溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“Python怎么使用XPath采集數據”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“Python怎么使用XPath采集數據”文章吧。
lxml 是 Python 的一個庫,用于解析和呈現 XML 和 HTML。它支持多種內置和第三方 XML 和 HTML 標記,例如 <a>,<img>,<form>,<ul>,<li>,<ol>,<dl>,<dt>,<dd> 等。lxml 還支持使用正則表達式來解析和呈現 XML 和 HTML。
首先,我們要進行數據來源分析,知道我們的需求是什么?
明確采集網站是什么?
明確采集數據是什么?
我們都玩過4399小游戲,我們想獲取游戲名稱和游戲鏈接,并保存下來。首先,我們導入相關的庫文件。
import csv import requests from lxml import etree
接下來,我們可以發送請求,獲取網頁源代碼,代碼如下。
url = 'https://www.4399.com/flash_fl/2_1.htm'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
res = requests.get(url, headers=headers)
res.encoding = res.apparent_encoding這段代碼是一個 Python 的 requests 模塊的示例代碼,用于從 https://www.4399.com/flash_fl/2_1.htm 這個網站上獲取數據并將其轉換為 HTML 格式。
首先,我們定義了一個 url 變量,它包含了要從網站上獲取數據的 URL。然后,我們使用 headers 字典來設置請求頭,包括 user-agent 頭部,用于指定瀏覽器的 User-Agent 信息。
接下來,我們使用 requests.get() 函數來發送一個 HTTP GET 請求,并將 headers 字典作為請求頭傳遞給它。這個函數會返回一個 Response 對象,我們可以使用 res.encoding 屬性來獲取請求的編碼方式,并將其設置為 res.apparent_encoding,以便在輸出 HTML 時使用相同的編碼方式。
最后,我們將請求的編碼方式設置為瀏覽器的默認編碼方式,以便在輸出 HTML 時使用相同的編碼方式。
接下來,我們用xpath解析數據。我們用開發者工具定位到標簽位置。
html_data = etree.HTML(res.text)
lis = html_data.xpath('//*[@class="bre m15"]//ul/li')
for li in lis:
href = li.xpath('./a/@href')[0]
title = li.xpath('./a/img/@alt')[0]接下來,我們使用 html_data.xpath 方法來解析 HTML 文檔中的 ul 和 li 元素,并將它們存儲在 lis 變量中。
最后,我們使用 for 循環遍歷 lis,并使用 li.xpath 方法來獲取每個 li 元素的 a 元素的 href 和 alt 屬性,并將它們存儲在 href 和 title 變量中。 我們運行結果之后,我們還要對鏈接進行拼接。
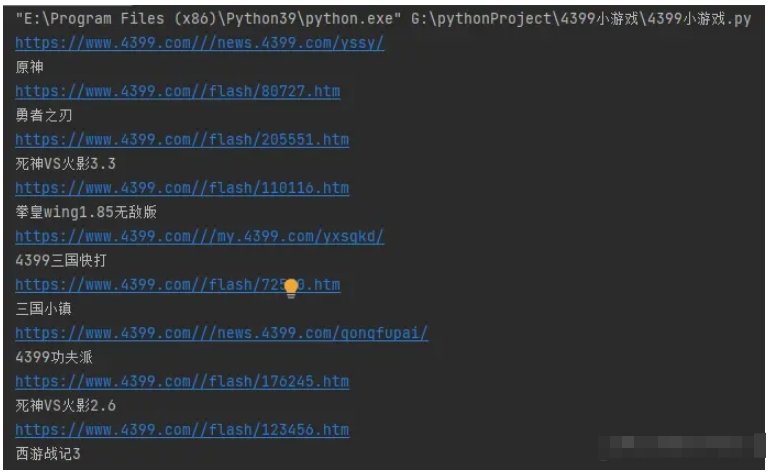
接下來就是保存數據,先寫入頭文件。
f = open('4399小游戲.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['游戲名稱', '游戲網站'])
csv_writer.writeheader()這段代碼中,我們首先使用 Python 的 open() 函數打開了一個名為 "4399小游戲.csv" 的文件,文件模式為 a,表示追加模式。
然后,我們使用 Python 的 csv 模塊創建了一個名為 csv_writer 的 DictWriter 對象,并使用 writeheader() 方法來寫入表頭。
最后,我們使用 write() 方法向文件中寫入數據,數據內容為一個字典對象。
這段代碼的作用是將一個字典對象寫入到文件中,其中包含了游戲名稱和游戲網站兩個字段的數據。
需要注意的是,在寫入數據之前,我們需要使用 csv.DictWriter() 函數來創建一個 DictWriter 對象,并使用 fieldnames 參數來指定字段名稱。此外,我們還需要使用 newline='' 參數來避免在 Windows 系統中出現換行符問題。 '''
dit = {
'游戲名稱': title,
'游戲網站': data_url,
}
csv_writer.writerow(dit)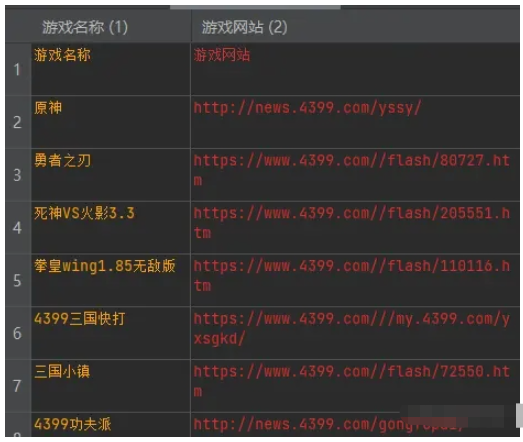
以上就是關于“Python怎么使用XPath采集數據”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





