溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了ava如何實現一致性Hash算法的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇ava如何實現一致性Hash算法文章都會有所收獲,下面我們一起來看看吧。
將key映射到 2^32 - 1 的空間中,將這個數字的首尾相連,形成一個環
計算節點(使用節點名稱、編號、IP地址)的hash值,放置在環上
計算key的hash值,放置在環上,順時針尋找到的第一個節點,就是應選取的節點
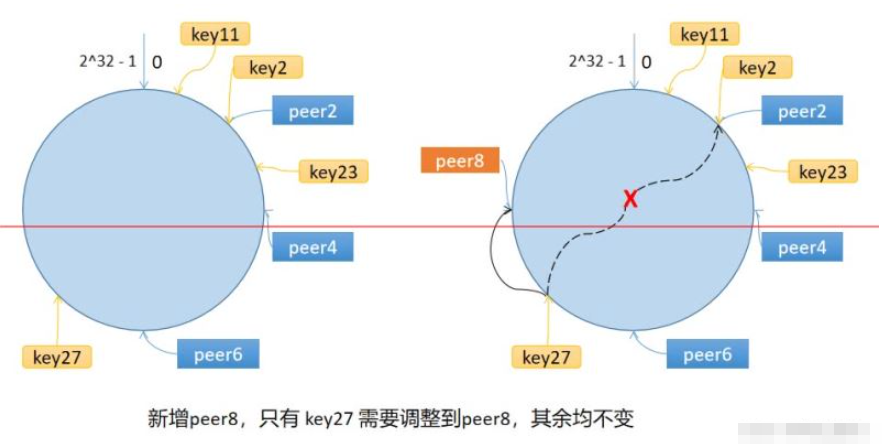
例如:p2、p4、p6三個節點,key11、key2、key27按照順序映射到p2、p4、p6上面,假設新增一個節點p8在p6節點之后,這個時候只需要將key27從p6調整到p8就可以了;也就是說,每次新增刪除節點時,只需要重新定位該節點附近的一小部分數據
如果服務器的節點過少,容易引起key的傾斜。例如上面的例子中p2、p4、p6分布在環的上半部分,下半部分是空的。那么映射到下半部分的key都會被分配給p2,key過度傾斜到了p2緩存間節點負載不均衡。
為了解決這個問題,引入了虛擬節點的概念,一個真實的節點對應多個虛擬的節點
假設1個真實的節點對應3個虛擬節點,那么p1對應的就是p1-1、p1-2、p1-3
計算虛擬節點的Hash值,放置在環上
計算key的Hash值,在環上順時針尋找到對應選取的虛擬節點,例如:p2-1,對應真實的節點p2
虛擬節點擴充了節點的數量,解決了節點較少的情況下數據傾斜的問題,而且代價非常小,只需要新增一個字典(Map)維護真實的節點與虛擬節點的映射關系就可以了
這里使用了泛型的方式來保存數據,可以根據不同的類型,獲取到不同的節點存儲
public class ConsistentHash<T> {
//自定義hash方法
private Hash<Object> hashMethod;
//創建hash映射,虛擬節點映射真實節點
private final Map<Integer, T> hashMap = new ConcurrentHashMap<>();
//將所有的hash保存起來
private List<Integer> keys = new ArrayList<>();
//默認虛擬節點數量
private final int replicas;
public ConsistentHash() {
this(3, Utils::rehash);
}
public ConsistentHash(int replicas, Hash<Object> hashMethod) {
this.replicas = replicas;
this.hashMethod = hashMethod;
}
@SafeVarargs
public final void add(T... keys) {
for (T key : keys) {
//根據虛擬節點個數來計算虛擬節點
for (int i = 0; i < this.replicas; i++) {
//根據函數獲取到對應的hash值
int hash = this.hashMethod.hash(i + ":" + key.toString());
this.keys.add(hash);
this.hashMap.put(hash, key);
}
}
//排序,因為是一個環狀結構
Collections.sort(this.keys);
}
/**
* 根據對應的key來獲取到節點信息
*
* @param key
* @return
*/
public T get(Object key) {
Objects.requireNonNull(key, "key不能為空");
int hash = this.hashMethod.hash(key);
//獲取到對應的節點信息
int idx = Utils.search(this.keys.size(), h -> this.keys.get(h) >= hash);
//如果idx == this.keys.size() ,就代表需要取 this.keys.get(0); 因為是環狀,所以需要使用 % 來進行處理
return this.hashMap.get(this.keys.get(idx % this.keys.size()));
}
}這里定義了一個函數結構,用于自定計算hash值
@FunctionalInterface
public static interface Hash<T> {
/**
* 計算hash值
*
* @param t
* @return int類型
*/
int hash(T t);
}由于hashcode采用的int類型進行存儲,那么就需要考慮,hash是否超過了int最大存儲,如果超過了那么存儲的數字就是負數,會對獲取節點造成影響,所以這里在取hash值時,采用了hashmap中獲取到hashcode之后對其進行與操作,可以減少hash沖突,也可以避免負數的產生
public static class Utils {
// int類型的最大數據
static final int HASH_BITS = 0x7fffffff;
/**
* 通過二分查找法,定義數組索引位置
*
* @param len
* @param f
* @return
*/
public static int search(int len, Function<Integer, Boolean> f) {
int i = 0, j = len;
//通過二分查找發來定為索引位置
while (i < j) {
//長度除于2
int h = (i + j) >> 1;
//調用函數,判斷當前的索引值是否大于
if (f.apply(h)) {
//向低半段進行遍歷
j = h;
} else {
//向高半段進行遍歷
i = h + 1;
}
}
return i;
}
/**
* 將返回的hash能夠平均的計算在 int類型之間
*
* @param o
* @return
*/
public static int rehash(Object o) {
int h = o.hashCode();
return (h ^ (h >>> 16)) & HASH_BITS;
}
}下面是main方法進行測試,在后面新增了一個節點之后,只會調整 zs 數據到 109 節點,而且其他兩個key的獲取不會受到影響
public static void main(String[] args) {
ConsistentHash<String> consistentHash = new ConsistentHash<>();
consistentHash.add("192.168.2.106", "192.168.2.107", "192.168.2.108");
Map<String, Object> map = new HashMap<>();
map.put("zs", "192.168.2.108");
map.put("999999", "192.168.2.106");
map.put("233333", "192.168.2.106");
map.forEach((k, v) -> {
String node = consistentHash.get(k);
if (!v.equals(node)) {
throw new IllegalArgumentException("節點獲取錯誤,key:" + k + ",獲取到的節點值為:" + node);
}
});
consistentHash.add("192.168.2.109");
map.put("zs", "192.168.2.109");
map.forEach((k, v) -> {
String node = consistentHash.get(k);
if (!v.equals(node)) {
throw new IllegalArgumentException("節點獲取錯誤,key:" + k + ",獲取到的節點值為:" + node);
}
});
}關于“ava如何實現一致性Hash算法”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“ava如何實現一致性Hash算法”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





