溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Python Vaex如何實現快速分析100G大數據量的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇Python Vaex如何實現快速分析100G大數據量文章都會有所收獲,下面我們一起來看看吧。
現在的數據科學比賽提供的數據量越來越大,動不動幾十個G,甚至上百G,這就要考驗機器性能和數據處理能力。
Python中的pandas是大家常用的數據處理工具,能應付較大數據集(千萬行級別),但當數據量達到十億百億行級別,pandas處理起來就有點力不從心了,可以說非常的慢。
這里面會有電腦內存等性能的因素,但pandas本身的數據處理機制(依賴內存)也限制了它處理大數據的能力。
當然pandas可以通過chunk分批讀取數據,但是這樣的劣勢在于數據處理較復雜,而且每一步分析都會消耗內存和時間。
下面用pandas讀取3.7個G的數據集(hdf5格式),該數據集共有4列、1億行,并且計算第一行的平均值。我的電腦CPU是i7-8550U,內存8G,看看這個加載和計算過程需要花費多少時間。
數據集:
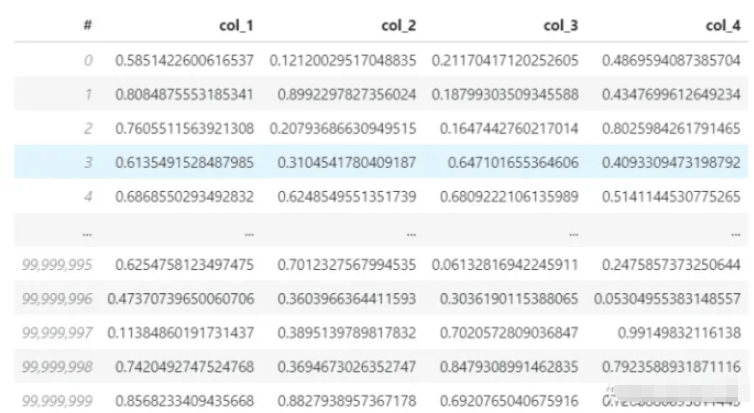
使用pandas讀取并計算:
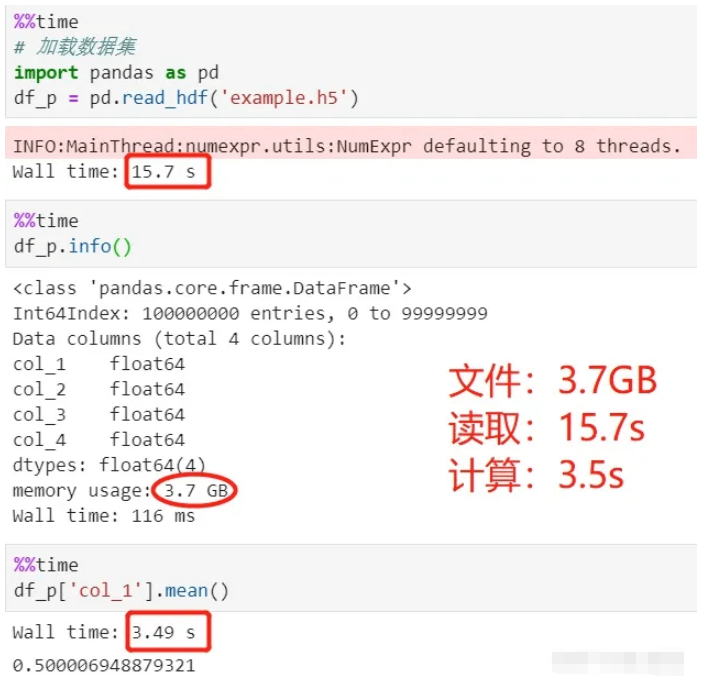
看上面的過程,加載數據用了15秒,平均值計算用了3.5秒,總共18.5秒。
這里用的是hdf5文件,hdf5是一種文件存儲格式,相比較csv更適合存儲大數據量,壓縮程度高,而且讀取、寫入也更快。
換上今天的主角vaex,讀取同樣的數據,做同樣的平均值計算,需要多少時間呢?
使用vaex讀取并計算:
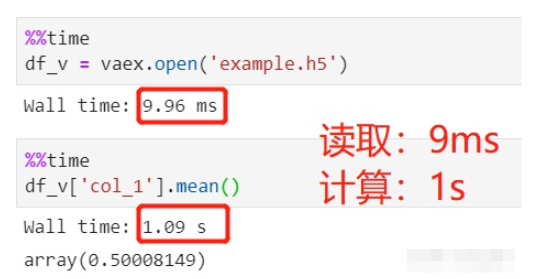
文件讀取用了9ms,可以忽略不計,平均值計算用了1s,總共1s。
同樣是讀取1億行的hdfs數據集,為什么pandas需要十幾秒,而vaex耗費時間接近于0呢?
這里主要是因為pandas把數據讀取到了內存中,然后用于處理和計算。而vaex只會對數據進行內存映射,而不是真的讀取數據到內存中,這個和spark的懶加載是一樣的,在使用的時候 才會去加載,聲明的時候不加載。
所以說不管加載多大的數據,10GB、100GB...對vaex來說都是瞬間搞定。美中不足的是,vaex的懶加載只支持HDF5, Apache Arrow,Parquet, FITS等文件,不支持csv等文本文件,因為文本文件沒辦法進行內存映射。
可能有的小伙伴不太理解內存映射,下面放一段解釋,具體要弄清楚還得自行摸索:
內存映射是指硬盤上文件的位置與進程邏輯地址空間中一塊大小相同的區域之間的一一對應。這種對應關系純屬是邏輯上的概念,物理上是不存在的,原因是進程的邏輯地址空間本身就是不存在的。在內存映射的過程中,并沒有實際的數據拷貝,文件沒有被載入內存,只是邏輯上被放入了內存,具體到代碼,就是建立并初始化了相關的數據結構(struct address_space)。
前面對比了vaex和pandas處理大數據的速度,vaex優勢明顯。雖然能力出眾,不比pandas家喻戶曉,vaex還是個剛出圈的新人。
vaex同樣是基于python的數據處理第三方庫,使用pip就可以安裝。
官網對vaex的介紹可以總結為三點:
vaex是一個用處理、展示數據的數據表工具,類似pandas;
vaex采取內存映射、惰性計算,不占用內存,適合處理大數據;
vaex可以在百億級數據集上進行秒級的統計分析和可視化展示;
vaex的優勢在于:
性能:處理海量數據,109 行/秒;
惰性:快速計算,不占用內存;
零內存復制:在進行過濾/轉換/計算時,不復制內存,在需要時進行流式傳輸;
可視化:內含可視化組件;
API:類似pandas,擁有豐富的數據處理和計算函數;
可交互:配合Jupyter notebook使用,靈活的交互可視化;
使用pip或者conda進行安裝:

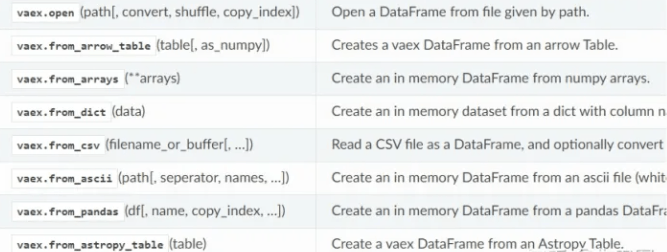
vaex支持讀取hdf5、csv、parquet等文件,使用read方法。hdf5可以惰性讀取,而csv只能讀到內存中。
vaex數據讀取函數:
有時候我們需要對數據進行各種各樣的轉換、篩選、計算等,pandas的每一步處理都會消耗內存,而且時間成本高。除非說使用鏈式處理,但那樣過程就很不清晰。
vaex則全過程都是零內存。因為它的處理過程僅僅產生expression(表達式),表達式是邏輯表示,不會執行,只有到了最后的生成結果階段才會執行。而且整個過程數據是流式傳輸,不會產生內存積壓。
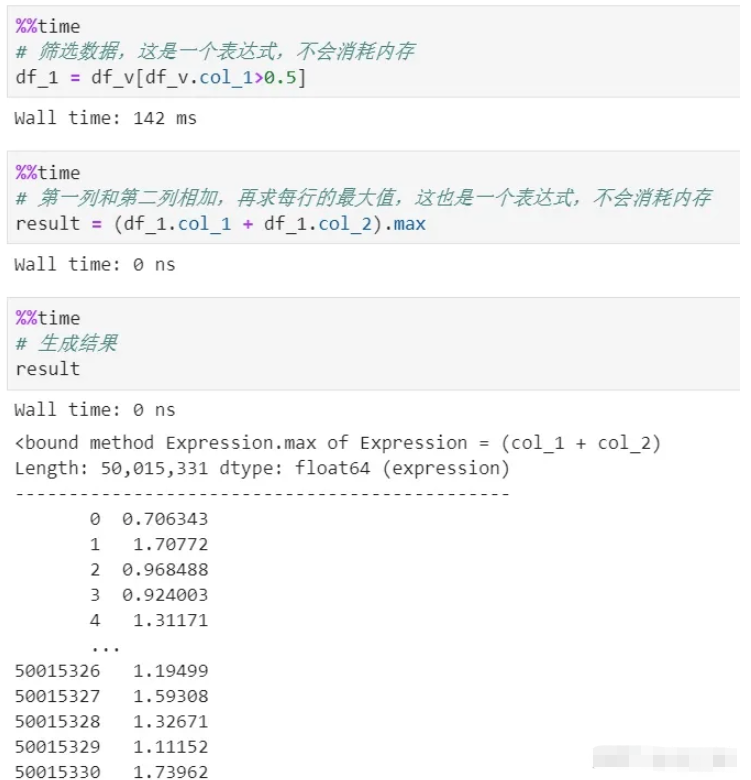
可以看到上面有篩選和計算兩個過程,都沒有復制內存,這里采用了延遲計算,也就是惰性機制。如果每個過程都真實計算,消耗內存不說,單是時間成本就很大。
vaex的統計計算函數:
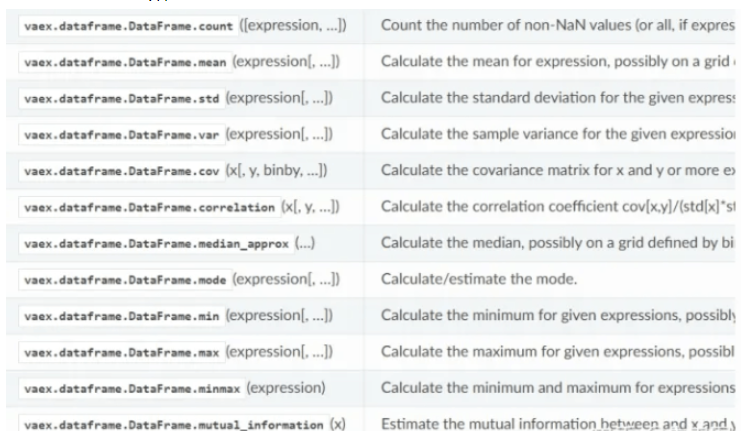
vaex還可以進行快速可視化展示,即便是上百億的數據集,依然能秒出圖。

vaex可視化函數:

vaex有點類似spark和pandas的結合體,數據量越大越能體現它的優勢。只要你的硬盤能裝下多大數據,它就能快速分析這些數據。
vaex還在快速發展中,集成了越來越多pandas的功能,它在github上的star數是5k,成長潛力巨大。
附:hdf5數據集生成代碼(4列1億行數據)
import pandas as pd
import vaex
df = pd.DataFrame(np.random.rand(100000000,4),columns=['col_1','col_2','col_3','col_4'])
df.to_csv('example.csv',index=False)
vaex.read('example.csv',convert='example1.hdf5')注意這里不要用pandas直接生成hdf5,其格式會與vaex不兼容。
關于“Python Vaex如何實現快速分析100G大數據量”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“Python Vaex如何實現快速分析100G大數據量”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





