溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“python架構PyNeuraLogic源碼分析”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“python架構PyNeuraLogic源碼分析”文章吧。
展示神經符號編程的力量
在過去的幾年里,我們看到了基于 Transformer 的模型的興起,并在自然語言處理或計算機視覺等許多領域取得了成功的應用。在本文中,我們將探索一種簡潔、可解釋和可擴展的方式來表達深度學習模型,特別是 Transformer,作為混合架構,即通過將深度學習與符號人工智能結合起來。為此,我們將在名為 PyNeuraLogic 的 Python 神經符號框架中實現模型。
將符號表示與深度學習相結合,填補了當前深度學習模型的空白,例如開箱即用的可解釋性或缺少推理技術。也許,增加參數的數量并不是實現這些預期結果的最合理方法,就像增加相機百萬像素的數量不一定會產生更好的照片一樣。
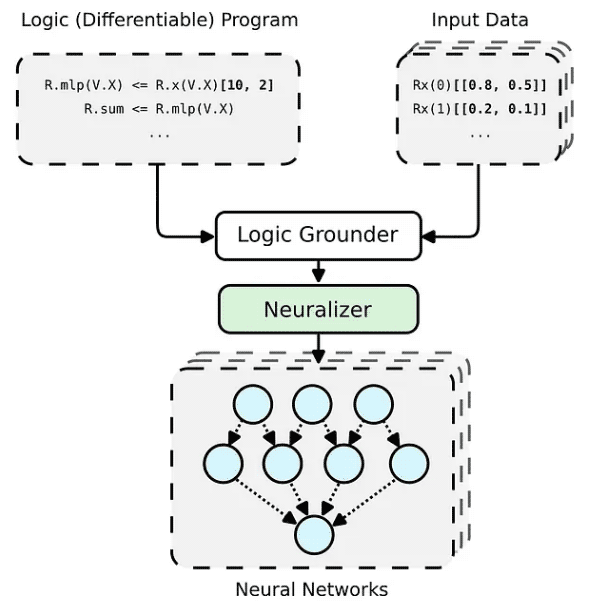
PyNeuraLogic 框架基于邏輯編程——邏輯程序包含可微分的參數。該框架非常適合較小的結構化數據(例如分子)和復雜模型(例如 Transformers 和圖形神經網絡)。另一方面,PyNeuraLogic 不是非關系型和大型張量數據的最佳選擇。
該框架的關鍵組成部分是一個可微分的邏輯程序,我們稱之為模板。模板由以抽象方式定義神經網絡結構的邏輯規則組成——我們可以將模板視為模型架構的藍圖。然后將模板應用于每個輸入數據實例,以生成(通過基礎和神經化)輸入樣本獨有的神經網絡。這個過程與其他具有預定義架構的框架完全不同,這些框架無法針對不同的輸入樣本進行自我調整。
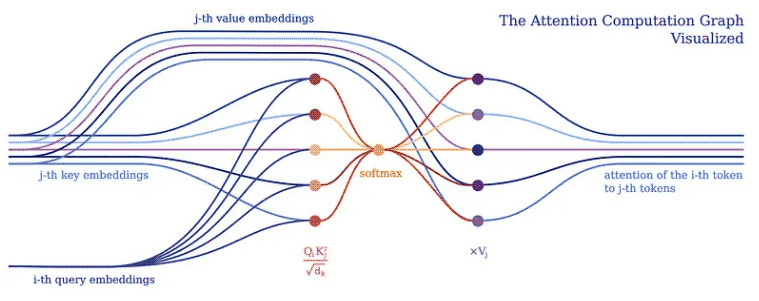
我們通常傾向于將深度學習模型實現為對批處理成一個大張量的輸入令牌的張量操作。這是有道理的,因為深度學習框架和硬件(例如 GPU)通常針對處理更大的張量而不是形狀和大小不同的多個張量進行了優化。 Transformers 也不例外,通常將單個標記向量表示批處理到一個大矩陣中,并將模型表示為對此類矩陣的操作。然而,這樣的實現隱藏了各個輸入標記如何相互關聯,這可以在 Transformer 的注意力機制中得到證明。
注意力機制構成了所有 Transformer 模型的核心。具體來說,它的經典版本使用了所謂的多頭縮放點積注意力。讓我們用一個頭(為了清楚起見)將縮放的點積注意力分解成一個簡單的邏輯程序。
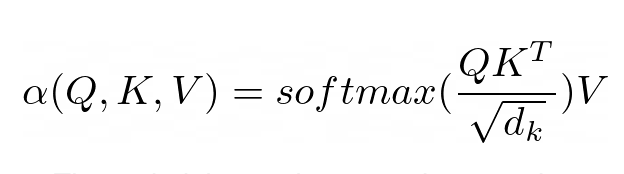
注意力的目的是決定網絡應該關注輸入的哪些部分。注意通過計算值 V 的加權和來實現,其中權重表示輸入鍵 K 和查詢 Q 的兼容性。在這個特定版本中,權重由查詢 Q 和查詢的點積的 softmax 函數計算鍵 K,除以輸入特征向量維數 d_k 的平方根。
(R.weights(V.I, V.J) <= (R.d_k, R.k(V.J).T, R.q(V.I))) | [F.product, F.softmax_agg(agg_terms=[V.J])], (R.attention(V.I) <= (R.weights(V.I, V.J), R.v(V.J)) | [F.product]
在 PyNeuraLogic 中,我們可以通過上述邏輯規則充分捕捉注意力機制。第一條規則表示權重的計算——它計算維度的平方根倒數與轉置的第 j 個鍵向量和第 i 個查詢向量的乘積。然后我們用 softmax 聚合給定 i 和所有可能的 j 的所有結果。
然后,第二條規則計算該權重向量與相應的第 j 個值向量之間的乘積,并對每個第 i 個標記的不同 j 的結果求和。
在訓練和評估期間,我們通常會限制輸入令牌可以參與的內容。例如,我們想限制標記向前看和關注即將到來的單詞。流行的框架,例如 PyTorch,通過屏蔽實現這一點,即將縮放的點積結果的元素子集設置為某個非常低的負數。這些數字強制 softmax 函數將零指定為相應標記對的權重。
(R.weights(V.I, V.J) <= ( R.d_k, R.k(V.J).T, R.q(V.I), R.special.leq(V.J, V.I) )) | [F.product, F.softmax_agg(agg_terms=[V.J])],
使用我們的符號表示,我們可以通過簡單地添加一個身體關系作為約束來實現這一點。在計算權重時,我們限制第 j 個指標小于或等于第 i 個指標。與掩碼相反,我們只計算所需的縮放點積。
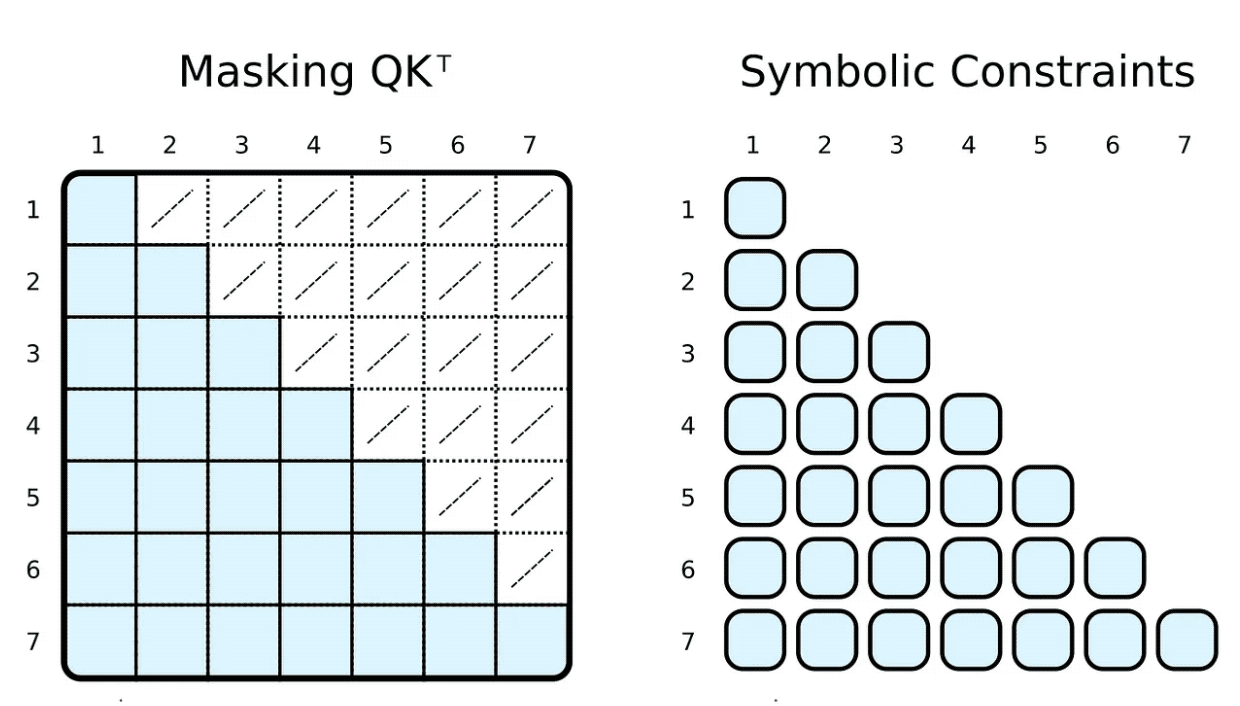
當然,象征性的“掩蔽”可以是完全任意的。我們大多數人都聽說過基于稀疏變換器的 GPT-3?(或其應用程序,例如 ChatGPT)。? 稀疏變換器的注意力(跨步版本)有兩種類型的注意力頭:
一個只關注前 n 個標記 (0 ≤ i − j ≤ n)
一個只關注每第 n 個前一個標記 ((i − j) % n = 0)
兩種類型的頭的實現都只需要微小的改變(例如,對于 n = 5)。
(R.weights(V.I, V.J) <= ( R.d_k, R.k(V.J).T, R.q(V.I), R.special.leq(V.D, 5), R.special.sub(V.I, V.J, V.D), )) | [F.product, F.softmax_agg(agg_terms=[V.J])],
(R.weights(V.I, V.J) <= ( R.d_k, R.k(V.J).T, R.q(V.I), R.special.mod(V.D, 5, 0), R.special.sub(V.I, V.J, V.D), )) | [F.product, F.softmax_agg(agg_terms=[V.J])],
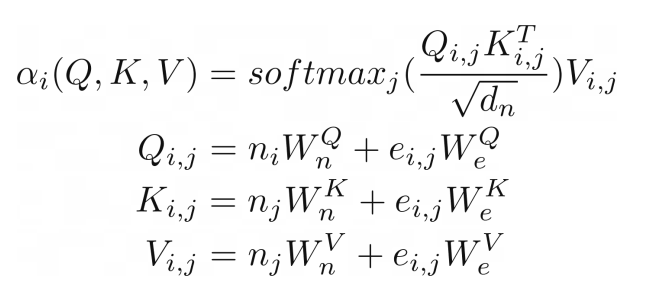
我們可以走得更遠,將對類似圖形(關系)輸入的注意力進行概括,就像在關系注意力中一樣。? 這種類型的注意力在圖形上運行,其中節點只關注它們的鄰居(由邊連接的節點)。查詢 Q、鍵 K 和值 V 是邊嵌入與節點向量嵌入相加的結果。
(R.weights(V.I, V.J) <= (R.d_k, R.k(V.I, V.J).T, R.q(V.I, V.J))) | [F.product, F.softmax_agg(agg_terms=[V.J])], (R.attention(V.I) <= (R.weights(V.I, V.J), R.v(V.I, V.J)) | [F.product], R.q(V.I, V.J) <= (R.n(V.I)[W_qn], R.e(V.I, V.J)[W_qe]), R.k(V.I, V.J) <= (R.n(V.J)[W_kn], R.e(V.I, V.J)[W_ke]), R.v(V.I, V.J) <= (R.n(V.J)[W_vn], R.e(V.I, V.J)[W_ve]),
在我們的例子中,這種類型的注意力與之前顯示的縮放點積注意力幾乎相同。唯一的區別是添加了額外的術語來捕獲邊緣。將圖作為注意力機制的輸入似乎很自然,這并不奇怪,因為 Transformer 是一種圖神經網絡,作用于完全連接的圖(未應用掩碼時)。在傳統的張量表示中,這并不是那么明顯。
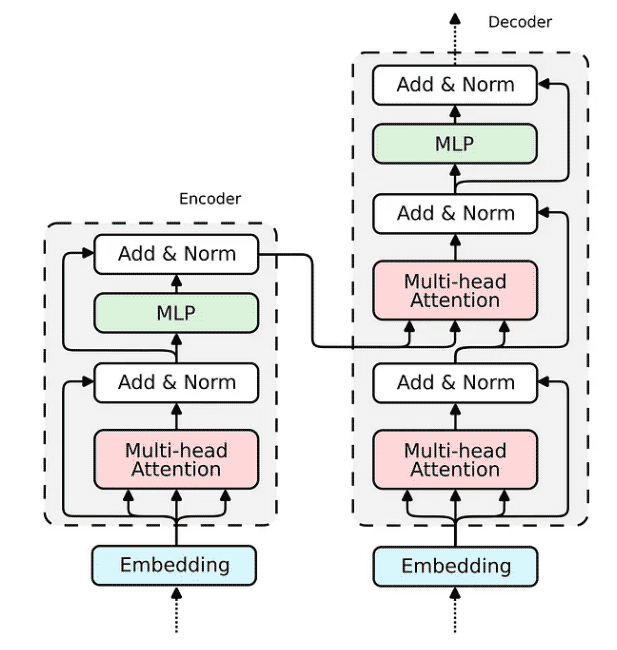
現在,當我們展示 Attention 機制的實現時,構建整個 transformer 編碼器塊的缺失部分相對簡單。
我們已經在 Relational Attention 中看到了如何實現嵌入。對于傳統的 Transformer,嵌入將非常相似。我們將輸入向量投影到三個嵌入向量中——鍵、查詢和值。
R.q(V.I) <= R.input(V.I)[W_q], R.k(V.I) <= R.input(V.I)[W_k], R.v(V.I) <= R.input(V.I)[W_v],
查詢嵌入通過跳過連接與注意力的輸出相加。然后將生成的向量歸一化并傳遞到多層感知器 (MLP)。
(R.norm1(V.I) <= (R.attention(V.I), R.q(V.I))) | [F.norm],
對于 MLP,我們將實現一個具有兩個隱藏層的全連接神經網絡,它可以優雅地表達為一個邏輯規則。
(R.mlp(V.I)[W_2] <= (R.norm(V.I)[W_1])) | [F.relu],
最后一個帶有規范化的跳過連接與前一個相同。
(R.norm2(V.I) <= (R.mlp(V.I), R.norm1(V.I))) | [F.norm],
我們已經構建了構建 Transformer 編碼器所需的所有部分。解碼器使用相同的組件;因此,其實施將是類似的。讓我們將所有塊組合成一個可微分邏輯程序,該程序可以嵌入到 Python 腳本中并使用 PyNeuraLogic 編譯到神經網絡中。
R.q(V.I) <= R.input(V.I)[W_q], R.k(V.I) <= R.input(V.I)[W_k], R.v(V.I) <= R.input(V.I)[W_v], R.d_k[1 / math.sqrt(embed_dim)], (R.weights(V.I, V.J) <= (R.d_k, R.k(V.J).T, R.q(V.I))) | [F.product, F.softmax_agg(agg_terms=[V.J])], (R.attention(V.I) <= (R.weights(V.I, V.J), R.v(V.J)) | [F.product], (R.norm1(V.I) <= (R.attention(V.I), R.q(V.I))) | [F.norm], (R.mlp(V.I)[W_2] <= (R.norm(V.I)[W_1])) | [F.relu], (R.norm2(V.I) <= (R.mlp(V.I), R.norm1(V.I))) | [F.norm],
以上就是關于“python架構PyNeuraLogic源碼分析”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





