溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了jieba庫如何在Python中使用,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
1、jieba庫基本介紹
(1)、jieba庫概述
jieba是優秀的中文分詞第三方庫
- 中文文本需要通過分詞獲得單個的詞語
- jieba是優秀的中文分詞第三方庫,需要額外安裝
- jieba庫提供三種分詞模式,最簡單只需掌握一個函數
(2)、jieba分詞的原理
Jieba分詞依靠中文詞庫
- 利用一個中文詞庫,確定漢字之間的關聯概率
- 漢字間概率大的組成詞組,形成分詞結果
- 除了分詞,用戶還可以添加自定義的詞組
jieba庫使用說明
(1)、jieba分詞的三種模式
精確模式、全模式、搜索引擎模式
- 精確模式:把文本精確的切分開,不存在冗余單詞
- 全模式:把文本中所有可能的詞語都掃描出來,有冗余
- 搜索引擎模式:在精確模式基礎上,對長詞再次切分
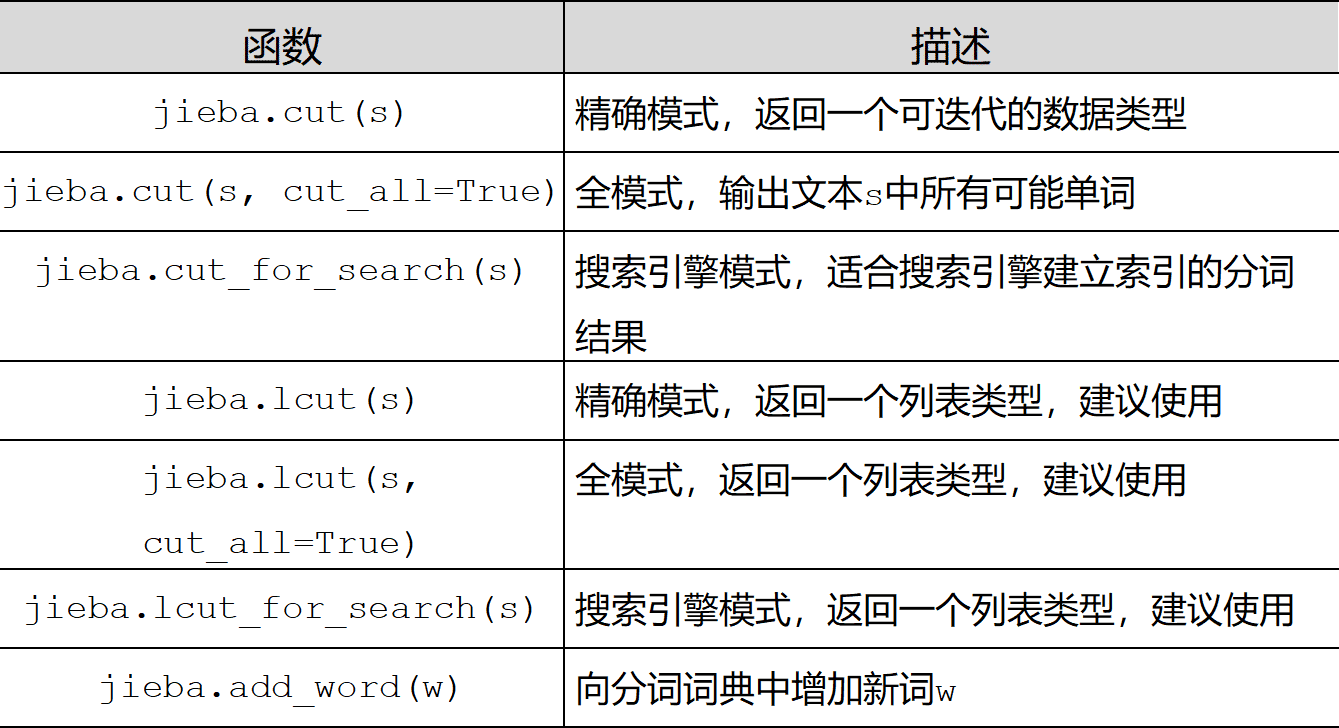
(2)、jieba庫常用函數
2.jieba應用實例

3.利用jieba庫統計三國演義中任務的出場次數
import jieba
txt = open("D:\\三國演義.txt", "r", encoding='utf-8').read()
words = jieba.lcut(txt) # 使用精確模式對文本進行分詞
counts = {} # 通過鍵值對的形式存儲詞語及其出現的次數
for word in words:
if len(word) == 1: # 單個詞語不計算在內
continue
else:
counts[word] = counts.get(word, 0) + 1 # 遍歷所有詞語,每出現一次其對應的值加 1
items = list(counts.items())#將鍵值對轉換成列表
items.sort(key=lambda x: x[1], reverse=True) # 根據詞語出現的次數進行從大到小排序
for i in range(15):
word, count = items[i]
print("{0:<5}{1:>5}".format(word, count))
上述內容就是jieba庫如何在Python中使用,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





