溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“怎么使用Pandas實現MySQL日期函數”,內容詳細,步驟清晰,細節處理妥當,希望這篇“怎么使用Pandas實現MySQL日期函數”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
環境:
windows11 64位
Python3.9
MySQL8
pandas1.4.2
使用 Python 構建該數據集的語法如下:
import pandas as pd
import numpy as np
df1 = pd.DataFrame({ 'col1' : list(range(1,7))
,'col2' : ['AA','AA','AA','BB','AA','BB']#list('AABCA')
,'col3' : ['2022-01-01','2022-01-01','2022-01-02','2022-01-02','2022-01-03','2022-01-03']
,'col4' : ['2022-02-01','2022-01-21','2022-01-23','2022-01-12','2022-02-03','2022-01-05']
,'col5' : [1643673600,1642723200,1642896000,1641945600,1643846400,1641340800]
})
df1['col3'] = pd.to_datetime(df1.col3)
df1['col4'] = pd.to_datetime(df1.col4)
df1注:直接將代碼放 jupyter 的 cell 跑即可。后文都直接使用
df1調用對應的數據。
使用 MySQL 構建該數據集的語法如下:
with t1 as( select 1 as col1, 'AA' as col2, '2022-01-01' as col3, '2022-02-01' as col4, 1643673600 as col5 union all select 2 as col1, 'AA' as col2, '2022-01-01' as col3, '2022-01-21' as col4, 1642723200 as col5 union all select 3 as col1, 'AA' as col2, '2022-01-02' as col3, '2022-01-23' as col4, 1642896000 as col5 union all select 4 as col1, 'BB' as col2, '2022-01-02' as col3, '2022-01-12' as col4, 1641945600 as col5 union all select 5 as col1, 'AA' as col2, '2022-01-03' as col3, '2022-02-03' as col4, 1643846400 as col5 union all select 6 as col1, 'BB' as col2, '2022-01-03' as col3, '2022-01-05' as col4, 1641340800 as col5 ) select * from t1;
注:直接將代碼放 MySQL 代碼運行框跑即可。后文跑 SQL 代碼時,默認帶上數據集(代碼的1~8行),僅展示查詢語句,如第9行。
對應關系如下:
| Python 數據集 | MySQL 數據集 |
|---|---|
| df1 | t1 |
date_add()/date_sub()
時間的加減,在 MySQL 中,使用的是date_add()/date_sub()來實現,二者可以替換使用,只要對相加/減的時間加上負號即可(詳見后面例子)。
而在 Pandas 中,可以通過Timedelta()或DateOffset()實現,二者有差異,如果是針對月份和年度計算差值,只能使用后者;如果是計算日、時、分、秒,則二者通用。
時間范圍對應的語法參數見下表:
| 時間范圍 | date_add()/date_sub() | pandas.Timedelta() | pandas.DateOffset() |
|---|---|---|---|
| 年 | year | - | years |
| 月 | month | - | months |
| 日 | day | days | days |
| 時 | hour | hours | hours |
| 分 | minute | minutes | minutes |
| 秒 | second | seconds | seconds |
1、增加1天
MySQL 增加 1 天,可以使用date_add()+1 day或者用date_sub()-1 day。
Pandas 中,可以使用 DateFrame 時間列直接加上pd.Timedelta(days=1)或者pd.DateOffset(days=1)。
| 語言 | Python | MySQL |
|---|---|---|
| 代碼 | 【Python1】 df1.col3 + pd.Timedelta(days=1) 【Python2】 df1.col3 + pd.DateOffset(days=1) | 【MySQL1】 select date_add(t1.col3,interval 1 day) as col3_1 from t1; 【MySQL2】 select date_sub(t1.col3,interval -1 day) as col3_1 from t1; |
| 結果 | 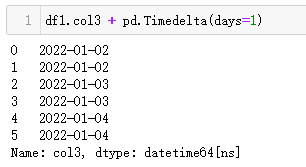 | 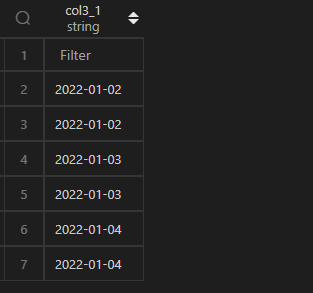 |
2、減掉1天
| 語言 | Python | MySQL |
|---|---|---|
| 代碼 | 【Python1】 df1.col3 + pd.Timedelta(days=-1) 【Python2】 df1.col3 + pd.DateOffset(days=-1) | 【MySQL1】 select date_add(t1.col3,interval -1 day) as col3_1 from t1; 【MySQL2】 select date_sub(t1.col3,interval 1 day) as col3_1 from t1; |
| 結果 | 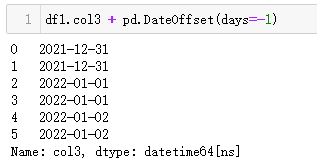 | 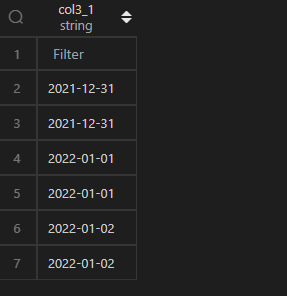 |
計算時間的差值,在 MySQL 中,使用datediff(<被減數>,<減數>)(即<被減數>-<減數>)實現;而在 Pandas 中,操作相對簡單,兩個 Series 相減即可。但是相減之后的數據類型是timedelta64[ns],如果要用于比較大小,或需要轉化為整數,將timedelta64[ns]的數值提取出來,提取數值可以使用其屬性days并借助apply()實現,具體代碼邏輯見以下例子。
| 語言 | Python | MySQL |
|---|---|---|
| 代碼 | (df1.col4-df1.col3).apply(lambda x:x.days) | select datediff(col4,col3) as diff from t1; |
| 結果 | 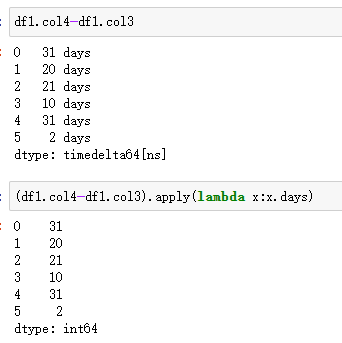 | 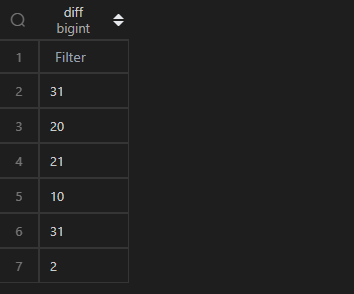 |
格式設置,在 MySQL 中,使用date_format(),在 Python 中,使用strftime(),二者都是將時間類型轉化為字符串類型。標識符有一點差異,前者的分使用%i,秒使用%s,而后者分使用%M,秒使用%S。
具體格式參考下表:
| 時間范圍(示例) | date_format() | strftime() |
|---|---|---|
| 年,0000~9999 | %Y | %Y |
| 月,01~12 | %m | %m |
| 日,01~31 | %d | %d |
| 時,00~24 | %H | %H |
| 分,00~59 | %i | %M |
| 秒,00~59 | %s | %S |
格式化為:年份-月份
MySQL 直接使用date_format(列,"<格式符號>")函數套用即可;而 Python 中,由于strftime('<格式符號>')是作用于時間類型,而df1.col3是 Series 類型,所以需要使用apply()來輔助處理每一個值(如下 Python 代碼)。
| 語言 | Python | MySQL |
|---|---|---|
| 代碼 | df1.col3.apply(lambda x:x.strftime(‘%Y-%m’)) | select date_format(t1.col3,‘%Y-%m’) as col3_1 from t1; |
| 結果 | 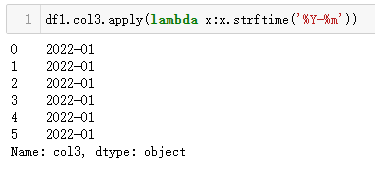 | 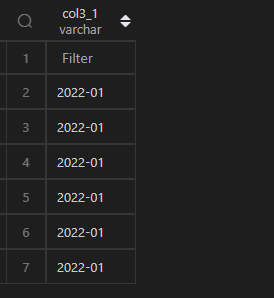 |
取時間的某一部分(如:年、月、日、時、分、秒),在 MySQL 中,直接使用對應的函數作用于字段即可。
在 Python 中,時間類型的值也有對應的屬性可以獲取到對應的值,同樣地,由于df1.col3是 Series 類型,所以需要使用apply()來輔助處理每一個值(如下 Python 代碼)。
| 語言 | Python | MySQL |
|---|---|---|
| 代碼 | df_timepart = pd.concat([ df1.col4.apply(lambda x:x.year) ,df1.col4.apply(lambda x:x.month) ,df1.col4.apply(lambda x:x.day) ,df1.col4.apply(lambda x:x.hour) ,df1.col4.apply(lambda x:x.minute) ,df1.col4.apply(lambda x:x.second) ],axis=1 ) df_timepart.columns=[‘year’,‘month’,‘day’,‘hour’,‘minute’,‘second’] df_timepart | select year(col4),month(col4),day(col4),hour(col4),minute(col4),second(col4) from t1; |
| 結果 | 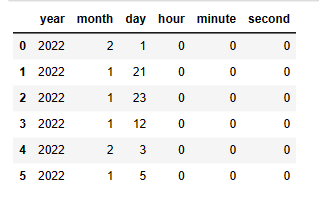 | 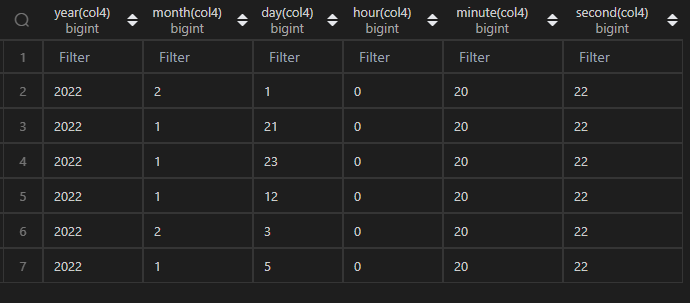 |
使用時間戳時,需要特別注意:pandas 采用的是 零時區的時間,MySQL 會默認當地時間,北京時間采用的是東八區,所以北京的時間會比零時區早8小時,也就是說,同一個時間戳,北京時間會比零時區時間多8小時,如:1577836800,轉化為北京時間是【2020-01-01 08:00:00】,轉化為零時區時間為【2020-01-01 00:00:00】。
1、時間戳轉時間
時間戳轉時間,在 MySQL 中,通過from_unixtime()函數直接作用于列即可,還可以指定時間格式,格式化字符參考date_format()中的表格。
在 Pandas 中,通過to_datetime()實現,注意需要指定unit,它根據時間戳的精度設置,常見參數有:【D,s,ms】,分別對應日數、秒數、毫秒數(相對1970-01-01 00:00:00的間隔數)。
注意:如果需要轉化為東八區,只能通過手動添加 8 小時。
| 語言 | Python | MySQL |
|---|---|---|
| 代碼 | 【Python 1 默認時區】 pd.to_datetime(df1.col5, unit=‘s’) 【Python 2 東八時區】 pd.to_datetime(df1.col5, unit=‘s’)+pd.Timedelta(hours=8) | select from_unixtime(col5) from t1; |
| 結果 | 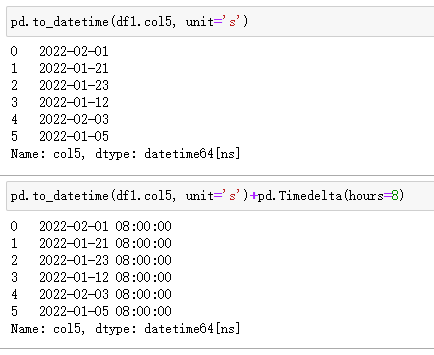 | 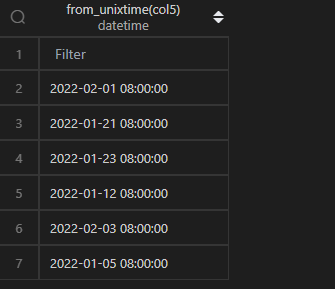 |
2、時間轉時間戳
時間轉時間戳,在 MySQL 中,通過unix_timestamp()函數直接作用于列即可。
在 Pandas 中,通過apply()+timestamp()實現,如果需要轉化為東八區,先對時間做一層tz_localize("Asia/Shanghai")處理,然后再轉化即可,返回的是浮點數。
注意:這里有一個小細節,由于返回的值默認是科學計數方式,而我需要查看完整數字串,而且沒有小數值,我加了int()處理。如果使用的時間精確到毫秒,即存在小數,加int()處理會丟失精度,應用時需要結合自己的實際情況和需求做處理。
| 語言 | Python | MySQL |
|---|---|---|
| 代碼 | 【Python 1 默認時區】 df1.col4.apply(lambda x:int(x.timestamp())) 【Python 2 東八時區】 df1.col4.apply(lambda x:int(x.tz_localize(“Asia/Shanghai”).timestamp())) | select unix_timestamp(col4) from t1; |
| 結果 | 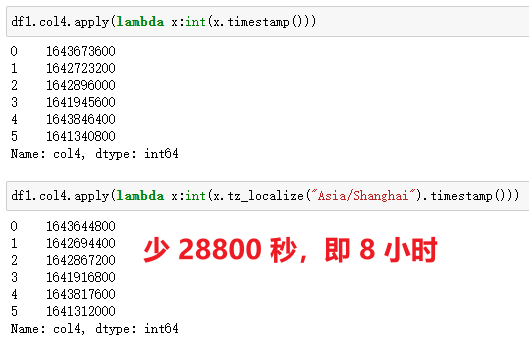 | 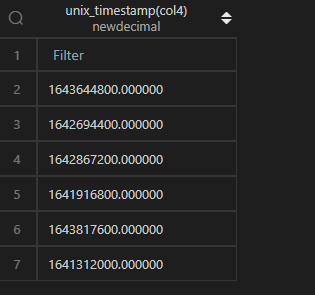 |
讀到這里,這篇“怎么使用Pandas實現MySQL日期函數”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





