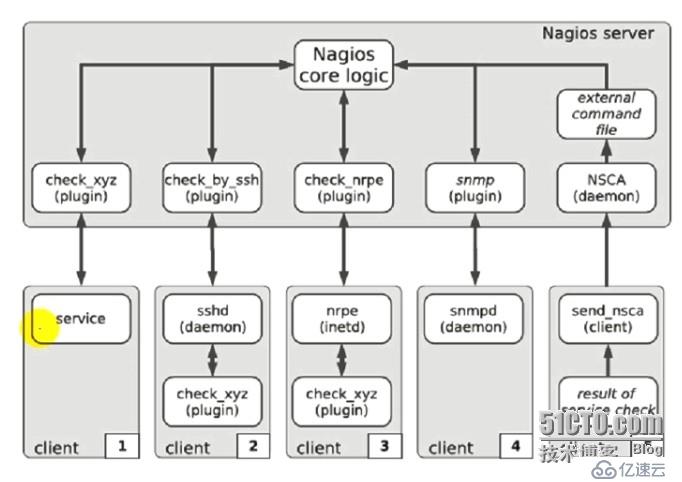
可以對插件進行分類:
1、ssh類的插件:客戶端需要運行sshd進程,然后nagios發送ssh類的命令到客戶端,客戶端把獲得的信息返回給ssh類的插件,ssh類插件通過分析把結果返給Nagios核心,核心決定是否對分析結果進行報警。
2、nrpe類的插件:專門用于監控linux、unix主機的機制,需要在客戶端上安裝nrpe服務進程,服務需要運行起來,而且nrpe需要裝上各種nagios的插件,這種插件在本地實現運行,然后收集的信息本地實現分析,分析以后由客戶端的nrpe發送到服務端的nrpe,然后再有服務端的nrpe發送給Nagios核心,核心再決定是否對分析結果進行報警。這種機制比較特殊,nagios的服務端和客戶端有一層nrpe的客戶端和服務端的架構,nrpe的服務端安裝在nagios的客戶端上,nrpe的客戶端安裝在nagios的服務端上,nrpe的客戶端可以發送指令給nrpe的服務端,讓服務端幫忙監控指定的資源,通過插件來監控指定的資源;實際上windows也可以使用類似于nrpe的機制來實現監控,但是他不叫nrpe,而叫NSClient++,專門裝在windows上的客戶端工具,這個工具在windows上運行起來以后,也可以實現nagios和window是通信,來獲取windows上的資源來實現監控,NSClient++是一個windows上的wmi組件,可以實現獲得windows上的性能狀態數據,并把這個數據返回給nagios服務端上的插件,然后再由插件返回給nagios核心,最終實現結果監控。
3、snmp類的插件:和cacti的機制一樣,在nagios的客戶上上運行snmp的服務進程,然后nagios服務端使用snmp的命令來獲取nagios客戶端的信息,然后返回給Nagios核心,這個只針對支持snmp的,nagios并不優先使用snmp協議。
4、nsca類的插件:nagios上的被動監控機制,等待客戶端返回信息給服務端,nagios并不主動收集信息;nsca服務端運行在nagios服務器上,nagios客戶端上運行的是nsca客戶端。在冗余監控模式下特別要用到。
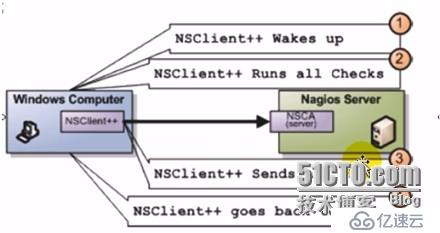
5、自定義的插件:
創建一個命令的過程就是一個實例化插件的過程
nagios強大到可以分析依賴關系,比如主機故障了,就不會繼續監控主機上的服務了,因為主機因為掛了,主機上的服務肯定都檢測不到了
狀態分為軟狀態和硬狀態
軟狀態 | 當監控發現轉變的時候,他會重復進行多次檢測,前幾次狀態的檢測是軟狀態,不會發送告警通知 |
硬狀態 | 如果多次檢測結果還是一樣的話,就變成了硬狀態 |
不同狀態之間轉換被稱為flapping,這種狀態也也要發送通知,可以自己定義
通過web接口來展現出來
需要安裝php,需要安裝mysql來存儲庫文件
Nagios組成:
主程序(Nagios):
一個插件程序(Nagios-plugins):
四個可選的ADDON(NRPE、NSCA、NSClient++和NDOUtil):
NDOUtils:用來將Nagios的配置信息和各時間產生的數據存入數據庫,以實現這些數據的快速檢索和處理
在這四個ADDON中,NRPE和NSClient++工作于客戶端,NDOUtils工作于服務器端,而NSCA則需要同時安裝在服務器端和客戶端
實驗環境:
nagios服務端:node4 192.168.0.4
nagios客戶端:node3 192.168.0.3 linux
nagios客戶端:192.168.0.5 windows sever 2003
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





