溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下Golang中的unsafe包有什么用的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。
unsafe 包提供了一些操作可以繞過 go 的類型安全檢查, 從而直接操作內存地址, 做一些 tricky 操作。示例代碼運行環境是
go version go1.18 darwin/amd64
unsafe 包提供了 Sizeof 方法獲取變量占用內存大小「不包含指針指向變量的內存大小」, Alignof 獲取內存對齊系數, 具體內存對齊規則可以自行 google.
type demo1 struct {
a bool // 1
b int32 // 4
c int64 // 8
}
type demo2 struct {
a bool // 1
c int64 // 8
b int32 // 4
}
type demo3 struct { // 64 位操作系統, 字長 8
a *demo1 // 8
b *demo2 // 8
}
func MemAlign() {
fmt.Println(unsafe.Sizeof(demo1{}), unsafe.Alignof(demo1{}), unsafe.Alignof(demo1{}.a), unsafe.Alignof(demo1{}.b), unsafe.Alignof(demo1{}.c)) // 16,8,1,4,8
fmt.Println(unsafe.Sizeof(demo2{}), unsafe.Alignof(demo2{}), unsafe.Alignof(demo2{}.a), unsafe.Alignof(demo2{}.b), unsafe.Alignof(demo2{}.c)) // 24,8,1,4,8
fmt.Println(unsafe.Sizeof(demo3{})) // 16
} // 16}復制代碼
從上面 case 可以看到 demo1 和 demo2 包含相同的屬性, 只是定義的屬性順序不同, 卻導致變量的內存大小不同。這里是因為發生了內存對齊。
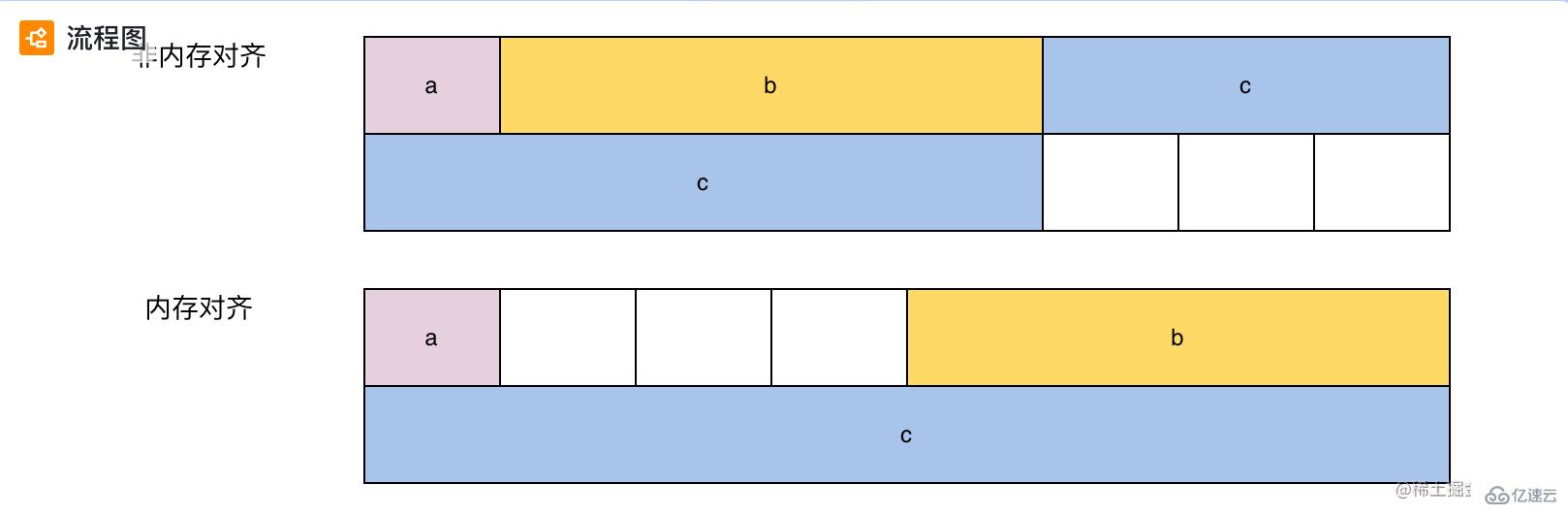
計算機在處理任務時, 會按照特定的字長「例如:32 位操作系統, 字長為 4; 64 位操作系統, 字長為 8」為單位處理數據。那么, 在讀取數據的時候也是按照字長為單位。例如: 對于 64 位操作系統, 程序一次讀取的字節數為 8 的倍數。下面是 demo1 在非內存對齊和內存對齊下的布局:
非內存對齊:
變量 c 會被放在不同的字長里面, cpu 在讀取的時候需要同時讀取兩次, 同時對兩次的結果做處理, 才能拿到 c 的值。這種方式雖然節省了內存空間, 但是會增加處理時間。
內存對齊:
內存對齊采用了一種方案, 可以避免同一個非內存對齊的這種情況, 但是會額外占用一些空間「空間換時間」。具體內存對齊規則可以自行 google。
在 go 中可以聲明一個指針類型, 這里的類型是 safe pointer, 即要明確指針指向的類型, 如果類型不匹配將會在編譯時報錯。如下面的示例, 編譯器會認為 MyString 和 string 是不同的類型, 無法進行賦值。
func main() {
type MyString string
s := "test"
var ms MyString = s // Cannot use 's' (type string) as the type MyString
fmt.Println(ms)
}
那有沒有一種類型, 可以指向任意類型的變量呢?可以使用 unsfe.Pointer, 它可以指向任意類型的變量。通過Pointer 的聲明, 可以知道它是一個指針類型, 指向變量所在的地址。具體的地址對應的值可以通過 uinptr 進行轉換。Pointer 有以下四種特殊的操作:
任意類型的指針都可以轉換成 Pointer 類型
Pointer 類型的變量可以轉換成任意類型的指針
uintptr 類型的變量可以轉換成 Pointer 類型
Pointer 類型的變量可以轉換成 uintprt 類型
type Pointer *ArbitraryType
// uintptr is an integer type that is large enough to hold the bit pattern of
// any pointer.
type uintptr uintptr
func main() {
d := demo1{true, 1, 2}
p := unsafe.Pointer(&d) // 任意類型的指針可以轉換為 Pointer 類型
pa := (*demo1)(p) // Pointer 類型變量可以轉換成 demo1 類型的指針
up := uintptr(p) // Pointer 類型的變量可以轉換成 uintprt 類型
pu := unsafe.Pointer(up) // uintptr 類型的變量可以轉換成 Pointer 類型; 當 GC 時, d 的地址可能會發生變更, 因此, 這里的 up 可能會失效
fmt.Println(d.a, pa.a, (*demo1)(pu).a) // true true true
}
在官方文檔中給出了 Pointer 的六種使用姿勢。
Pointer 直接指向一塊內存, 因此可以將這塊內存地址轉為任意類型。這里需要注意, T1 和 T2 需要有相同的內存布局, 會有異常數據。
func main() {
type myStr string
ms := []myStr{"1", "2"}
//ss := ([]string)(ms) Cannot convert an expression of the type '[]myStr' to the type '[]string'
ss := *(*[]string)(unsafe.Pointer(&ms)) // 將 pointer 指向的內存地址直接轉換成 *[]string
fmt.Println(ms, ss)
}
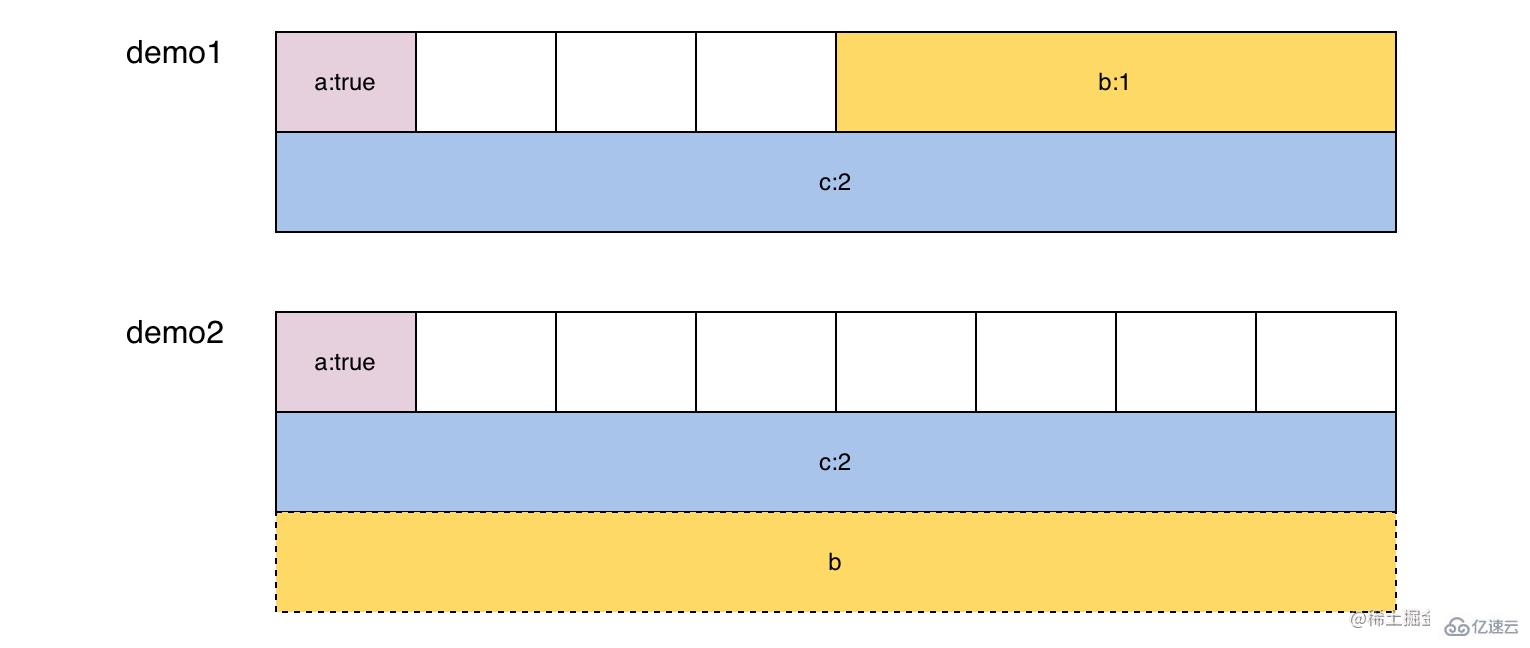
如果 T1 和 T2 的內存布局不同, 會發生什么呢?在下面的示例子中, demo1 和 demo2 雖然包含相同的結構體, 由于內存對齊, 導致兩者是不同的內存布局。將 Pointer 轉換時, 會從 demo1 的地址開始讀取 24「sizeof」 個字節, 按照demo2 內存對齊規則進行轉換, 將第一個字節轉換為 a:true, 8-16 個字節轉換為 c:2, 16-24 個字節超出了 demo1 的范圍, 但仍可以直接讀取, 獲取了非預期的值 b:17368000。
type demo1 struct {
a bool // 1
b int32 // 4
c int64 // 8
}
type demo2 struct {
a bool // 1
c int64 // 8
b int32 // 4
}
func main() {
d := demo1{true, 1, 2}
pa := (*demo2)(unsafe.Pointer(&d)) // Pointer 類型變量可以轉換成 demo2 類型的指針
fmt.Println(pa.a, pa.b, pa.c) // true, 17368000, 2,
}
Pointer 是一個指針類型, 可以指向任意變量, 可以通過將 Pointer 轉換為 uintptr 來打印 Pointer 指向變量的地址。此外:不應該將 uintptr 轉換為 Pointer。如下面的例子: 當發生 GC 時, d 的地址可能會發生變更, 那么 up 由于未同步更新而指向錯誤的內存。
func main() {
d := demo1{true, 1, 2}
p := unsafe.Pointer(&d)
up := uintptr(p)
fmt.Printf("uintptr: %x, ptr: %p \n", up, &d) // uintptr: c00010c010, ptr: 0xc00010c010
fmt.Println(*(*demo1)(unsafe.Pointer(up))) // 不允許
}
當 Piointer 指向一個結構體時, 可以通過此方式獲取到結構體內部特定屬性的 Pointer。
func main() {
d := demo1{true, 1, 2}
// 等同于 unsafe.Pointer(&d.b); unsafe.Add(unsafe.Pointer(&d), unsafe.Offsetof(d.b))
pb := unsafe.Pointer(uintptr(unsafe.Pointer(&d)) + unsafe.Offsetof(d.b))
fmt.Println(pb)
}
前面說過, 由于 GC 會導致變量的地址發生變更, 因此不可以直接處理 uintptr。但是, 在調用 syscall.Syscall 時候可以允許傳遞一個 uintptr, 這里可以簡單理解為是編譯器做了特殊處理, 來保證 uintptr 是安全的。
調用方式:
syscall.Syscall(SYS_READ, uintptr( fd ), uintptr(unsafe.Pointer(p)), uintptr(n))
下面這種方式是不允許的:
u := uintptr(unsafe.Pointer(p)) // 不應該保存到一個變量上 syscall.Syscall(SYS_READ, uintptr( fd ), u, uintptr(n))
在 reflect 包中的 Value.Pointer 和 Value.UnsafeAddr 直接返回了地址對應的值「uintptr」, 可以直接將其結果轉為 Pointer
func main() {
d := demo1{true, 1, 2}
// 等同于 unsafe.Pointer(&d.b); unsafe.Add(unsafe.Pointer(&d), unsafe.Offsetof(d.b))
pb := unsafe.Pointer(uintptr(unsafe.Pointer(&d)) + unsafe.Offsetof(d.b))
// up := reflect.ValueOf(&d.b).Pointer(), pc := unsafe.Pointer(up); 不安全, 不應存儲到變量中
pc := unsafe.Pointer(reflect.ValueOf(&d.b).Pointer())
fmt.Println(pb, pc)
}
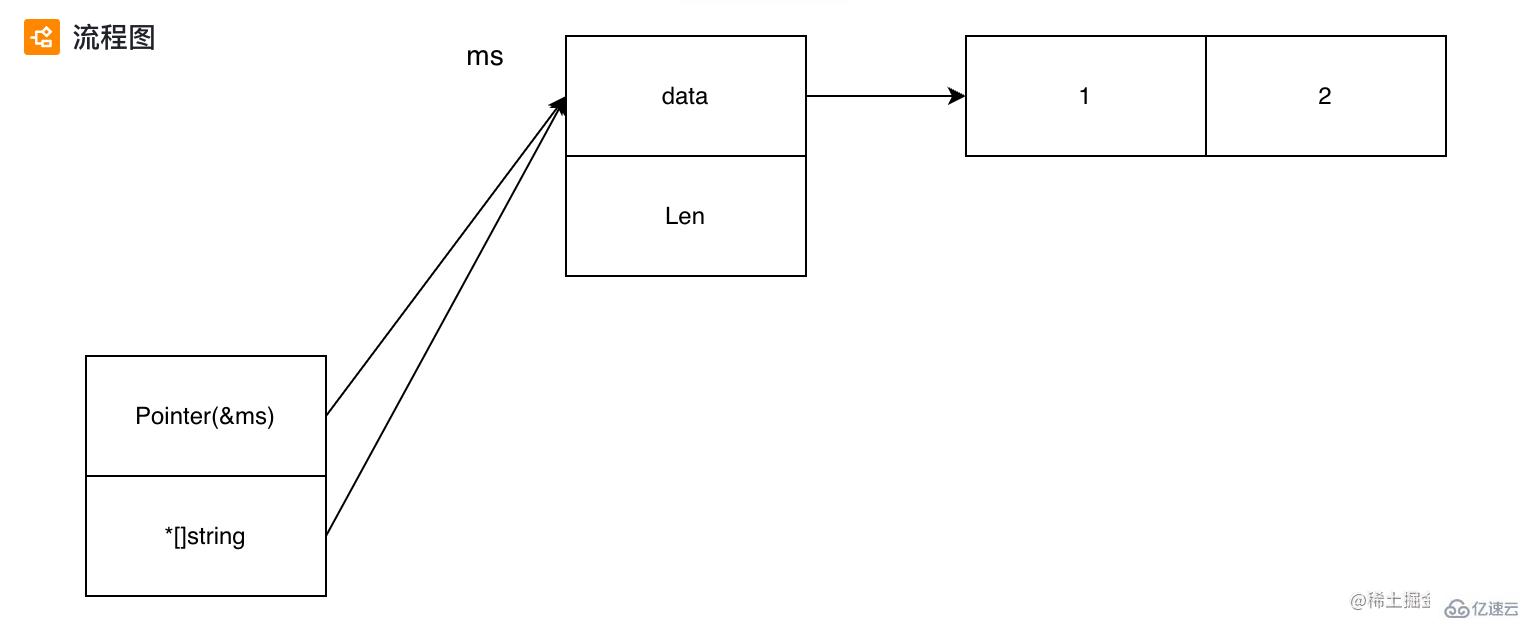
SliceHeader 和 StringHeader 其實是 slice 和 string 的內部實現, 里面都包含了一個字段 Data「uintptr」, 存儲的是指向 []T 的地址, 這里之所以使用 uinptr 是為了不依賴 unsafe 包。
func main() {
s := "a"
hdr := (*reflect.StringHeader)(unsafe.Pointer(&s)) // *string to *StringHeader
fmt.Println(*(*[1]byte)(unsafe.Pointer(hdr.Data))) // 底層存儲的是 utf 編碼后的 byte 數組
arr := [1]byte{65}
hdr.Data = uintptr(unsafe.Pointer(&arr))
hdr.Len = len(arr)
ss := *(*string)(unsafe.Pointer(hdr))
fmt.Println(ss) // A
arr[0] = 66
fmt.Println(ss) //B
}
在業務上, 經常遇到 string 和 []byte 的相互轉換。我們知道, string 底層其實也是存儲的一個 byte 數組, 可以通過 reflect 直接獲取 string 指向的 byte 數組, 賦值給 byte 切片, 避免內存拷貝。
func StrToByte(str string) []byte {
return []byte(str)
}
func StrToByteV2(str string) (b []byte) {
bh := (*reflect.SliceHeader)(unsafe.Pointer(&b))
sh := (*reflect.StringHeader)(unsafe.Pointer(&str))
bh.Data = sh.Data
bh.Cap = sh.Len
bh.Len = sh.Len
return b
}
// go test -bench .
func BenchmarkStrToArr(b *testing.B) {
for i := 0; i < b.N; i++ {
StrToByte(`{"f": "v"}`)
}
}
func BenchmarkStrToArrV2(b *testing.B) {
for i := 0; i < b.N; i++ {
StrToByteV2(`{"f": "v"}`)
}
}
//goos: darwin
//goarch: amd64
//pkg: github.com/demo/lsafe
//cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz
//BenchmarkStrToArr-12 264733503 4.311 ns/op
//BenchmarkStrToArrV2-12 1000000000 0.2528 ns/op
通過觀察 string 和 byte 的內存布局我們可以知道, 無法直接將 string 轉為 []byte 「確實 cap 字段」, 但是可以直接將 []byte 轉為 string
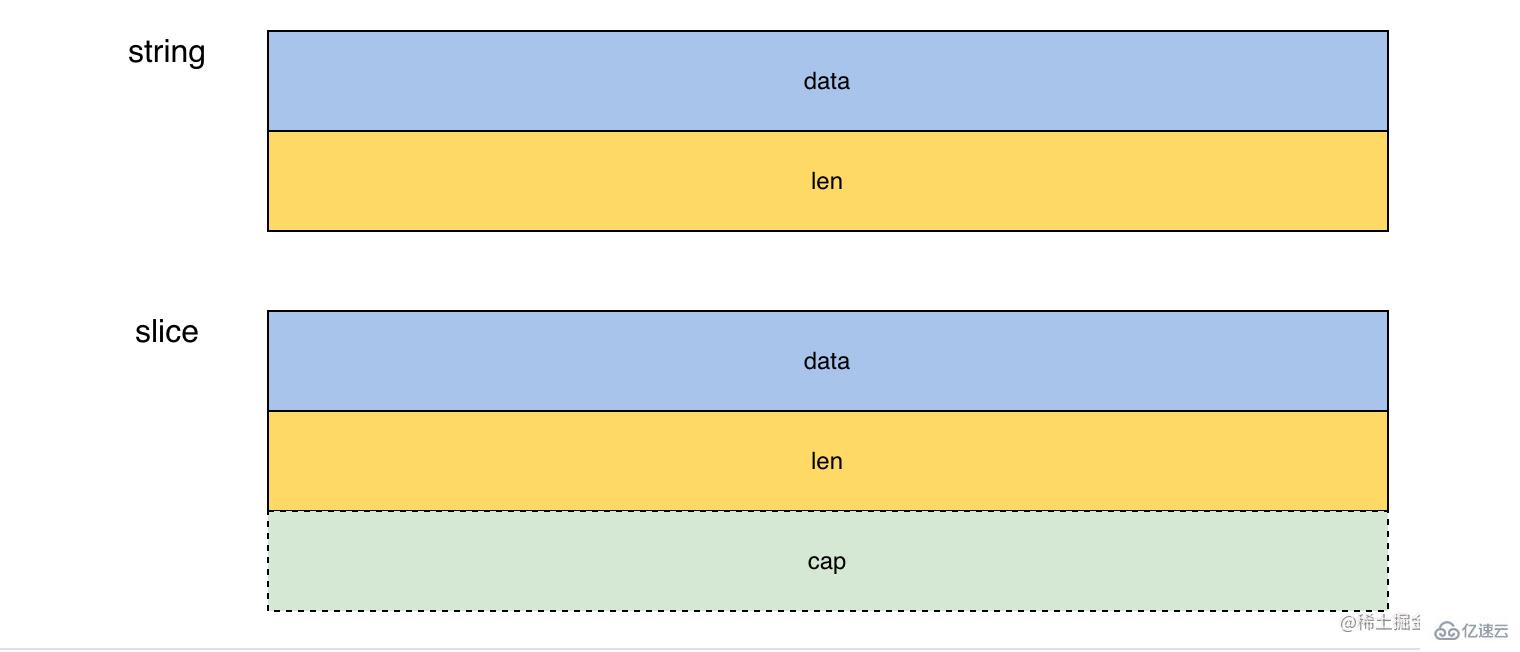
func ByteToStr(b []byte) string {
return string(b)
}
func ByteToStrV2(b []byte) string {
return *(*string)(unsafe.Pointer(&b))
}
// go test -bench .
func BenchmarkArrToStr(b *testing.B) {
for i := 0; i < b.N; i++ {
ByteToStr([]byte{65})
}
}
func BenchmarkArrToStrV2(b *testing.B) {
for i := 0; i < b.N; i++ {
ByteToStrV2([]byte{65})
}
}
//goos: darwin
//goarch: amd64
//pkg: github.com/demo/lsafe
//cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz
//BenchmarkArrToStr-12 536188455 2.180 ns/op
//BenchmarkArrToStrV2-12 1000000000 0.2526 ns/op
以上就是“Golang中的unsafe包有什么用”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





