溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“Golang并發編程之GMP模型怎么實現”,內容詳細,步驟清晰,細節處理妥當,希望這篇“Golang并發編程之GMP模型怎么實現”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
傳統的并發編程模型是基于線程和共享內存的同步訪問控制的,共享數據受鎖的保護,線程將爭奪這些鎖以訪問數據。通常而言,使用線程安全的數據結構會使得這更加容易。Go的并發原語(goroutine和channel)提供了一種優雅的方式來構建并發模型。Go鼓勵在goroutine之間使用channel來傳遞數據,而不是顯式地使用鎖來限制對共享數據的訪問。
Do not communicate by sharing memory; instead, share memory by communicating.
這就是Go的并發哲學,它依賴CSP(Communicating Sequential Processes)模型,它經常被認為是 Go 在并發編程上成功的關鍵因素。
進程,是一段程序的執行過程,是指令、數據及其組織形式的描述,進程是正在執行的程序的實例。進程擁有自己的獨立空間。
傳統的操作系統中,每個進程有一個地址空間和至少一個控制線程,這幾乎可以認為是進程的定義。而這個地址空間中,可以存在多個控制線程的情形,這些線程可以理解為輕量級的進程,除了他們共享地址空間。多線程有以下好處:
在許多應用中同時發生著多種活動,其中某些活動會被阻塞,比如I/O操作,而某些程序則需要響應迅速,比如界面請求,因此多線程的程序設計模型會變得更簡單;
線程比進程更加輕量級,所以其創建、銷毀和上下文切換都更快;
在多CPU的系統中,多線程可以實現真正的并行。
在操作系統中,進程是操作系統資源分配的單位;線程是處理器調度和執行的基本單位。
Linux中的進程和線程
在Linux中,所有的線程都當做進程來實現,二者的區別在于:進程擁有自己的頁表(即地址空間),而線程沒有,只能和同一進程內的其他線程共享同一份頁表。這個區別的根本原因在于二者調用系統時的傳參不同而已。
在Linux2.3.3開始,glibc的fork()函數創建進程時是調用系統調用clone(2)時指定flags為SIGCHLD(共享信號句柄表)。而pthread_create創建線程時,內部也是調用clone函數,其指定的flags如下:
const int clone_flags = (CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SYSVSEM | CLONE_SIGHAND | CLONE_THREAD | CLONE_SETTLS | CLONE_PARENT_SETTID | CLONE_CHILD_CLEARTID | 0);
clone的函數形式如下:
int clone(int (* fn )(void *), void * stack , int flags , void * arg , ... /* pid_t * parent_tid , void * tls , pid_t * child_tid */ );
其實Docker底層實現隔離技術,也利用了clone函數這一系統調用。
線程可以分為內核線程和用戶線程,用戶線程必須依托于內核線程,實現調度,這樣就帶來了三種線程模型:多對一(M:1)、一對一(1:1)和多對多(M:N)(用戶線程對內核線程)。一個用戶線程必須綁定一個內核線程才能執行,不過CPU并不知道有用戶線程的存在。
1.1.1 多對一用戶級線程模型
這種模型是多個用戶線程對應一個內核調度線程,所有的線程的創建、銷毀和調度都由用戶空間的線程庫實現,內核不感知這些線程的切換。優點是線程的上下文切換之間不需要陷入內核,速度快。缺點是一旦有一個用戶線程有阻塞性的系統調用,比如I/O操作時,系統內核接管后,會阻塞所有的線程。另外,在多處理器的機器上,這種線程模型是沒有意義的,無法發揮多核系統的優勢。
1.1.2 一對一內核級線程模型
一對一模型中,每個用戶線程擁有一個對應的內核調度線程,也就是說,內核會對每個線程進行調度。也因此,線程的創建、銷毀和上下文切換,都會陷入到內核態。目前,Linux采用的NPTL(Native POSIX Threads Library)的線程模型就是一對一模型。比如以下例子:
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
void *f(void *arg){
if (!arg) {
printf("arg is NULL\n");
} else {
printf("%s\n", (char *)arg);
}
sleep(100);
return NULL;
}
int main() {
pthread_t p1, p2;
int res;
char *p2String = "I am p2!";
// 創建p1線程
res = pthread_create(&p1, NULL, f, NULL);
if (res != 0) {
printf("創建線程1失敗!\n");
return 0;
}
printf("創建線程1\n");
sleep(5);
// 創建p1線程
res = pthread_create(&p2, NULL, f, (void *)p2String);
if (res != 0) {
printf("創建線程2失敗!\n");
return 0;
}
printf("創建線程2\n");
sleep(100);
return 0;
}在程序中,我們創建了兩個線程,執行如下:
$ gcc thread.c -o thread_c -lpthread
$ ./thread_c
創建線程1
arg is NULL
創建線程2
I am p2!
然后查看進程號和此進程下的線程數。
$ ps -ef | grep thread_c
chenyig+ 5293 5087 0 19:02 pts/0 00:00:00 ./thread_c
chenyig+ 5459 5347 0 19:03 pts/1 00:00:00 grep --color=auto thread_c
$ cat /proc/5293/status | grep Threads
Threads: 3
之所以線程數是3,是因為系統啟動進程的時候就自帶一個線程,再加上創建的兩個線程,所以總數是3,這也證明了Linux的線程模型是1:1的。
1.1.3 多對多兩級線程模型
在多對多模型中,結合了1:1模型和M:1模型的優點,避免了他們的缺點。每個用戶線程擁有多個內核調度線程,也可以多個用戶線程對應一個調度實體。缺點是線程的調度需要內核態和用戶態一起實現,導致模型實現十分復雜。NPTL也曾考慮過使用該模型,但是實現太過復雜,需要對內核進行大范圍的改動,所以還是采用了1:1模型。現階段,Go中的協程goroutine就是采用該模型實現的。
package main
import (
"fmt"
"sync"
"time"
)
func f(i int) {
fmt.Printf("I am goroutine %d\n", i)
time.Sleep(100 * time.Second)
}
func main() {
wg := sync.WaitGroup{}
for i := 0; i < 100; i++ {
idx := i
wg.Add(1)
go func() {
defer wg.Done()
f(idx)
}()
}
wg.Wait()
}運行后:
$ go build -o thread_go goroutine.go
$ ./thread_go
I am goroutine 7
I am goroutine 4
I am goroutine 0
I am goroutine 6
I am goroutine 1
I am goroutine 2
I am goroutine 9
I am goroutine 3
I am goroutine 5
I am goroutine 8
然后查看進程號和此進程下的線程數。
$ ps -ef | grep thread_go
chenyig+ 69705 67603 0 17:17 pts/0 00:00:00 ./thread_go
chenyig+ 69735 68420 0 17:17 pts/2 00:00:00 grep --color=auto thread_go
$ cat /proc/69705/status | grep Threads
Threads: 5
可以看到,用戶線程(goroutine)和內核線程并不是一一對應的,而是多對多的情形。
Go在2012年正式引入GMP模型,然后在1.2版本中引入了協作式的搶占式調度,在1.14版本中實現了基于信號的搶占式調度,并一直沿用至今。
GMP模型中:
G:取Goroutine的首字母,即用戶態的線程,也叫協程;
M:取Machine的首字母,和內核線程一一對應,為簡單理解,我們可以認為其就是內核線程;
P:取Processor的首字母,表示處理器(可以理解成用戶態的協程調度器),是G和M之間的中間層,負責協程調度。
Goroutine是Go語言調度器中執行的任務實體,其在runtime調度器中的地位與線程在操作系統中的差不多。作為更細粒度的資源調度單元,和線程相比,其占用更小的內存和更低的上下文切換開銷。
Goroutine在運行時的結構體是runtime.g,其結構非常復雜,我們挑選一些重要的字段進行介紹。
type g struct {
// Stack parameters.
// stack describes the actual stack memory: [stack.lo, stack.hi).
// stackguard0 is the stack pointer compared in the Go stack growth prologue.
// It is stack.lo+StackGuard normally, but can be StackPreempt to trigger a preemption.
// stackguard1 is the stack pointer compared in the C stack growth prologue.
// It is stack.lo+StackGuard on g0 and gsignal stacks.
// It is ~0 on other goroutine stacks, to trigger a call to morestackc (and crash).
stack stack // offset known to runtime/cgo
stackguard0 uintptr // offset known to liblink
stackguard1 uintptr // offset known to liblink
...
}以上是和Go運行時棧相關的字段,其中stack結構體如下,只有棧頂和棧底的地址。stackguard0是運行用戶協程g的執行棧(go棧)擴張或者收縮的檢查的搶占標記。而stackguard1是用于g0和gsignal(這二者后面會介紹)的內核棧(C棧)的擴張或者收縮的檢查的搶占標記。
// Stack describes a Go execution stack.
// The bounds of the stack are exactly [lo, hi),
// with no implicit data structures on either side.
type stack struct {
lo uintptr
hi uintptr
}另外,還有以下三個字段和搶占息息相關。
type g struct {
...
preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
preemptStop bool // transition to _Gpreempted on preemption; otherwise, just deschedule
preemptShrink bool // shrink stack at synchronous safe point
...
}此外,以下字段中,m表示當前協程占用的線程,可能為空。
type g struct {
...
m *m // current m; offset known to arm liblink
sched gobuf
...
}而sched字段存儲了Goroutine調度相關的數據,如下。
type gobuf struct {
// The offsets of sp, pc, and g are known to (hard-coded in) libmach.
//
// ctxt is unusual with respect to GC: it may be a
// heap-allocated funcval, so GC needs to track it, but it
// needs to be set and cleared from assembly, where it's
// difficult to have write barriers. However, ctxt is really a
// saved, live register, and we only ever exchange it between
// the real register and the gobuf. Hence, we treat it as a
// root during stack scanning, which means assembly that saves
// and restores it doesn't need write barriers. It's still
// typed as a pointer so that any other writes from Go get
// write barriers.
sp uintptr
pc uintptr
g guintptr
ctxt unsafe.Pointer
ret uintptr
lr uintptr
bp uintptr // for framepointer-enabled architectures
}其中:
sp:棧頂指針;
pc:程序計數器;
ctxt:函數閉包的上下文信息,即DX寄存器;
bp:棧底指針;
可以看到,goroutine的上下文切換需要保留的寄存器很少,無需保留其他的通用寄存器,至于為啥無需保留,我們留待后續解釋。
M表示操作系統的線程,Go語言使用私有結構體runtime.m表示操作系統線程,和runtime.g一樣,這個結構體包含了幾十個字段,我們也只挑選一些和我們了解其運行機制的介紹。
type m struct {
g0 *g // goroutine with scheduling stack
...
curg *g // current running goroutine
...
}其中,g0是持有調度棧的goroutine,curg是當前線程上運行的用戶goroutine。g0比較特殊,其會深度參與運行時的調度過程,包括goroutine的創建、大內存分配和CGO函數的執行。
另外,在runtime.m中,還有三個與處理器P相關的字段:p、nextp和oldp。另外還是tls字段,通過tls實現m結構體對象與工作線程之間的綁定。
type m struct {
...
p puintptr // attached p for executing go code (nil if not executing go code)
nextp puintptr
oldp puintptr // the p that was attached before executing a syscall
...
tls [tlsSlots]uintptr // thread-local storage (for x86 extern register)
...
}處理器P是線程M和協程G之間的中間層,它能提供線程需要的上下文換環境,也負責調度線程上的等待隊列,通過處理器P的調度,每一個內核線程都能執行多個goroutine,且在goroutine陷入系統調用的時候及時讓出計算資源,提高線程的利用率。
因為調度器在啟動時就會創建GOMAXPROCS個處理器,所以Go語言程序的處理器數量一定會等于GOMAXPROCS,這些處理器會綁定到不同的內核線程上。
type p struct {
...
m muintptr // back-link to associated m (nil if idle)
...
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
runnext guintptr
...
}以上,runtime.p表示P的私有結構,m表示其綁定的線程。runq表示其持有的運行goroutine隊列,最大256,runnext表示下一個要執行的goroutine。
以上是GMP中協程G、線程M和處理器P的私有結構簡介,下面將介紹Go語言調度器的實現。
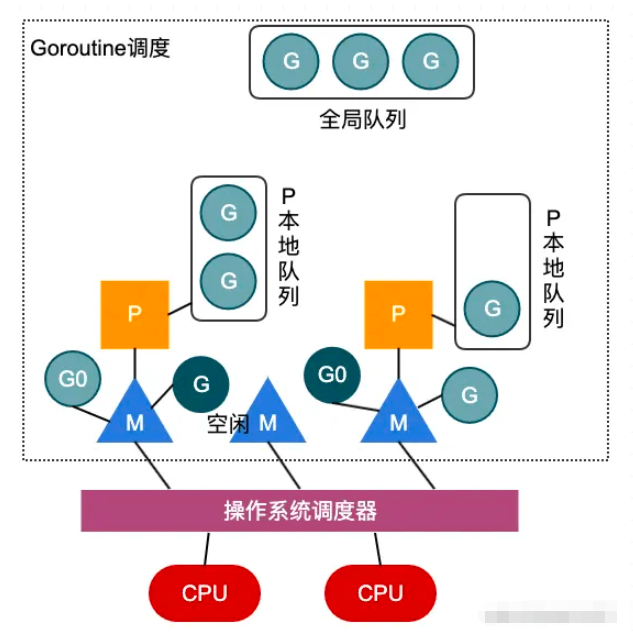
上圖簡單描述了GMP模型的工作原理,在用戶態,處理器P將自身的運行隊列中的G交付給線程M執行,通過用戶態的調度,實現goroutine之間的調度,每次切換耗費的時間約為~0.2us,低于線程上下文切換的~1us;且每次goroutine的創建,開辟的棧大小為2KB,而線程的創建,都會占用1M以上的內存空間。所以說,無論是在時間上還是空間上,用戶態的goroutine的實現都比內核線程的實現要輕量的多。
在圖中,深色G表示線程M正在執行的goroutine,而隊列中的淺色G則表示等待執行的goroutine隊列。而P的個數一般設置為CPU的核數,當然用戶可以通過runtime.GOMAXPROCS函數進行設置。而M的個數不一定,當在M上執行的G陷入內核調用而阻塞時,調度器會解綁P和M,優先在空閑M隊列中找到一個M進行執行,如果沒有空閑M,則創建一個新的M執行剩余隊列中的G,充分利用CPU的資源,所以說M的個數不一定。
讀到這里,這篇“Golang并發編程之GMP模型怎么實現”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





