溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下數據庫之Hive概論和架構和基本操作是什么的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。
Hive是一個構建在Hadoop上的數據倉庫框架,最初,Hive是由Facebook開發,后臺移交由Apache軟件基金會開發,并做為一個Apache開源項目。
Hive是基于Hadoop的一個數據倉庫工具,可以將結構化的數據文件映射為一張數據庫表,并提供類SQL查詢功能。
Hive它能夠存儲很大的數據集,可以直接訪問存儲在Apache HDFS或其他數據存儲系統(如Apache HBase)中的文件。
Hive支持MapReduce、Spark、Tez這三種分布式計算引擎。
Hive是建立在Hadoop上的數據倉庫基礎架構,它提供了一系列的工具,可以存儲、查詢、分析存儲在分布式存儲系統中的大規模數據集。Hive定義了簡單的類SQL查詢語言,通過底層的計算引擎,將SQL轉為具體的計算任務進行執行。
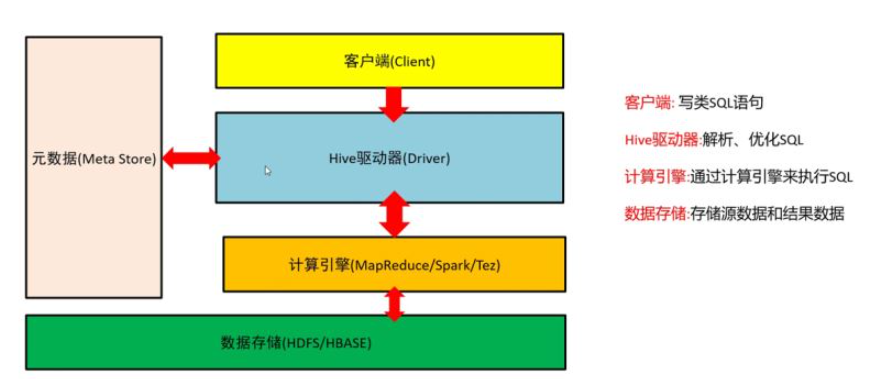
客戶端:寫類SQL語句
Hive驅動器:解析、優化SQL
計算引擎:通過計算引擎來執行SQL
數據存儲:存儲源數據和結果數據
MapReduce
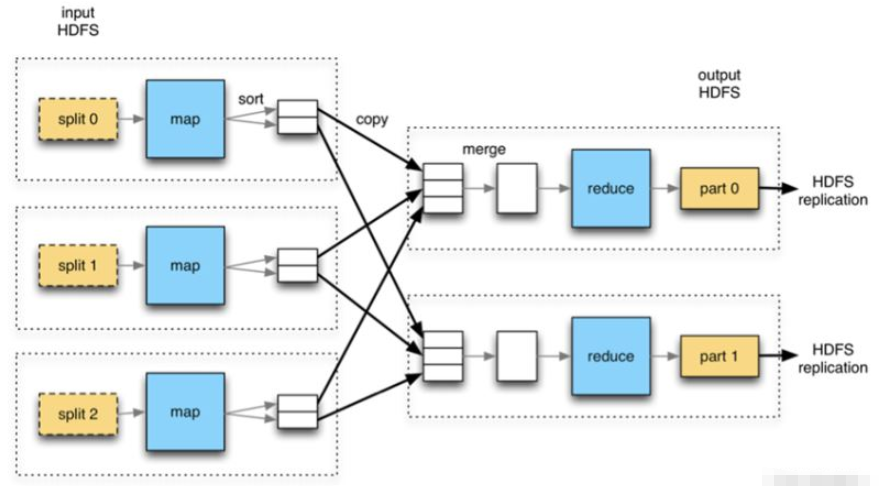
它將計算分為兩個階段,分別為Map和Reduce。對于應用來說,需要想辦法將應用拆分為多個map、reduce,以完成一個完整的算法。
MapReduce整個計算過程會不斷重復的往磁盤里讀寫中間結果。導致計算速度比較慢,效率比較低。
Tez
把Map/Reduce過程拆分成若干個子過程,同時可以把多個Map/Reduce任務組合成一個較大DAG任務,減少了Map/Reduce之間的文件存儲。
Spark
Apache Spark是一個快速的,多用途的集群計算系統,相對于Hadoop MapReduce將中間結果保存在磁盤中,Spark使用了內存保存中間結果,能在數據尚未寫入硬盤時在內存中進行計算,同時Spark提供SQL支持。 Spark 實現了一種叫RDDs的DAG執行引擎,其數據緩存在內存中可以進行迭代處理。
使用的是Hive+Spark計算引擎
1、啟動集群中所有的組件
cd /export/onekey
./start-all.sh
2、使用終端鏈接Hive
1)、進入到/export/server/spark-2.3.0-bin-hadoop2.7/bin目錄中
2)、執行以下命令:./beeline
3)、輸入:!connect jdbc:hive2://node1:10000,回車
4)、輸入用戶名:root
5)、直接回車,即可使用命令行連接到Hive,然后就可以執行HQL了。
[root@node1 onekey]# cd /export/server/spark-2.3.0-bin-hadoop2.7/bin [root@node1 bin]# ./beeline Beeline version 1.2.1.spark2 by Apache Hive beeline> !connect jdbc:hive2://node1:10000 Connecting to jdbc:hive2://node1.itcast.cn:10000 Enter username for jdbc:hive2://node1.itcast.cn:10000: root Enter password for jdbc:hive2://node1.itcast.cn:10000: 直接回車 2021-01-08 14:34:24 INFO Utils:310 - Supplied authorities: node1.itcast.cn:10000 2021-01-08 14:34:24 INFO Utils:397 - Resolved authority: node1.itcast.cn:10000 2021-01-08 14:34:24 INFO HiveConnection:203 - Will try to open client transport with JDBC Uri: jdbc:hive2://node1.itcast.cn:10000 Connected to: Spark SQL (version 2.3.0) Driver: Hive JDBC (version 1.2.1.spark2) Transaction isolation: TRANSACTION_REPEATABLE_READ 0: jdbc:hive2://node1.itcast.cn:10000> 。
連接成功的標志。
Hive的數據庫和表
Hive數倉和傳統關系型數據庫類似,管理數倉數據也有數據庫和表
1)、創建數據庫-默認方式
create database if not exists myhive;
show databases; #查看所有數據庫
說明:
1、if not exists:該參數可選,表示如果數據存在則不創建(不加該參數則報錯),不存在則創建
2、hive的數據庫默認存放在/user/hive/warehouse目錄
2)、創建數據庫-指定存儲路徑
create database myhive2 location '/myhive2';
show databases; #查看所有數據庫
說明:
1、location:用來指定數據庫的存放路徑。
3)、查看數據庫詳情信息
desc database myhive;
4)、刪除數據庫
刪除一個空數據庫,如果數據庫下面有數據表,就會報錯
drop database myhive;
強制刪除數據庫,包含數據庫下面的表一起刪除
drop database myhive2 cascade;
5)、創建數據庫表語法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [LOCATION hdfs_path]
6)、表字段數據類型
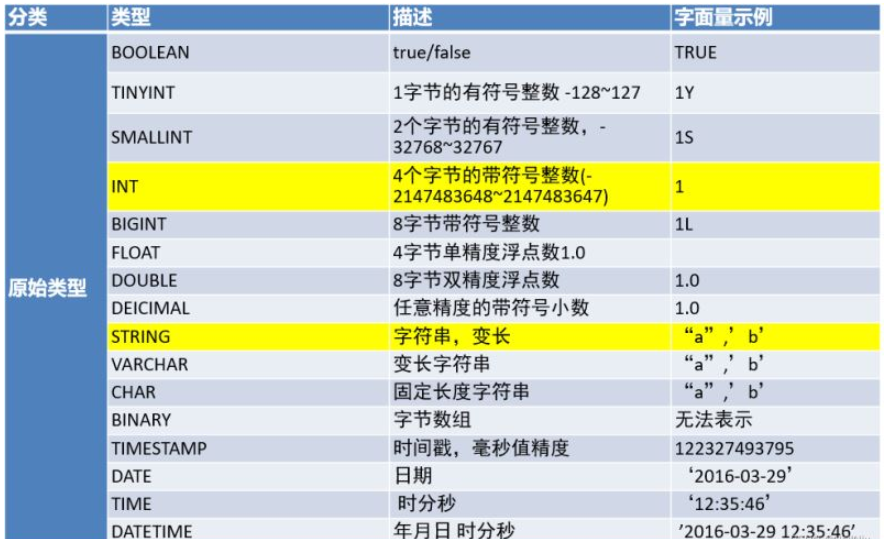
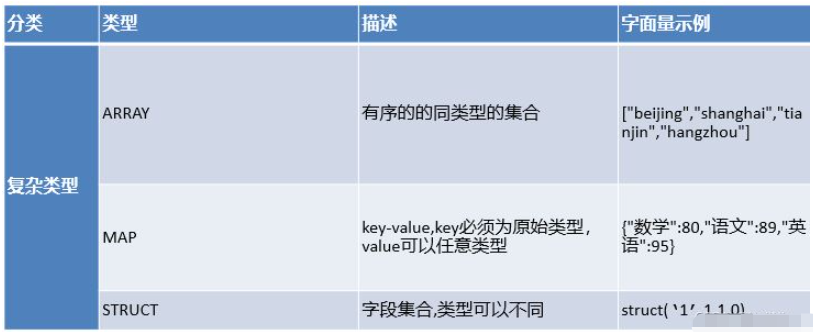
7)、表字段數據類型-復雜類型
8)、 內部表操作-創建表
未被external修飾的內部表(managed table),內部表又稱管理表,內部表不適合用于共享數據。
create database mytest; #創建數據庫
user mytest; #選擇數據庫
create table stu(id int, name string);
show tables; #查詢數據
創建表之后,Hive會在對應的數據庫文件夾下創建對應的表目錄。
9)、內部表操作-查看表結構/刪除表
查看表結構
desc stu;#查看表結構基本信息
desc formatted stu;查看表結構詳細信息
刪除表
drop table stu;
1)、方式1-直接插入數據
對于Hive中的表,可以通過insert into 指令向表中插入數據
user mytest; #選擇數據庫 create table stu(id int, name string); # 創建表 # 向表中插入數據 insert into stu values(1, 'test1'); insert into stu values(2, 'test2'); select * from stu; #查詢數據
2)、方式2-load數據加載
Load 命令用于將外部數據加載到Hive表中
語法:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1,partcol2=val2 ...)] 說明: LOCAL 表示從本地文件系統加載,否則是從HDFS加載
應用1-本地加載
#創建表,同時指定文件的分隔符 create table if not exists stu2(id int ,name string) row format delimited fields terminated by '\t' ; #向表加載數據 load data local inpath '/export/data/hivedatas/stu.txt' into table stu2;
應用2-HDFS加載
#創建表,同時指定文件的分隔符 create table if not exists stu3(id int ,name string) row format delimited fields terminated by '\t' ; #向表加載數據 hadoop fs -mkdir -p /hivedatas cd /export/data/hivedatas hadoop fs –put stu.txt /hivedatas/ load data inpath '/hivedatas/stu.txt' into table stu3;
1)、元數據
Hive是建立在Hadoop之上的數據倉庫,存在hive里的數據實際上就是存在HDFS上,都是以文件的形式存在
Hive元數據用來記錄數據庫和表的特征信息,比如數據庫的名字、存儲路徑、表的名字、字段信息、表文件存儲路徑等等
Hive的元數據保存在Mysql數據庫中
2)、內部表特點
hive內部表信息存儲默認的文件路徑是在/user/hive/warehouse/databasename.db/tablename目錄
hive 內部表在進行drop操作時,其表中的數據以及表的元數據信息均會被刪除
內部表一般可以用來做中間表或者臨時表
1)、創建表
創建表時,使用external關鍵字修飾則為外部表,外部表數據可用于共享
#創建學生表 create external table student (sid string,sname string,sbirth string , ss ex string) row format delimited fields terminated by ‘\t' location ‘/hive_table/student‘; #創建老師表 create external table teacher (tid string,tname string) row format delimited fields terminated by '\t' location ‘/hive_table/teacher‘;
創建表之后,Hive會在Location指定目錄下創建對應的表目錄。
2)、加載數據
外部表加載數據也是通過load命令來完成
#給學生表添加數據 load data local inpath '/export/data/hivedatas/student.txt' into table student; #給老師表添加數據,并覆蓋已有數據 load data local inpath '/export/data/hivedatas/teacher.txt' overwrite into table teacher; #查詢數據 select * from student; select * from teacher;
3)、外部表特點
外部表在進行drop操作的時候,僅會刪除元數據,而不刪除HDFS上的文件
外部表一般用于數據共享表,比較安全
4)、安裝Visual Studio Code
開發Hive的時候,經常要編寫類SQL,
1)、介紹
在大數據中,最常用的一種思想是分治,分區表實際就是對應hdfs文件系統上的獨立的文件的文件夾,該文件夾下是該分區所有數據文件。
分區可以理解為分類,通過分類把不同類型的數據放到不同的目錄下。
Hive中可以創建一級分區表,也可以創建多級分區表
2)、創建一級分區表
create table score(sid string,cid string, sscore int) partitioned by (month string) row format delimited fields terminated by '\t';
3)、數據加載
load data local inpath '/export/data/hivedatas/score.txt' into table score partition (month='202006');
4)、創建多級分區表
create table score2(sid string,cid string, sscore int) partitioned by (year string,month string, day string) row format delimited fields terminated by '\t';
5)、數據加載
load data local inpath '/export/data/hivedatas/score.txt' into table score2 partition(year='2020',month='06',day='01');
加載數據之后,多級分區表會創建多級分區目錄。
6)、查看分區
show partitions score;
7)、添加分區
alter table score add partition(month='202008'); alter table score add partition(month='202009') partition(month = '202010');
8)、刪除分區
alter table score drop partition(month = '202010');
9)、Array類型
Array是數組類型,Aarray中存放相同類型的數據
源數據:
zhangsan beijing,shanghai,tianjin,hangzhouwangwu changchun,chengdu,wuhan,beijin
建表數據:
create external table hive_array(name string, work_locations array<string>) row format delimited fields terminated by '\t' collection items terminated by ',';
建表語句:
load data local inpath '/export/data/hivedatas/array_data.txt' overwrite into table hive_array;
查詢語句:
-- 查詢所有數據 select * from hive_array; -- 查詢loction數組中第一個元素 select name, work_locations[0] location from hive_array; -- 查詢location數組中元素的個數 select name, size(work_locations) location from hive_array; -- 查詢location數組中包含tianjin的信息 select * from hive_array where array_contains(work_locations,'tianjin');
以上就是“數據庫之Hive概論和架構和基本操作是什么”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





