溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了怎么使用Spring三級緩存解決循環依賴問題的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇怎么使用Spring三級緩存解決循環依賴問題文章都會有所收獲,下面我們一起來看看吧。
什么是循環依賴?很簡單,看下方的代碼就知曉了
@Service
public class A {
@Autowired
private B b;
}
@Service
public class B {
@Autowired
private A a;
}上面這兩種方式都是循環依賴,應該很好理解,當然也可以是三個 Bean 甚至更多的 Bean 相互依賴,原理都是一樣的,今天我們主要分析兩個 Bean 的依賴。
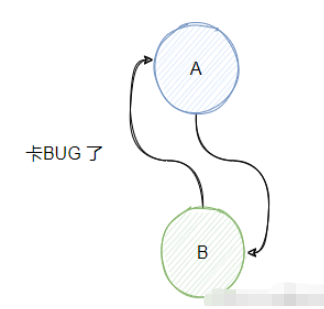
這種循環依賴可能會產生問題,例如 A 要依賴 B,發現 B 還沒創建。
于是開始創建 B ,創建的過程發現 B 要依賴 A, 而 A 還沒創建好呀,因為它要等 B 創建好。
就這樣它們倆就擱這卡 bug 了。
上面這種循環依賴在實際場景中是會出現的,所以 Spring 需要解決這個問題,那如何解決呢?
關鍵就是提前暴露未完全創建完畢的 Bean。
在 Spring 中,只有同時滿足以下兩點才能解決循環依賴的問題:
依賴的 Bean 必須都是單例依賴注入的方式,必須不全是構造器注入,且 beanName 字母序在前的不能是構造器注入
Spring 只支持單例的循環依賴,因為如果兩個 Bean 都是原型模式的話:
創建 A1 需要創建一個 B1。
創建 B1 的時候要創建一個 A2。
創建 A2 又要創建一個 B2。
創建 B2 又要創建一個 A3。
創建 A3 又要創建一個 B3…
就又卡 BUG 了,是吧,因為原型模式都需要創建新的對象,不能跟用以前的對象。
如果是單例的話,創建 A 需要創建 B,而創建的 B 需要的是之前的個 A, 不然就不叫單例了,對吧?
也是基于這點, Spring 就能操作操作了。
具體做法就是:先創建 A,此時的 A 是不完整的(沒有注入 B),用個 map 保存這個不完整的 A,再創建 B ,B 需要 A。
所以從那個 map 得到“不完整”的 A,此時的 B 就完整了,然后 A 就可以注入 B,然后 A 就完整了,B 也完整了,且它們是相互依賴的。
那為啥必須不全是構造器注入,因為在 Spring 中創建 Bean 分三步:
實例化,createBeanInstance,就是 new 了個對象
屬性注入,populateBean, 就是 set 一些屬性值
初始化,initializeBean,執行一些 aware 接口中的方法,initMethod,AOP代理等
明確了上面這三點,再結合我上面說的“不完整的”,我們來理一下。
如果全是構造器注入,比如A(B b),那表明在 new 的時候,就需要得到 B,此時需要 new B 。
但是 B 也是要在構造的時候注入 A ,即B(A a),這時候 B 需要在一個 map 中找到不完整的 A ,發現找不到。
為什么找不到?因為 A 還沒 new 完呢,所以找到不完整的 A,因此如果全是構造器注入的話,那么 Spring 無法處理循環依賴。
經過上面的鋪墊,我想你對 Spring 如何解決循環依賴應該已經有點感覺了,接下來我們就來看看它到底是如何實現的。
明確了 Spring 創建 Bean 的三步驟之后,我們再來看看它為單例搞的三個 map:
一級緩存,singletonObjects,存儲所有已創建完畢的單例 Bean (完整的 Bean)
二級緩存,earlySingletonObjects,存儲所有僅完成實例化,但還未進行屬性注入和初始化的 Bean
三級緩存,singletonFactories,存儲能建立這個 Bean 的一個工廠,通過工廠能獲取這個 Bean,延遲化 Bean 的生成,工廠生成的 Bean 會塞入二級緩存
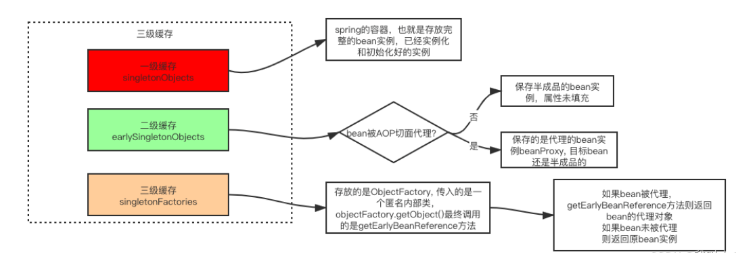
這三個 map 是如何配合的呢?
首先,獲取單例 Bean 的時候會通過 BeanName 先去 singletonObjects(一級緩存) 查找完整的 Bean,如果找到則直接返回,否則進行步驟 2。
看對應的 Bean 是否在創建中,如果不在直接返回找不到,如果是,則會去 earlySingletonObjects (二級緩存)查找 Bean,如果找到則返回,否則進行步驟 3
去 singletonFactories (三級緩存)通過 BeanName 查找到對應的工廠,如果存著工廠則通過工廠創建 Bean ,并且放置到 earlySingletonObjects 中。
如果三個緩存都沒找到,則返回 null。
從上面的步驟我們可以得知,如果查詢發現 Bean 還未創建,到第二步就直接返回 null,不會繼續查二級和三級緩存。
返回 null 之后,說明這個 Bean 還未創建,這個時候會標記這個 Bean 正在創建中,然后再調用 createBean 來創建 Bean,而實際創建是調用方法 doCreateBean。
doCreateBean 這個方法就會執行上面我們說的三步驟:
實例化
屬性注入
初始化
以上面的例子來講解,在實例化A 之后,會往三級緩存 singletonFactories 塞入一個工廠A,而調用這個工廠A的 getObject 方法,就能得到這個 A。
要注意,此時 Spring 是不知道會不會有循環依賴發生的,但是它不管,反正往 singletonFactories 塞這個工廠,這里就是提前暴露。
然后就開始執行屬性注入,這個時候 A 發現需要注入 B,所以去 getBean(B),此時又會走一遍上面描述的邏輯,到了 B 的屬性注入這一步。
此時 B 調用 getBean(A),這時候一級緩存里面找不到,但是發現 A 正在創建中的,于是去二級緩存找,發現沒找到,于是去三級緩存找,然后找到了。
并且通過上面提前在三級緩存里暴露的工廠得到 A,然后將這個工廠從三級緩存里刪除,并將 A 加入到二級緩存中。
然后結果就是 B 屬性注入成功。
緊接著 B 調用 initializeBean 初始化,最終返回,此時 B 已經被加到了一級緩存里 。
這時候就回到了 A 的屬性注入,此時注入了 B,接著執行初始化,最后 A 也會被加到一級緩存里,且從二級緩存中刪除 A。
Spring 解決依賴循環就是按照上面所述的邏輯來實現的。
重點就是在對象實例化之后,都會在三級緩存里加入一個工廠,提前對外暴露還未完整的 Bean,這樣如果被循環依賴了,對方就可以利用這個工廠得到一個不完整的 Bean,破壞了循環的條件。
上面都說了那么多了,那我們思考下,解決循環依賴需要三級緩存嗎?
很明顯,如果僅僅只是為了破解循環依賴,二個緩存夠了,壓根就不必要三級。
你思考一下,在實例化 Bean A 之后,我在二級 map 里面塞入這個 A,然后繼續屬性注入。
發現 A 依賴 B 所以要創建 Bean B,這時候 B 就能從二級 map 得到 A ,完成 B 的建立之后, A 自然而然能完成。
所以為什么要搞個三級緩存,且里面存的是創建 Bean 的工廠呢?
我們來看下調用工廠的 getObject 到底會做什么,實際會調用下面這個方法:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (SmartInstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().smartInstantiationAware) {
exposedObject = bp.getEarlyBeanReference(exposedObject, beanName);
}
}
return exposedObject;
}重點就在中間的判斷,如果 false,返回就是參數傳進來的 bean,沒任何變化。
如果是 true 說明有 InstantiationAwareBeanPostProcessors 。
且循環的是 smartInstantiationAware 類型,如有這個 BeanPostProcessor 說明 Bean 需要被 aop 代理。
我們都知道如果有代理的話,那么我們想要直接拿到的是代理對象。
也就是說如果 A 需要被代理,那么 B 依賴的 A 是已經被代理的 A,所以我們不能返回 A 給 B,而是返回代理的 A 給 B。
這個工廠的作用就是判斷這個對象是否需要代理,如果否則直接返回,如果是則返回代理對象。
看到這明白的小伙伴肯定會問,那跟三級緩存有什么關系,我可以在要放到二級緩存的時候判斷這個 Bean 是否需要代理,如果要直接放代理的對象不就完事兒了。
是的,這個思路看起來沒任何問題,問題就出在時機,這跟 Bean 的生命周期有關系。
Spring 原本的設計是,bean 的創建過程分三個階段:
1 創建實例 createBeanInstance – 創建出 bean 的原始對象
2 填充依賴 populateBean – 利用反射,使用 BeanWrapper 來設置屬性值
3 initializeBean – 執行 bean 創建后的處理,包括 AOP 對象的產生
在沒有循環依賴的場景下:第 1,2 步都是 bean 的原始對象,第 3 步 initializeBean 時,才會生成 AOP 代理對象。
所以,循環依賴打破了 AOP 代理 bean 生成的時機,需要在 populateBean 之前就生成 AOP 代理 bean。
而且,生成 AOP 代理需要執行 BeanPostProcessor,而 Spring 原本的設計是在第 3 步 initializeBean 時才去調用 BeanPostProcessor 的。
所以 Spring 先在一個三級緩存放置一個工廠,用于代表Bean的引用。只有在上面的第三步時,才會通過這個工廠去創建代理對象,這樣生命周期就不會亂套了。
理論上來說,使用二級緩存是可以解決 AOP 代理 bean 的循環依賴的。只是 Spring 沒有選擇這樣去實現。Spring 選擇了三級緩存來實現,讓 bean 的創建流程更加符合常理,更加清晰明了。
關于“怎么使用Spring三級緩存解決循環依賴問題”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“怎么使用Spring三級緩存解決循環依賴問題”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





