溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“python HZK16字庫如何使用”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
偶然在網上看到熱心網友使用python講微信頭像進行了組字,感覺很有意思,就做下研究。
感謝,原文參考自: Python玩微信頭像組字
需求的相關工具:
python第三方庫image
pip install image # 圖像處理
HZK16字庫的下載
自行百度下載吧,由于網盤鏈接失效暫不給大家分享了。
本應該要安裝python的第三方庫itchat的
pip install itchat # 開源的微信個人接口 # 騰訊在2019年7月份關閉了網頁版登錄接口 # itchat的相關接口已經不能夠正常使用了,原有使用的主要接口有: # 自動登錄微信網頁,會生成一個二維碼圖片,手機掃碼即可登入 itchat.auto_login() # 獲取微信好友信息列表,從而獲取頭像信息 friendList = itchat.get_friends(update=True)
通過itchat獲取微信好友頭像圖片,將設定的文字按照HZK16字庫轉換為矩陣信息,然后在每個矩陣點上放置2X2張圖片,最后通過Image生成出來。
雖然itchat不可使用了,但是我們可以使用本地的圖片進行模擬效果.
它是符合GB2312國家標準的16×16點陣字庫,每個漢字需要**256(16×16)**個點組成。
其GB2312-80支持的漢字有6763個,符號682個;其中一級漢字有 3755個,按聲序排列,二級漢字有3008個,按偏旁部首排列。
通常情況下中文漢字,在UTF-8格式下占用字節為2個;在GBK,GB2312格式下占用字節3個。因此GB2312的HZK16下的中文漢字占用2個字節。其編碼范圍:0xA1A1~0xFEFE,A1-A9為符號區,B0-F7為漢字區。
前面說到GB2312格式下漢字占2個字節,前一個字節為該漢字的區號,每個區中記錄94個漢字;后一個字節為該字的位號。用于記錄漢字在該區中的位置。
因此要找到一個漢字在HZK16字庫中的位置就必須得到它的區碼和位碼。
區碼:漢字的第一個字節 - 0xA0,因為漢字編碼是從0xA0區開始的,所以文件最前面就是從0xA0區開始,要算出相對區碼
位碼:漢字的第二個字節 - 0xA0
通過區碼和位碼我們就可以得到漢字在HZK16中的絕對偏移位置:
''' * 區碼或者位碼減1,是由于數組從0開始,而區號位號是以1開始 * (94*(區號-1)+位號-1)是一個漢字字模占用的字節數 * 乘以32是因為一個漢字由32個字節存儲(16*16/8) ''' offset = (94*(區碼-1)+(位碼-1))*32
下載HZK16文件后,放置到指定的目錄中,其目錄結構為:
res中放置著一張75X75的png圖片,可放置多個。代碼為:
# -*- coding:UTF-8 -*-
#!/usr/bin/env python
import os
import math
import binascii
from PIL import Image
# 用于解決錯誤:UnicodeEncodeError: 'ascii' codec encode characters in position...
# 原因在于調用ascii編碼處理字符流時,若字符流不屬于ascii范圍內就會報錯
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
# 每張頭像裁剪后尺寸,建議圖片不要太大,最好寬高一致
HEAD_CLIPSIZE = 75
# 每行列頭像數目,即每點:2*2,可修改為3,即3*3
HEAD_NUM = 2
RECT_WIDTH = 16 # 矩陣點寬度 16
RECT_HEIGHT = 16 # 矩陣點高度 16
BYTE_COUNT_PER_FONT = 2*RECT_HEIGHT # 占用字節 32
# 將文字轉換為點陣
def char2bit(textStr):
KEYS = [0x80, 0x40, 0x20, 0x10, 0x08, 0x04, 0x02, 0x01]
target = []
global count
count = 0
# 遍歷文字
for x in range(len(textStr)):
text = textStr[x]
# 初始化16*16點陣位置
rect_list = [] * RECT_WIDTH
for i in range(RECT_HEIGHT):
rect_list.append([] * RECT_WIDTH)
# 獲取GB2312編碼字符
gb2312 = text.encode('gb2312')
hex_str = binascii.b2a_hex(gb2312)
result = str(hex_str)
# 獲取漢字第一個字節,區碼
area = eval('0x' + result[:2]) - 0xA0
# 獲取漢字第二個字節,位碼
index = eval('0x' + result[2:]) - 0xA0
# 獲取漢字在字庫中的絕對偏移值
offset = (94 * (area-1) + (index-1)) * BYTE_COUNT_PER_FONT
font_rect = None
# 讀取HZK16字庫文件
with open("HZK16", "rb") as f:
# 獲取目標漢字偏移位置
f.seek(offset)
# 從數據中讀取32字節數據
font_rect = f.read(BYTE_COUNT_PER_FONT)
for k in range(len(font_rect)/2):
row_list = rect_list[k]
for j in range(2):
for i in range(8):
asc = binascii.b2a_hex(font_rect[k * 2 + j])
asc = asc = eval('0x' + asc)
flag = asc & KEYS[i]
row_list.append(flag)
output = []
_str = ''
for row in rect_list:
for i in row:
if i:
output.append('1')
_str += '0'
count+=1
else:
output.append('0')
_str += '.'
print(_str)
_str = ''
target.append(''.join(output))
return target
def head2char(index, outlist):
# 獲取資源列表
imgList = []
workspace = os.getcwd()
respath = os.path.join(workspace, 'res')
for root, dirs, files in os.walk(respath):
for filename in files:
imgList.append(os.path.join(root, filename))
# 圖片數目
imgCount = len(imgList)
#變量n用于循環遍歷頭像圖片,即當所需圖片大于頭像總數時,循環使用頭像圖片
n = 0
for item in outlist:
# 創建新圖片
canvasWidth = RECT_WIDTH * HEAD_NUM * HEAD_CLIPSIZE
canvasHeight = RECT_HEIGHT * HEAD_NUM * HEAD_CLIPSIZE
canvas = Image.new('RGB', (canvasWidth, canvasHeight), '#E0EEE0')
# 遍歷 RECT_WIDTH * RECT_HEIGHT 矩陣
for i in range(RECT_WIDTH * RECT_HEIGHT):
#點陣信息為1,即代表此處要顯示頭像來組字
if item[i] != '1':
continue
# 每個點使用放置幾個矩陣,比如2*2,3*3
for count in range(pow(HEAD_NUM, 2)):
# 獲取圖片索引
imgIndex = (n + count) % imgCount
# 讀取圖片
headImg = Image.open(imgList[imgIndex])
# 重置圖片大小
headImg = headImg.resize((HEAD_CLIPSIZE, HEAD_CLIPSIZE), Image.ANTIALIAS)
# 拼接圖片
posx = ((i % RECT_WIDTH) * HEAD_NUM + (count%HEAD_NUM)) * HEAD_CLIPSIZE
posy = ((i // RECT_HEIGHT) * HEAD_NUM + (count//HEAD_NUM)) * HEAD_CLIPSIZE
canvas.paste(headImg, (posx, posy))
#調整n以讀取后續圖片
n = (n+4) % imgCount
# 保存圖片 quality代表圖片質量,1-100
canvas.save('result_{0}.jpg'.format(index), quality=100)
# 將gbk轉換為unicode格式
def transGbk2Unicode(str_v):
str_s = str_v.replace(r'%', r'\x')
res = eval(repr(str_s).replace('\\\\', '\\'))
return res.decode('gb2312')
if __name__=="__main__":
inputStr = u'請輸入您想要生成的文字(ENTER結束):'
# 輸入內容,將中文從unicode轉換為gbk,防止亂碼
content = raw_input(inputStr.encode('gbk'))
# 將gbk轉換為unicode,以方便遍歷時能夠遍歷每個文字或字母
content = transGbk2Unicode(content)
print(u'注意:指定文字每個僅能生成一個')
# 循環遍歷
index = 0
for _str in content:
print(u'生成漢字:' + _str)
#將字轉化為漢字庫的點陣數據
outlist = char2bit(_str)
#將頭像圖片按點陣拼接成單字圖片
head2char(index, outlist)
index += 1
print(u'生成成功!!!')執行結果:
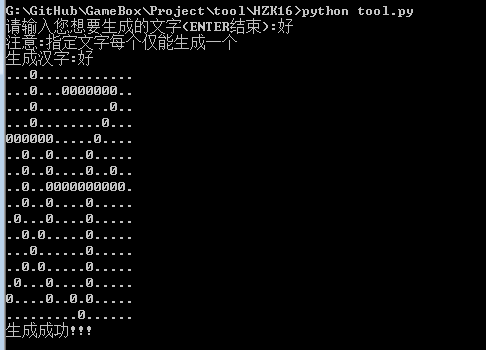
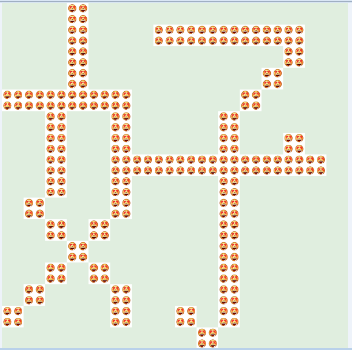
“python HZK16字庫如何使用”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





