溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“python中jieba庫怎么使用”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“python中jieba庫怎么使用”吧!
jieba是優秀的中文分詞第三方庫。由于中文文本之間每個漢字都是連續書寫的,我們需要通過特定的手段來獲得其中的每個單詞,這種手段就叫分詞。而jieba是Python計算生態中非常優秀的中文分詞第三方庫,需要通過安裝來使用它。
jieba庫提供了三種分詞模式,但實際上要達到分詞效果只要掌握一個函數就足夠了,非常的簡單有效。
安裝第三方庫需要使用pip工具,在命令行下運行安裝命令(不是IDLE)。注意:需要將Python目錄和其目錄下的Scripts目錄加到環境變量中。
使用命令pip install jieba安裝第三方庫,安裝之后會提示successfully installed,告知是否安裝成功。
分詞原理:簡單來說,jieba庫是通過中文詞庫的方式來識別分詞的。它首先利用一個中文詞庫,通過詞庫計算漢字之間構成詞語的關聯概率,所以通過計算漢字之間的概率,就可以形成分詞的結果。當然,除了jieba自帶的中文詞庫,用戶也可以向其中增加自定義的詞組,從而使jieba的分詞更接近某些具體領域的使用。
jieba是python的一個中文分詞庫,下面介紹它的使用方法。
方式1: pip install jieba 方式2: 先下載 http://pypi.python.org/pypi/jieba/ 然后解壓,運行 python setup.py install
jieba常用的三種模式:
精確模式,試圖將句子最精確地切開,適合文本分析;
全模式,把句子中所有的可以成詞的詞語都掃描出來, 速度非常快,但是不能解決歧義;
搜索引擎模式,在精確模式的基礎上,對長詞再次切分,提高召回率,適合用于搜索引擎分詞。
可使用 jieba.cut 和 jieba.cut_for_search 方法進行分詞,兩者所返回的結構都是一個可迭代的 generator,可使用 for 循環來獲得分詞后得到的每一個詞語(unicode),或者直接使用 jieba.lcut 以及 jieba.lcut_for_search 返回 list。
jieba.Tokenizer(dictionary=DEFAULT_DICT) :使用該方法可以自定義分詞器,可以同時使用不同的詞典。jieba.dt 為默認分詞器,所有全局分詞相關函數都是該分詞器的映射。
jieba.cut 和 jieba.lcut 可接受的參數如下:
需要分詞的字符串(unicode 或 UTF-8 字符串、GBK 字符串)
cut_all:是否使用全模式,默認值為 False
HMM:用來控制是否使用 HMM 模型,默認值為 True
jieba.cut_for_search 和 jieba.lcut_for_search 接受 2 個參數:
需要分詞的字符串(unicode 或 UTF-8 字符串、GBK 字符串)
HMM:用來控制是否使用 HMM 模型,默認值為 True
需要注意的是,盡量不要使用 GBK 字符串,可能無法預料地錯誤解碼成 UTF-8。
三種分詞模式的比較:
# 全匹配
seg_list = jieba.cut("今天哪里都沒去,在家里睡了一天", cut_all=True)
print(list(seg_list)) # ['今天', '哪里', '都', '沒去', '', '', '在家', '家里', '睡', '了', '一天']
# 精確匹配 默認模式
seg_list = jieba.cut("今天哪里都沒去,在家里睡了一天", cut_all=False)
print(list(seg_list)) # ['今天', '哪里', '都', '沒', '去', ',', '在', '家里', '睡', '了', '一天']
# 精確匹配
seg_list = jieba.cut_for_search("今天哪里都沒去,在家里睡了一天")
print(list(seg_list)) # ['今天', '哪里', '都', '沒', '去', ',', '在', '家里', '睡', '了', '一天']開發者可以指定自己自定義的詞典,以便包含 jieba 詞庫里沒有的詞。
用法: jieba.load_userdict(dict_path)
dict_path:為自定義詞典文件的路徑
詞典格式如下:
一個詞占一行;每一行分三部分:詞語、詞頻(可省略)、詞性(可省略),用空格隔開,順序不可顛倒。
下面使用一個例子說明一下:
自定義字典 user_dict.txt:
大學課程
深度學習
下面比較下精確匹配、全匹配和使用自定義詞典的區別:
import jieba
test_sent = """
數學是一門基礎性的大學課程,深度學習是基于數學的,尤其是線性代數課程
"""
words = jieba.cut(test_sent)
print(list(words))
# ['\n', '數學', '是', '一門', '基礎性', '的', '大學', '課程', ',', '深度',
# '學習', '是', '基于', '數學', '的', ',', '尤其', '是', '線性代數', '課程', '\n']
words = jieba.cut(test_sent, cut_all=True)
print(list(words))
# ['\n', '數學', '是', '一門', '基礎', '基礎性', '的', '大學', '課程', '', '', '深度',
# '學習', '是', '基于', '數學', '的', '', '', '尤其', '是', '線性', '線性代數', '代數', '課程', '\n']
jieba.load_userdict("userdict.txt")
words = jieba.cut(test_sent)
print(list(words))
# ['\n', '數學', '是', '一門', '基礎性', '的', '大學課程', ',', '深度學習', '是',
# '基于', '數學', '的', ',', '尤其', '是', '線性代數', '課程', '\n']
jieba.add_word("尤其是")
jieba.add_word("線性代數課程")
words = jieba.cut(test_sent)
print(list(words))
# ['\n', '數學', '是', '一門', '基礎性', '的', '大學課程', ',', '深度學習', '是',
# '基于', '數學', '的', ',', '尤其是', '線性代數課程', '\n']從上面的例子中可以看出,使用自定義詞典與使用默認詞典的區別。
jieba.add_word():向自定義字典中添加詞語
可以基于 TF-IDF 算法進行關鍵詞提取,也可以基于TextRank 算法。 TF-IDF 算法與 elasticsearch 中使用的算法是一樣的。
使用 jieba.analyse.extract_tags() 函數進行關鍵詞提取,其參數如下:
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
sentence 為待提取的文本
topK 為返回幾個 TF/IDF 權重最大的關鍵詞,默認值為 20
withWeight 為是否一并返回關鍵詞權重值,默認值為 False
allowPOS 僅包括指定詞性的詞,默認值為空,即不篩選
jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 實例,idf_path 為 IDF 頻率文件
也可以使用 jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 實例,idf_path 為 IDF 頻率文件。
基于 TF-IDF 算法和TextRank算法的關鍵詞抽取:
import jieba.analyse
file = "sanguo.txt"
topK = 12
content = open(file, 'rb').read()
# 使用tf-idf算法提取關鍵詞
tags = jieba.analyse.extract_tags(content, topK=topK)
print(tags)
# ['玄德', '程遠志', '張角', '云長', '張飛', '黃巾', '封谞', '劉焉', '鄧茂', '鄒靖', '姓名', '招軍']
# 使用textrank算法提取關鍵詞
tags2 = jieba.analyse.textrank(content, topK=topK)
# withWeight=True:將權重值一起返回
tags = jieba.analyse.extract_tags(content, topK=topK, withWeight=True)
print(tags)
# [('玄德', 0.1038549799467099), ('程遠志', 0.07787459004363208), ('張角', 0.0722532891360849),
# ('云長', 0.07048801593691037), ('張飛', 0.060972692853113214), ('黃巾', 0.058227157790330185),
# ('封谞', 0.0563904127495283), ('劉焉', 0.05470798376886792), ('鄧茂', 0.04917692565566038),
# ('鄒靖', 0.04427258239705188), ('姓名', 0.04219704283997642), ('招軍', 0.04182041076757075)]上面的代碼是讀取文件,提取出現頻率最高的前12個詞。
詞性標注主要是標記文本分詞后每個詞的詞性,使用例子如下:
import jieba
import jieba.posseg as pseg
# 默認模式
seg_list = pseg.cut("今天哪里都沒去,在家里睡了一天")
for word, flag in seg_list:
print(word + " " + flag)
"""
使用 jieba 默認模式的輸出結果是:
我 r
Prefix dict has been built successfully.
今天 t
吃 v
早飯 n
了 ul
"""
# paddle 模式
words = pseg.cut("我今天吃早飯了",use_paddle=True)
"""
使用 paddle 模式的輸出結果是:
我 r
今天 TIME
吃 v
早飯 n
了 xc
"""paddle模式的詞性對照表如下:
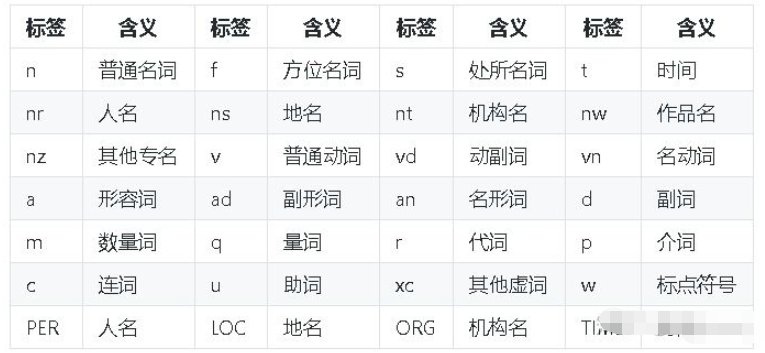
jieba分詞有三種模式:精確模式、全模式和搜索引擎模式。
簡單說,精確模式就是把一段文本精確的切分成若干個中文單詞,若干個中文單詞之間經過組合就精確的還原為之前的文本,其中不存在冗余單詞。精確模式是最常用的分詞模式。
進一步jieba又提供了全模式,全模式是把一段中文文本中所有可能的詞語都掃描出來,可能有一段文本它可以切分成不同的模式或者有不同的角度來切分變成不同的詞語,那么jieba在全模式下把這樣的不同的組合都挖掘出來,所以如果用全模式來進行分詞,分詞的信息組合起來并不是精確的原有文本,會有很多的冗余。
而搜索引擎模式更加智能,它是在精確模式的基礎上對長詞進行再次切分,將長的詞語變成更短的詞語,進而適合搜索引擎對短詞語的索引和搜索,在一些特定場合用的比較多。
jieba.lcut(s)
精確模式,能夠對一個字符串精確地返回分詞結果,而分詞的結果使用列表形式來組織。例如:
>>> import jieba
>>> jieba.lcut("中國是一個偉大的國家")
Building prefix dict from the default dictionary ...
Dumping model to file cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
Loading model cost 2.489 seconds.
Prefix dict has been built successfully.
['中國', '是', '一個', '偉大', '的', '國家']jieba.lcut(s,cut_all=True)
全模式,能夠返回一個列表類型的分詞結果,但結果存在冗余。例如:
>>> import jieba
>>> jieba.lcut("中國是一個偉大的國家",cut_all=True)
['中國', '國是', '一個', '偉大', '的', '國家']jieba.lcut_for_search(s)
搜索引擎模式,能夠返回一個列表類型的分詞結果,也存在冗余。例如:
>>> import jieba
>>> jieba.lcut_for_search("中華人民共和國是偉大的")
['中華', '華人', '人民', '共和', '共和國', '中華人民共和國', '是', '偉大', '的']jieba.add_word(w)
向分詞詞庫添加新詞w
最重要的就是jieba.lcut(s)函數,完成精確的中文分詞。
到此,相信大家對“python中jieba庫怎么使用”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





