溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“怎么使用Pandas進行數據讀取”,內容詳細,步驟清晰,細節處理妥當,希望這篇“怎么使用Pandas進行數據讀取”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
使用pandas進行數據讀取,最常讀取的數據格式如下:
NO數據類型說明使用方法1csv, tsv, txt可以讀取純文本文件pd.read_csv2excel可以讀取.xls .xlsx 文件pd.read_excel3mysql讀取關系型數據庫pd.read_sql
pd.read_csv
pandas對純文本的讀取提供了非常強力的支持,參數有四五十個。這些參數中,有的很容易被忽略,但是在實際工作中卻用處很大。pd.read_csv() 的格式如下:
read_csv( reader: FilePathOrBuffer, *, sep: str = ..., delimiter: str | None = ..., header: int | Sequence[int] | str = ..., names: Sequence[str] | None = ..., index_col: int | str | Sequence | Literal[False] | None = ..., usecols: int | str | Sequence | None = ..., squeeze: bool = ..., prefix: str | None = ..., mangle_dupe_cols: bool = ..., dtype: str | Mapping[str, Any] | None = ..., engine: str | None = ..., converters: Mapping[int | str, (*args, **kwargs) -> Any] | None = ..., true_values: Sequence[Scalar] | None = ..., false_values: Sequence[Scalar] | None = ..., skipinitialspace: bool = ..., skiprows: Sequence | int | (*args, **kwargs) -> Any | None = ..., skipfooter: int = ..., nrows: int | None = ..., na_values=..., keep_default_na: bool = ..., na_filter: bool = ..., verbose: bool = ..., skip_blank_lines: bool = ..., parse_dates: bool | List[int] | List[str] = ..., infer_datetime_format: bool = ..., keep_date_col: bool = ..., date_parser: (*args, **kwargs) -> Any | None = ..., dayfirst: bool = ..., cache_dates: bool = ..., iterator: Literal[True], chunksize: int | None = ..., compression: str | None = ..., thousands: str | None = ..., decimal: str | None = ..., lineterminator: str | None = ..., quotechar: str = ..., quoting: int = ..., doublequote: bool = ..., escapechar: str | None = ..., comment: str | None = ..., encoding: str | None = ..., dialect: str | None = ..., error_bad_lines: bool = ..., warn_bad_lines: bool = ..., delim_whitespace: bool = ..., low_memory: bool = ..., memory_map: bool = ..., float_precision: str | None = ...)
可以是文件路徑,可以是網頁上的文件,也可以是文件對象,實例如下:
# 文件路徑讀取
file_path=r"E:\VSCODE\2_numpy_pandas\pandas\Game_Data.csv"
f_df = pd.read_csv(file_path,sep=",|:|;",engine="python",header=0,encoding='gbk')
print(f_df)
# 網頁上的文件讀取
f_df = pd.read_csv("http://localhost/data.csv")
# 文件對象讀取
f = open(r"E:\VSCODE\2_numpy_pandas\pandas\Game_Data.csv", encoding="gbk")
f_df = pd.read_csv(f)讀取csv文件時指定的分隔符,默認為逗號。注意:“csv文件的分隔符” 和 “我們讀取csv文件時指定的分隔符” 一定要一致。多個分隔符時,應該使用 | 將不同的分隔符隔開;例如:
f_df = pd.read_csv(file_path,sep=":|;",engine="python",header=0)
所有的空白字符,都可以用此來作為間隔,該值默認為False, 若我們將其更改為 True 則所有的空白字符:空格,\t, \n 等都會被當做分隔符;和sep功能相似;
這兩個功能相輔相成,header 用來指定列名,例如header =0,則指定第一行為列名;若header =1 則指定第二行為列名;有時,我們的數據里沒有列名,只有數據,這時候就需要names=[], 來指定列名;詳細說明如下:
csv文件有表頭并且是第一行,那么names和header都無需指定;csv文件有表頭、但表頭不是第一行,可能從下面幾行開始才是真正的表頭和數據,這個時候指定header即可;csv文件沒有表頭,全部是純數據,那么我們可以通過names手動生成表頭;csv文件有表頭、但是這個表頭你不想用,這個時候同時指定names和header。先用header選出表頭和數據,然后再用names將表頭替換掉,其實就等價于將數據讀取進來之后再對列名進行rename;
舉例如下:
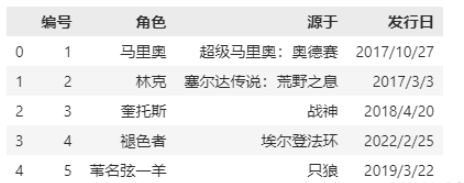
names 沒有被賦值,header 也沒賦值:
file_path=r"E:\VSCODE\2_numpy_pandas\pandas\Game_Data.csv" df=pd.read_csv(file_path,sep=",|:|;",engine="python",header=0,encoding='gbk') print(df) # 我們說這種情況下,header為變成0,即選取文件的第一行作為表頭
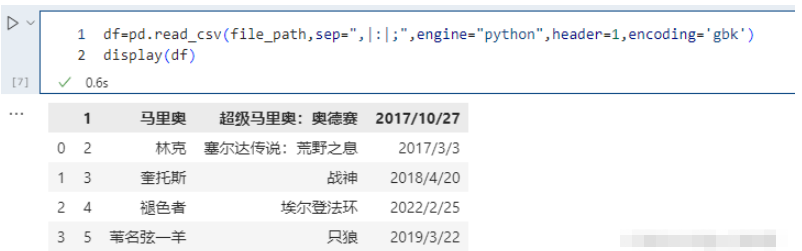
names 沒有被賦值,header 被賦值:
pd.read_csv(file_path,sep=",|:|;",engine="python",header=1,encoding='gbk') # 不指定names,指定header為1,則選取第二行當做表頭,第二行下面的是數據
names 被賦值,header 沒有被賦值
pd.read_csv(file_path,sep=",|:|;",engine="python",encoding='gbk',names=["編號", "英雄", "游戲", "發行日期"])
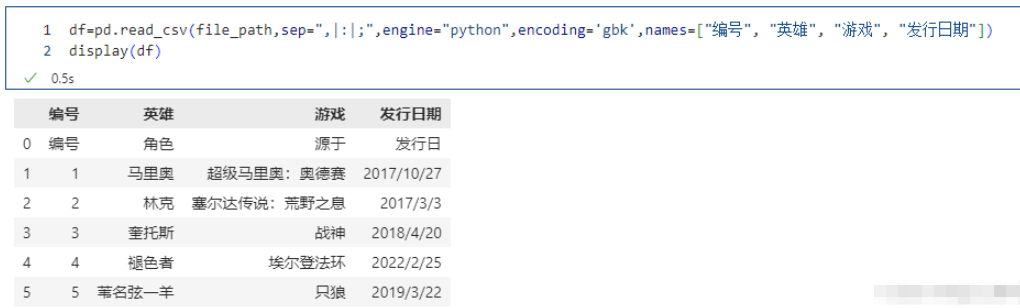
names適用于沒有表頭的情況,指定names沒有指定header,那么header相當于None。一般來說,讀取文件會有一個表頭的,一般是第一行,但是有的文件只是數據而沒有表頭,那么這個時候我們就可以通過names手動指定、或者生成表頭,而文件里面的數據則全部是內容。所以這里"編號", “角色”, “源于”, “發行日” 也當成是一條記錄了,本來它是表頭的,但是我們指定了names,所以它就變成數據了,表頭是我們在names里面指定的
names和header都被賦值:
pd.read_csv(file_path,sep=",|:|;",engine="python",encoding='gbk',names=["編號", "英雄", "游戲", "發行日期"],header=0)
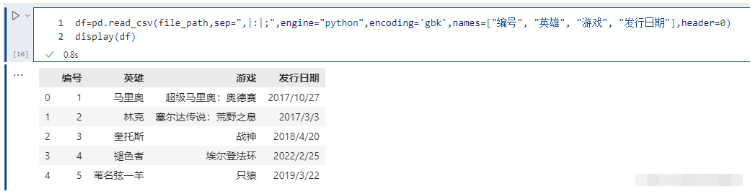
這個相當于先不看names,只看header,我們說header等于0代表什么呢?顯然是把第一行當做表頭,下面的當成數據,好了,然后再把表頭用names給替換掉。
我們在讀取文件之后,生成的 DataFrame 的索引默認是0 1 2 3…,我們當然可以 set_index,但是也可以在讀取的時候就指定某個列為索引。
pd.read_csv(file_path,engine="python",encoding='gbk',header=0,index_col="角色")
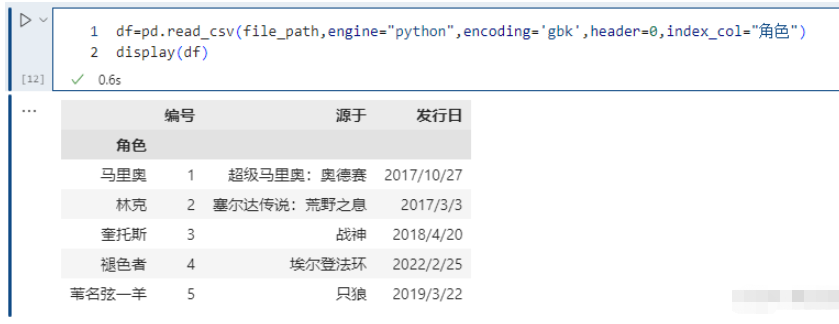
這里指定 “name” 作為索引,另外除了指定單個列,還可以指定多個列,比如 [“id”, “name”]。并且我們除了可以輸入列的名字之外,還可以輸入對應的索引。比如:“id”、“name”、“address”、“date” 對應的索引就分別是0、1、2、3。
如果列有很多,而我們不想要全部的列、而是只要指定的列就可以使用這個參數。
pd.read_csv(file_path,encoding='gbk',usecols=["角色", "發行日"])
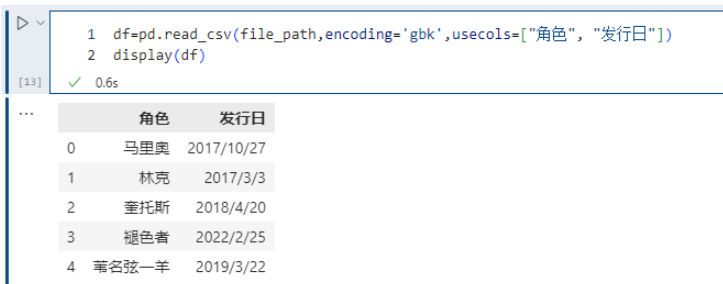
同 index_col 一樣,除了指定列名,也可以通過索引來選擇想要的列,比如:usecols=[1, 3] 也會選擇 “角色” 和 “發行日” 兩列,因為 “角色” 這一列對應的索引是 1、“發行日” 對應的索引是 3。
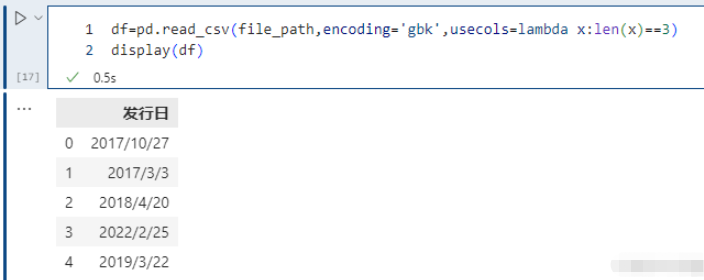
此外 use_cols 還有一個比較好玩的用法,就是接收一個函數,會依次將列名作為參數傳遞到函數中進行調用,如果返回值為真,則選擇該列,不為真,則不選擇。
# 選擇列名的長度等于 3 的列,顯然此時只會選擇 發行日 這一列 pd.read_csv(file_path,encoding='gbk',usecols=lambda x:len(x)==3)
實際生產用的數據會很復雜,有時導入的數據會含有重名的列。參數 mangle_dupe_cols 默認為 True,重名的列導入后面多一個 .1。如果設置為 False,會拋出不支持的異常:
# ValueError: Setting mangle_dupe_cols=False is not supported yet
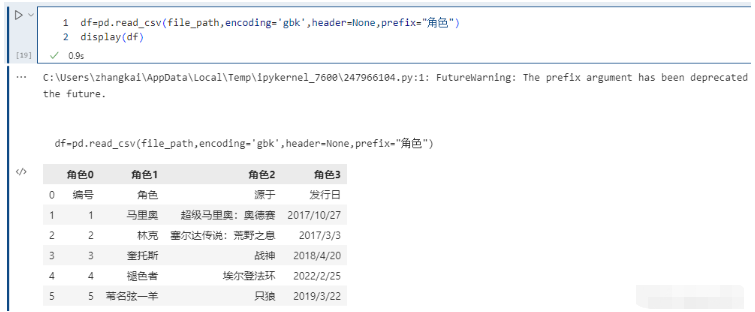
prefix 參數,當導入的數據沒有 header 時,設置此參數會自動加一個前綴。比如:
pd.read_csv(file_path,encoding='gbk',header=None,prefix="角色")
有時候,工作人員的id都是以0開頭的,比如0100012521,這是一個字符串。但是在讀取的時候解析成整型了,結果把開頭的0給丟了。這個時候我們就可以通過dtype來指定某個列的類型,就是告訴pandas:你在解析的時候不要自以為是,直接按照老子指定的類型進行解析就可以了,我不要你覺得,我要我覺得。
df=pd.read_csv(file_path,encoding='gbk',dtype={"編號": str})df["編號"]=df["編號"]*4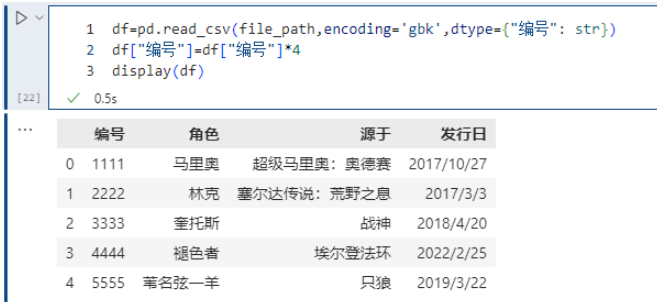
pandas解析數據時用的引擎,pandas 目前的解析引擎提供兩種:c、python,默認為 c,因為 c 引擎解析速度更快,但是特性沒有 python 引擎全。如果使用 c 引擎沒有的特性時,會自動退化為 python 引擎。
比如使用分隔符進行解析,如果指定分隔符不是單個字符、或者"\s+“,那么c引擎就無法解析了。我們知道如果分隔符為空白字符的話,那么可以指定delim_whitespace=True,但是也可以指定sep=r”\s+"。
df=pd.read_csv(file_path,encoding='gbk',dtype={"編號": str})
df["編號"]=df["編號"]*4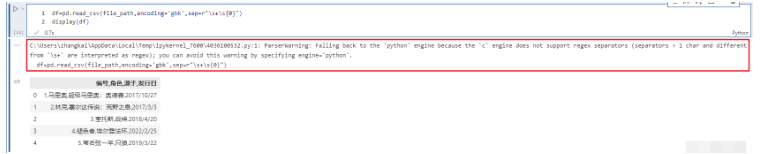
我們看到雖然自動退化,但是彈出了警告,這個時候需要手動的指定engine="python"來避免警告。這里面還用到了encoding參數,這個后面會說,因為引擎一旦退化,在Windows上不指定會讀出亂碼。這里我們看到sep是可以支持正則的,但是說實話sep這個參數都會設置成單個字符,原因是讀取的csv文件的分隔符是單個字符。
可以在讀取的時候對列數據進行變換:
pd.read_csv(file_path,encoding='gbk', converters={<!--{cke_protected}{C}%3C!%2D%2D%20%2D%2D%3E-->"編號": lambda x: int(x) + 10})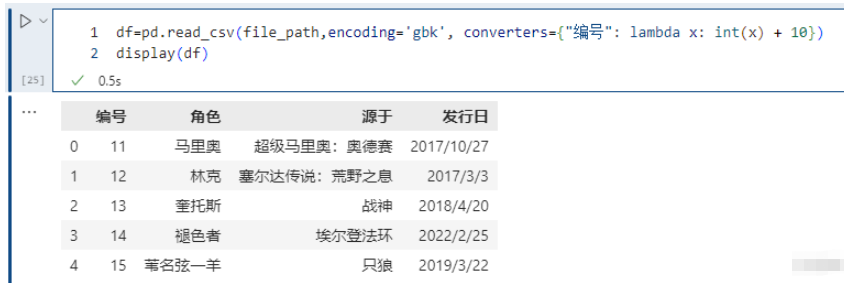
將id增加10,但是注意 int(x),在使用converters參數時,解析器默認所有列的類型為 str,所以需要顯式類型轉換。
指定哪些值應該被清洗為True,哪些值被清洗為False。
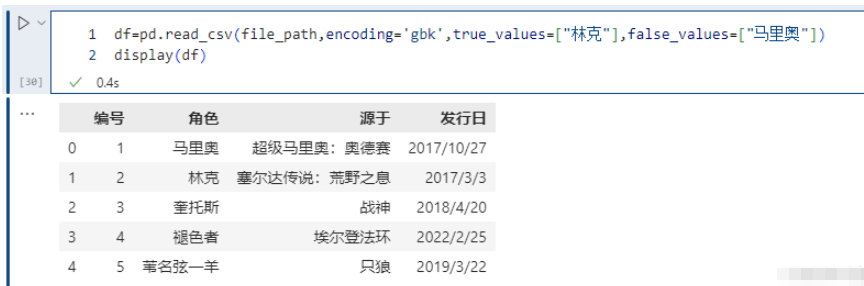
pd.read_csv(file_path,encoding='gbk',true_values=["林克","奎托斯","褪色者","葦名弦一羊"],false_values=["馬里奧"])
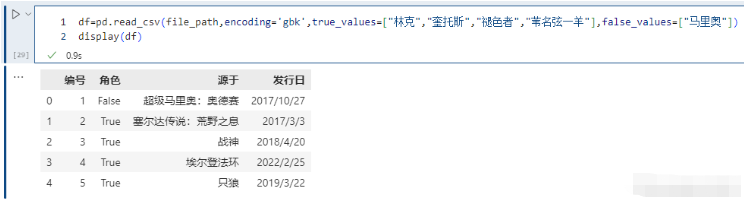
注意這里的替換規則,只有當某一列的數據全部出現在true_values + false_values里面,才會被替換。例如執行以下內容,不會發生變化;
pd.read_csv(file_path,encoding='gbk',true_values=["林克"],false_values=["馬里奧"])
skiprows 表示過濾行,想過濾掉哪些行,就寫在一個列表里面傳遞給skiprows即可。注意的是:這里是先過濾,然后再確定表頭,比如:
pd.read_csv(file_path,encoding='gbk',skiprows=[0])
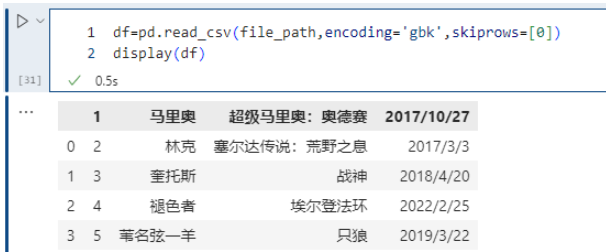
我們把第一行過濾掉了,但是第一行是表頭,所以過濾掉之后,第二行就變成表頭了。如果過濾掉第二行,那么只相當于少了一行數據,但是表頭還是原來的第一行。
當然里面除了傳入具體的數值,來表明要過濾掉哪些行,還可以傳入一個函數。
pd.read_csv(file_path,encoding='gbk',skiprows=lambda x:x>0 and x%2==1)
由于索引從0開始,凡是索引2等于1的記錄都過濾掉。索引大于0,是為了保證表頭不被過濾掉。

從文件末尾過濾行,解析引擎退化為 Python。這是因為 C 解析引擎沒有這個特性。
pd.read_csv(file_path,encoding='gbk',skipfooter=2)
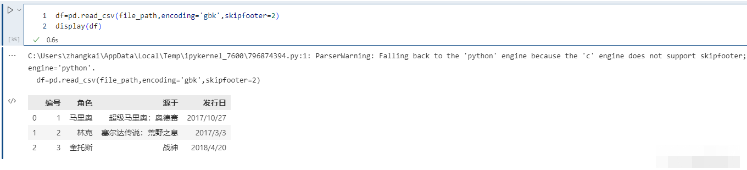
如果不想報以上的Warning, 可以將Engine 指定為Python, 如下:
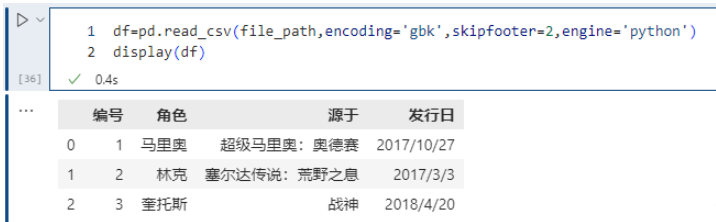
skipfooter接收整型,表示從結尾往上過濾掉指定數量的行,因為引擎退化為python,那么要手動指定engine=“python”,不然會警告。
nrows 參數設置一次性讀入的文件行數,它在讀入大文件時很有用,比如 16G 內存的PC無法容納幾百 G 的大文件。
pd.read_csv(file_path,encoding='gbk',nrows=4)
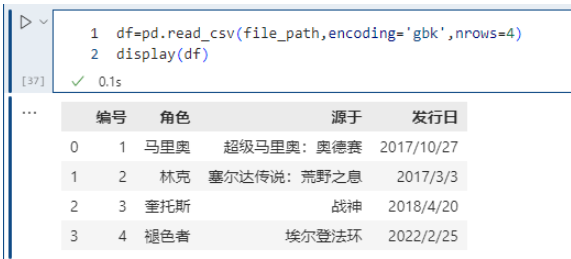
很多時候我們只是想看看大文件內部的字段長什么樣子,所以這里通過nrows指定讀取的行數。
na_values 參數可以配置哪些值需要處理成 NaN,這個是非常常用的。
pd.read_csv(file_path,encoding='gbk',na_values=['馬里奧','戰神'])
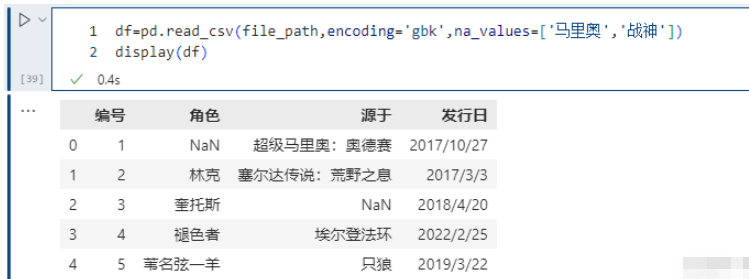
我們看到將 ‘馬里奧’ 和 ‘戰神’ 設置成了NaN,當然我們這里不同的列,里面包含的值都是不相同的。但如果兩個列中包含相同的值,而我們只想將其中一個列的值換成NaN該怎么做呢?通過字典實現只對指定的列進行替換。以下的例子可以看到,戰神并沒有被替換成NaN, 因為在角色里沒有這個值;/
pd.read_csv(file_path,encoding='gbk',na_values={<!--{cke_protected}{C}%3C!%2D%2D%20%2D%2D%3E-->"角色":['馬里奧','戰神'],'編號':[2]})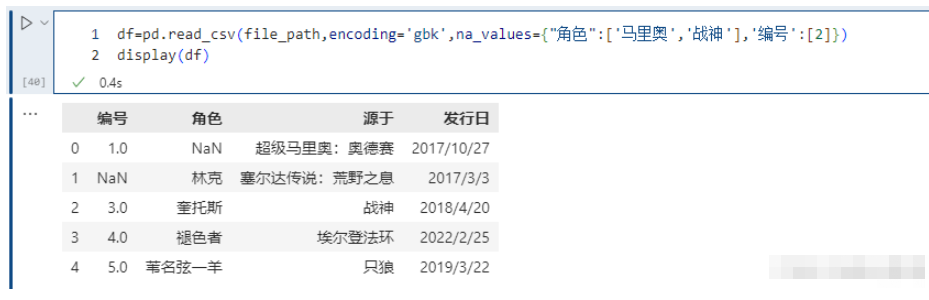
我們知道,通過 na_values 參數可以讓 pandas 在讀取 CSV 的時候將一些指定的值替換成空值,但除了 na_values 指定的值之外,還有一些默認的值也會在讀取的時候被替換成空值,這些值有: “-1.#IND”、“1.#QNAN”、“1.#IND”、“-1.#QNAN”、“#N/A N/A”、“#N/A”、“N/A”、“NA”、“#NA”、“NULL”、“NaN”、“-NaN”、“nan”、“-nan”、“” 。盡管這些值在 CSV 中的表現形式是字符串,但是 pandas 在讀取的時候會替換成空值(真正意義上的 NaN)。不過有些時候我們不希望這么做,比如有一個具有業務含義的字符串恰好就叫 “NA”,那么再將它替換成空值就不對了。
這個時候就可以將 keep_default_na 指定為 False,默認為 True,如果指定為 False,那么 pandas 在讀取時就不會擅自將那些默認的值轉成空值了,它們在 CSV 中長什么樣,pandas 讀取出來之后就還長什么樣,即使單元格中啥也沒有,那么得到的也是一個空字符串。但是注意,我們上面介紹的 na_values 參數則不受此影響,也就是說即便 keep_default_na 為 False,na_values 參數指定的值也依舊會被替換成空值。舉個栗子,假設某個 CSV 中存在 “NULL”、“NA”、以及空字符串,那么默認情況下,它們都會被替換成空值。但 “NA” 是具有業務含義的,我們希望保留原樣,而 “NULL” 和空字符串,我們還是希望 pandas 在讀取的時候能夠替換成空值,那么此時就可以在指定 keep_default_na 為 False 的同時,再指定 na_values 為 ["NULL", ""]
是否進行空值檢測,默認為 True,如果指定為 False,那么 pandas 在讀取 CSV 的時候不會進行任何空值的判斷和檢測,所有的值都會保留原樣。因此,如果你能確保一個 CSV 肯定沒有空值,則不妨指定 na_filter 為 False,因為避免了空值檢測,可以提高大型文件的讀取速度。另外,該參數會屏蔽 keep_default_na 和 na_values,也就是說,當 na_filter 為 False 的時候,這兩個參數會失效。
從效果上來說,na_filter 為 False 等價于:不指定 na_values、以及將 keep_default_na 設為 False。
skip_blank_lines 默認為 True,表示過濾掉空行,如為 False 則解析為 NaN。
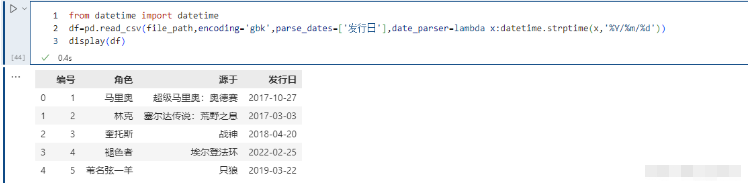
指定某些列為時間類型,這個參數一般搭配下面的date_parser使用。
是用來配合parse_dates參數的,因為有的列雖然是日期,但沒辦法直接轉化,需要我們指定一個解析格式:
from datetime import datetime pd.read_csv(file_path,encoding='gbk',parse_dates=['發行日'],date_parser=lambda x:datetime.strptime(x,'%Y/%m/%d'))
infer_datetime_format 參數默認為 False。如果設定為 True 并且 parse_dates 可用,那么 pandas 將嘗試轉換為日期類型,如果可以轉換,轉換方法并解析,在某些情況下會快 5~10 倍。
iterator 為 bool類型,默認為False。如果為True,那么返回一個 TextFileReader 對象,以便逐塊處理文件。這個在文件很大、內存無法容納所有數據文件時,可以分批讀入,依次處理。
df=pd.read_csv(file_path,encoding='gbk',iterator=True)
display(df.get_chunk(2))
"""
編號 角色 源于 發行日
0 1 馬里奧 超級馬里奧:奧德賽 2017/10/27
1 2 林克 塞爾達傳說:荒野之息 2017/3/3
"""
print(chunk.get_chunk(1))
"""
編號 角色 源于 發行日
2 3 奎托斯 戰神 2018/4/20
"""
# 文件還剩下三行,但是我們指定讀取10,那么也不會報錯,不夠指定的行數,那么有多少返回多少
print(chunk.get_chunk(10))
"""
編號 角色 源于 發行日
3 4 褪色者 埃爾登法環 2022/2/25
4 5 葦名弦一羊 只狼 2019/3/22
"""
try:
# 但是在讀取完畢之后,再讀的話就會報錯了
chunk.get_chunk(5)
except StopIteration as e:
print("讀取完畢")
# 讀取完畢chunksize 整型,默認為 None,設置文件塊的大小。
chunk = pd.read_csv(file_path, sep="\t", chunksize=2)
# 還是返回一個類似于迭代器的對象
# 調用get_chunk,如果不指定行數,那么就是默認的chunksize
print(chunk.get_chunk())
"""
編號 角色 源于 發行日
0 1 馬里奧 超級馬里奧:奧德賽 2017/10/27
1 2 林克 塞爾達傳說:荒野之息 2017/3/3
"""
# 但也可以指定
print(chunk.get_chunk(100))
"""
編號 角色 源于 發行日
2 3 奎托斯 戰神 2018/4/20
3 4 褪色者 埃爾登法環 2022/2/25
4 5 葦名弦一羊 只狼 2019/3/22
"""
try:
chunk.get_chunk(5)
except StopIteration as e:
print("讀取完畢")
# 讀取完畢compression 參數取值為 {‘infer’, ‘gzip’, ‘bz2’, ‘zip’, ‘xz’, None},默認 ‘infer’,這個參數直接支持我們使用磁盤上的壓縮文件。
# 直接將上面的.csv添加到壓縮文件,打包成game_data.zip
pd.read_csv('game_data.zip', compression="zip",encoding='gbk')千分位分割符,如 , 或者 .,默認為None。
encoding 指定字符集類型,通常指定為 ‘utf-8’。根據情況也可能是’ISO-8859-1’,本文中所有的encoding='gbk' ,主要原因為:我的數據是用Excel 保存成.CSV的,默認的編碼格式為GBK;
如果一行包含過多的列,假設csv的數據有5列,但是某一行卻有6個數據,顯然數據有問題。那么默認情況下不會返回DataFrame,而是會報錯。
我們在某一行中多加了一個數據,結果顯示錯誤。因為girl.csv里面有5列,但是有一行卻有6個數據,所以報錯。
在小樣本讀取時,這個錯誤很快就能發現。但是如果樣本比較大、并且由于數據集不可能那么干凈,會很容易出現這種情況,那么該怎么辦呢?而且這種情況下,Excel基本上是打不開這么大的文件的。這個時候我們就可以將error_bad_lines設置為False(默認為True),意思是遇到這種情況,直接把這一行給我扔掉。同時會設置 warn_bad_lines 設置為True,打印剔除的這行。
pd.read_csv(file_path,encoding='gbk',error_bad_lines=False, warn_bad_lines=True)
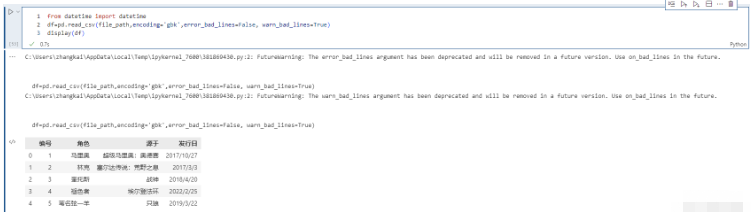
以上兩參數只能在C解析引擎下使用。
讀到這里,這篇“怎么使用Pandas進行數據讀取”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





