溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Mysql中on,in,as,where的區別是什么”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Mysql中on,in,as,where的區別是什么”吧!
答:Where查詢條件,on內外連接時候用,as作為別名,in查詢某值是否在某條件里
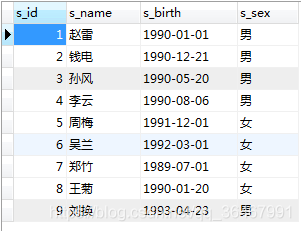
創建2個表:student,score
student:
score:

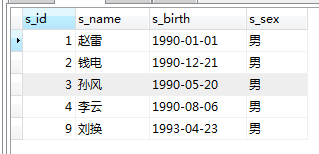
where
SELECT * FROM student WHERE s_sex='男'
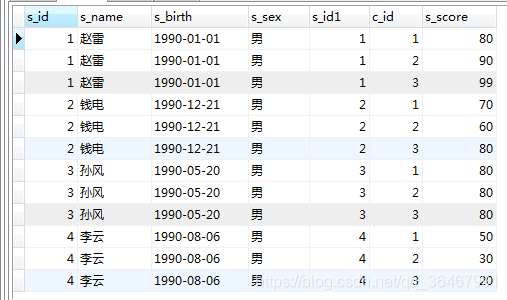
例如:on
SELECT * FROM student LEFT JOIN score on student.s_id=score.s_id;
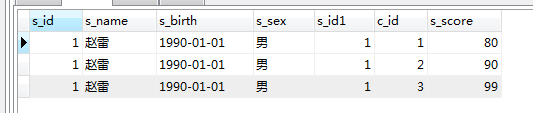
on和where組合:
SELECT * FROM student LEFT JOIN score on student.s_id=score.s_id WHERE s_name='趙雷'
例如:in
SELECT * FROM score WHERE s_id in (SELECT s_id FROM student WHERE s_name='趙雷')

as
select * from score as a LEFT JOIN student as b on a.s_id=b.s_id where s_name='趙雷'
on后面的條件只能對left join右邊的表進行篩選,左表匹配不到右表數據會在原右表位置處顯示null,left join左邊的表數據不受約束,將on后的條件加到where后會對所有數據進行篩選。
with <name> as()
mysql內可以使用with as生成臨時表,<name>為臨時表的名字,使用如下:
with arc as( select id,arc.title,update_time,is_top,cId,pid,name_id from article arc where is_del = 0 ) select * from arc
with...as的作用范圍只有一次sql執行的時間,執行過后就不再存在,根據例子我們本要處理article表,但表里的數據并非都是我們需要的,所系先篩選建立了一個臨時表arc,我們會對arc進行操作。
如果只是上述例子的簡單操作是沒必要使用with...as的,但是當我們需要將article表與其他表進行聯查甚至嵌套時,會出現要多次進行is_del = 0的判斷,最終出來的sql語句可能個十分復雜,并且極易出錯,但使用arc就不需要在對數據進行重復篩選了。
with...as里的sql可以更復雜些,比如article表里有name_id,但更多時候我們希望使用name,我們可以預先在with...as內查找好,再使用臨時表去做其他操作。
這算是個比較經典的一個問題了,我初學,只會一種解題方法,但會盡力講的簡單通俗點。
示例:
select * from ( select cId,title,content( select count(*)+1 from arc a1 where (a1.cId = a2.cId) and a1.updateTime > a2.updateTime )updateTimeSort from arc a2 ) a3 where updateTimeSort <= 3 order by cId,updateTime desc
示例中cId是類別id,updateTime 是更新時間,解決問題是選取arc內每個類別最晚更新的的三條數據,就像新聞的首頁需要為每個分類選出最新的三條新聞,按照數據庫里的數據我們可以使用排序 order by cId,updateTime desc 對數據按類別和更新時間進行排序,但去取每個類別的特定幾條數據,現有數據庫是做不到的,因此我們可以添加一個臨時字段。
updateTimeSort 它表示的是每個類別中每個子項在這個類別中的排序,在當前問題中這個臨時字段應該是和字段 updateTime 相關的,根據更新時間為類別中的每個子項排出順序。
如示例代碼,我們能找到a1和a2這兩個表,他們都是arc表的別稱,通過子查詢的形式結合在一起,以a2為主,去a1表內查找類別和a2當前數據相同的,并且更新時間晚于a2當前數據的數據數量,能看到 count(*)+1 也就是數量加一了,不加一也可以,只是當一條數據在它所處類別更新時間最晚時count(*) 的值是0,若果使用count(*)+1 我們就可以將數據從1開始排序。
最終我們只要選取 updateTimeSort <= 3 的數據即可,如果想要篩選最早發布的新聞也只需要將updateTimeSort 的篩選邏輯變更一下即可,在示例代碼中即將
a1.updateTime > a2.updateTime 更改為 a1.updateTime < a2.updateTime
可以看到示例代碼中還有一個表a3,它其實時一個臨時表,前面我們了解了with..as可以生成臨時表,也重這次代碼中可以看出,臨時表也可以以另一種形式存在,with...as我們只有當sql復雜時才會使用,一般來說現在這種方式能幫我們解決不少問題了,各有優劣,看情況使用。
接觸sql多了會發現,sql其實能幫我們解決一定的業務問題,明顯的有sql的存儲過程和方法,對sql語句的批量處理其實在一定程度上幫我們解決一定的業務問題,但缺點也很明顯,當新手接觸這個項目時他很難搞清楚某個功能到底是如何實現的,不利于維護。
一般來說我們解決業務是在server層,有時會使用sql解決一些問題,但很少,在sever處理受制于計算機硬件,在數據庫處理受制于數據庫性能,相比之下,計算機硬件更易于擴展,因此還是不推薦大量使用sql解決問題的。
例如上個問題:根據某個字段排序取每個類別最后三條數據或前三條數據問題,雖然問題基本解決但讓存在一些 ‘bug’,例如排序時會產生1、2、3、3、4這種排序,這是因為同個類別內有兩條數據更新時間重復了,那我們直觀想法(還是要看個人經驗值)應該是,既然問題出在數據庫,那應該在數據庫查詢的時候就解決這個問題,但事實上,讓數據庫去解決并不好解決,數據庫的強項在于各種搜索算法,不在于邏輯處理,因此我們就要轉移到server層處理,會有不少人陷于這個坑,花費大量時間去找辦法讓數據庫去處理這類問題,但其實就算數據庫處理得了,它也不一定有server層處理的效率高,當然如果是為了學習更多東西,這些時間也是值得花的,但是這種解題思路還是要改變下的。將1、2、3、3、4問題交給server處理也就是利用java等高級語言處理這種問題,相信熟用這些語言的開發者解決這些問題都是小case了。
先復習下知識:用過count函數的人都清楚一旦使用count這類聚合函數,不做其他處理數據就會歸為一行數據,但很多時候我們并不期望這樣的結果,以此就要想些辦法能用聚合函數,也能獲取很多數據,我常用的是利用group by分組。
回歸問題,現有(現不討論表是否合理)文章表(id,title,content)有文章id,標題,文章內容三個字段,點贊收藏表(id,arc_id,fav,like)有表id,文章id,收藏字段(0未收藏,1收藏),點贊字段(0未點贊,1點贊),現要查詢文章表內每篇文章的點贊收藏數,sql語句:
select art.title,art.content, count(case afl.fav when 1 then 1 end) as collectNum, count(case afl.like when 1 then 1 end) as likeNum from article art left join article_favor_like afl on afl.arc_id = art.id group by afl.arc_id //這是關鍵
如果沒有group by afl.arc_id 后果就是,查出來一行數據,數據還牛頭不對馬嘴,但通過對文章收藏表中的文章id進行分組就可以針對每個文章id查詢數據,這樣left join時右表就有每個文章id對相應的收藏數與點贊數,而不是表內所有點贊數和收藏數,最終數據也是我們所需的。
例子:
select id,title,content,1 isArc from arc union select id,name,content,0 isArc from news
使用union進行的是上下整合
被聯合的數據列數要求一致
列數相同,數據類型不同會自動進行數據類型轉換
聯合后的列的名字由聯合中第一次出現的列名為依據,即使后續被聯合數據有自己的列名也不會使用,在例子中最終列名為:id,title,content,name等列名不會使用,因此使用union一般配合別名使用統一結果。
有時候會區分數據是哪個表的,可以通過附加額外的字段來區別,就像例子中的isArc字段,news表中的isArc可以不寫,原因也就是第4條,最終列名由第一次出現的列名決定,后續數據列名有沒有都可以。
limit一般用于分頁,功能是獲取指定區間內的數據,因此我們也可以用它來減少數據庫的查詢,例子:
select * from arc where id = 12 limit 1
數據庫查詢由索引還好,沒有索引是要遍歷數據庫的,有些數據經由條件篩選在邏輯上應該是唯一的,使用limit 1可以使數據庫查詢到該數據時不再搜索,減少數據庫搜索次數,但這種方法僅是一種技巧,想大幅度優化sql還要另想辦法。
//標題是唯一索引,'新標題'存在則更新操作不執行 update ignore arc set title = '新標題' //標題是唯一索引,'標題1號'存在則插入操作不執行 insert ignore into arc values(null,'標題1號','文章內容')
有這種需求,數據存在時不執行任何操作,不存在則更新或插入,一個辦法是使用ingore,它會忽略數據庫報錯,而數據庫執行原子操作時報錯是會回滾的,因此只要我們給數據加上主鍵或唯一索引,當被更新字段或插入字段與原有數據沖突時會報錯,但因為ingore會忽視這種報錯,后端也就不會報錯,sql也未執行,達到了目的,有人會對報錯敏感,其實也沒什么,報錯也是在檢查數據是發現不合理之處給的一個提醒或警告,對數據庫無害的。
區別于上面那個需求,這個是當插入的數據存在時更新數據,不再是不做任何操作,例子:
//本例子中title不是唯一索引,id是主鍵 insert into arc values(1,'標題1號','文章內容') on duplicate key update title='標題1號' //若要更新多個字段使用','隔開,例:title='標題1號',content='文章內容'
在例子中,當id為1的數據存在時,更新標題和內容,不存在則插入,如果執行更新操作,未設置新值的字段保持原來的值。
還有一個REPLACE INTO也可以達到這種效果,區別在于,REPLACE INTO更新時是先刪除后插入會破壞原有索引,id為3的數據更新時會刪除插入id為4的數據,未更新新值的字段設置為默認值或null。
無論是兩個中的哪種方式判斷數據是否存在的依據都是主鍵和唯一索引。
感謝各位的閱讀,以上就是“Mysql中on,in,as,where的區別是什么”的內容了,經過本文的學習后,相信大家對Mysql中on,in,as,where的區別是什么這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





