溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Node如何排查內存泄漏”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Node如何排查內存泄漏”吧!
在 Nodejs 服務端開發的場景中,內存泄漏 絕對是最令人頭疼的問題;
但是只要項目一直在開發迭代,那么出現 內存泄漏 的問題絕對不可避免,只是出現的時間早晚而已。所以系統性掌握有效的 內存泄漏 排查方法是一名Nodejs 工程師最基礎、最核心的能力。
2022 Q4 某天,研發用戶群中反饋我們的研發平臺不能訪問,后臺中出現了大量的異常任務未完成。
第一反應就是可能出現了內存泄漏還好服務接入了監控(prometheus + grafana),在grafana 監控面板中發現在 10.00 后內存一直在漲沒有下來過出現了明顯的數據泄漏。
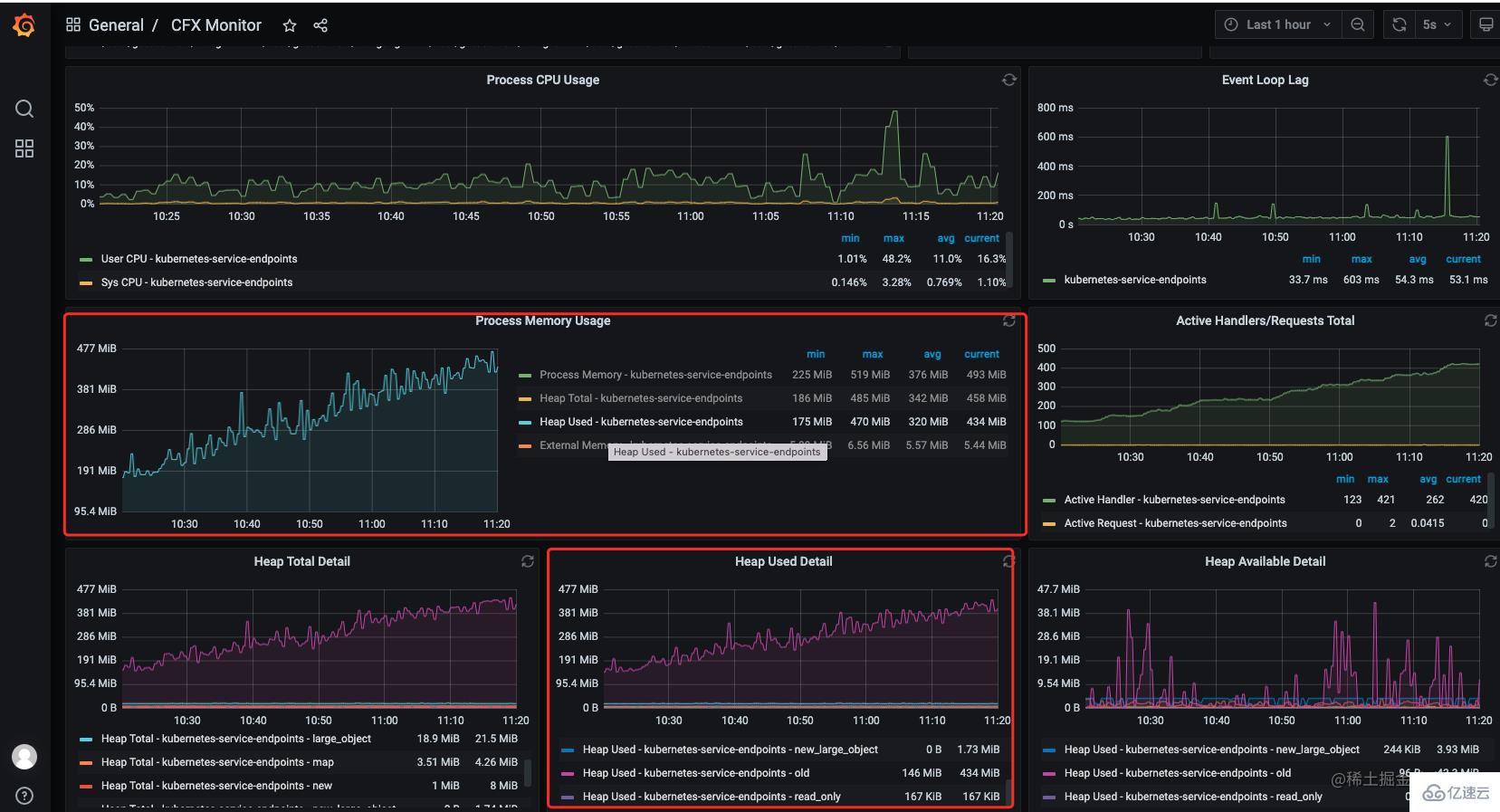
說明:
process memory:rss(Resident Set Size),進程的常駐內存大小。
heapTotal: V8 堆的總大小。
heapUsed: V8 堆已使用的大小。
external: V8 堆外的內存使用量。在
Nodejs中可以調用全局方法process.memoryUsage()獲取這些數據其中heapTotal和heapUsed是 V8 堆的使用情況,V8 堆是Node.js中 JavaScript 對象存儲的地方。而external則表示非 V8 堆中分配的內存,例如 C++ 對象。rss則是進程所有內存的使用量。一般看監控數據的時候重點關注heapUsed的指標就行了
內存泄漏主要分為:
全局性泄漏
局部性泄漏
其實不管是全局性內存泄漏還是局部性的內存泄漏,要做的都是盡可能縮小排除范圍。
全局性內容泄漏出現一般高發于:中間件與組件中,這種類型的內存泄漏排查起來也是最簡單的。
很遺憾我在 2022 Q4 中遇到的內存泄漏不屬于這個類型,所以還得按照局部性泄漏的思路進行分析。
這種類型我就不講其它科學的分析方法了,這種情況下我認為使用二分法排查是最快的。
流程流程:
先注釋一半的代碼(減少一半中間件、組件、或其它公用邏輯的使用)
隨便選擇一個接口或新寫一個測試接口進行壓測
如果出現內存泄漏,那么泄漏點就在當前使用的代碼之中,若沒有泄漏則泄漏點出現在
然后一直循環往復上述流程大約 20 ~ 60 min 一定可以定位到內存泄漏的詳細位置
2020 年的時候我在做基于
NuxtSSR 應用時,上線前壓測發現應用內存泄漏,判斷定為全局性的泄漏之后,采用二分法排查大約花了 30min 就成功定位了問題。
當時泄漏的原因是我們在服務端使用axios導致的泄漏,后來統一axios相關的全換成node-fetch后就解決了,從此換上了axios PDST后來絕對不會在Node服務中使用axios了
大多數內存泄漏的情況都是局部性的泄漏,泄漏點可能存在與某個中間件、某個接口、某個異步任務中,由于這樣的特性它的排查難度也較大。這種情況都會做 heapdump 進行分析。
這里主要講我這個案例中的思路關于heapdump的詳細說明我放在下個段落,
Heap Dump:堆轉儲, 后面部分都使用heapdump表示,做heapdump的工具和教程也非常多比如:chrome、vscode、heapdump 這個開源庫。我用的 heapdump 庫做的網上教程非常多這里不展開了。
局部性內存泄漏排查需要一定的內存泄漏排查經驗,每次遇到都把它當成對自己的一次磨礪,這樣的經驗積累多了以后排查內存泄漏問題會越來越快。
這一點非常重要,明確了這一點可以大幅度縮小排查范圍。
經常會出現這種情況,這個迭代做了A、B、C 三個功能,壓測時或上線后出現了內存泄漏。那么就可以直接鎖定,內存泄漏發生小這三個新的功能之中。這種情況下就不需要非常麻煩的去生產做 heapdump 我們在本地通過一些工具就可以很輕松的分析定位出內存泄漏點。
由于我們 20年Q4 的一些特殊情況,當我們發現存在內存泄漏的時候已經很難確定內存泄漏初次出現在什么時間點了,只能大概鎖定在 1 月的時間內。這一個月中我們又經歷了一個大版本迭代,如果一一排查這些功能與接口成本必然非常高。
所以還需要結合更多的數據進行進一步分析
生產啟動時 node 添加 --expose-gc,這個參數會向全局注入 gc() 方法,方便手動觸發 GC 獲取更準確的堆快照數據
這里我加入了兩個接口并帶上了自己的專屬權限,
手動觸發 GC
打印堆快照
heapdump
項目啟動后第一次打印快照數據
內存上漲 100M 后:先觸發 GC,再第二次打印堆快照數據
內存接近臨界時再次觸發 GC 然后打印堆快照
采集堆快照數據時需要特別注意的一些點!
在
heapdump時 Node 服務會中斷,根據當時服務器內存大小這個時間會在 2 ~ 30min 左右。在生產環境做heapdump需要和運維一起制定合理的策略。我在這里是使用了主、備兩個pod, 當主pod停掉之后,業務請求會通過負載均衡到備用pod由此保障生產業務的正常進行。(這個過程必定是一個與運維密切配合的過程,畢竟heapdump玩抽還需要通過他們拿到服務器中堆快照文件)上述接近臨界點打印快照只是一個模糊的描述,如果你試過就知道等非常接近臨界點再打印內存快照就打印不出來了。所以接近這個度需要自己把握。
做至少 3 次
heapdump(實際上為了拿到最詳細的數據我是做了 5 次)
需要你的應用服務接入監控,我這里應用是使用prometheus + grafana 做的監控, 主要監控服務的以下指標
QPS (每秒請求訪問量) ,請求狀態,及其訪問路徑
ART (平均接口響應時間) 及其訪問數據
NodeJs 版本
Actice Handlers(句柄)
Event Loop Lag (事件滯后)
服務進程重啟次數
CPU 使用率
內存使用:rss、heapTotal、heapUsed、external、heapAvailableDetail
只有
heapdump數據是不夠的,heapdump數據非常晦澀,就算在可視化工具的加持下也難以準確定位問題。這個時候我是結合了grafana的一些數據一起看。
由于當時的對快照數據丟失了,我這里模擬一下當時的場景。
1、通過 grafana 監控面看看到內存一直在漲一直下不來,但同時我也注意到,服務中的句柄數也在瘋漲一直不掉。

2、這是我回顧了一下出現泄漏的那一個月中新增的功能懷疑可能是在使用 bull 消息隊列組件造成的內存泄漏。先去分析了相關應用代碼,但并看不出那里寫的有問題導致了內存泄漏,
結合 1 中句柄泄漏的問題感覺是在使用 bull 后需要手動的去釋放某些資源,在這個時候還不太確定具體原因。
3、然后對 5 次的 heapdunmp 數據進行了分析,數據導入 chrome 對 5 次堆快照進行對比后,發現每次創建隊列后 TCP、Socket、EventEmitter 的事件都沒有被釋放到。到這里基本可以確定是由于對 bull 的使用不規范導致的。在 bull 通常不會頻繁創建隊列,隊列占用的系統資源并不會被自動釋放,若有需要,需手動釋放。
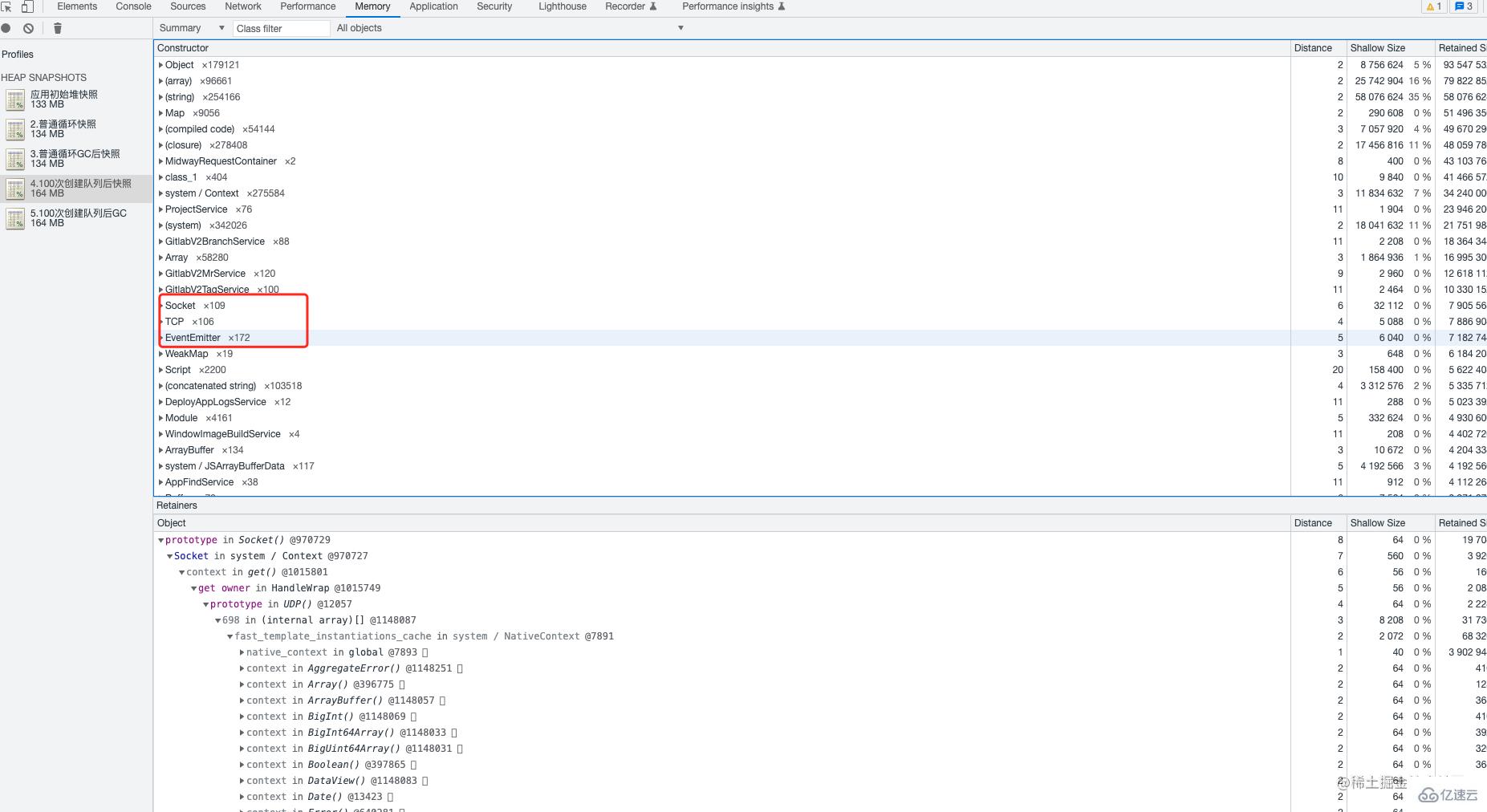
4、在調整完代碼后重新進行了壓測,問題解決。
Tips: Nodejs 中的
句柄是一種指針,指向底層系統資源(如文件、網絡連接等)。句柄允許 Node.js 程序訪問和操作這些資源,而無需直接與底層系統交互。句柄可以是整數或對象,具體取決于 Node.js 庫或模塊使用的句柄類型。常見句柄:
fs.open()返回的文件句柄
net.createServer()返回的網絡服務器句柄
dgram.createSocket()返回的 UDP socket 句柄
child_process.spawn()返回的子進程句柄
crypto.createHash()返回的哈希句柄
zlib.createGzip()返回的壓縮句柄
通常很多人第一次拿到堆快照數據是懵的,我也是。在看了網上無數的分析技巧結合自身實戰后總結了一些比較好用的技巧,一些基礎的使用教程這里就不講了。這里主要講數據導入 chrome 后如何看圖;
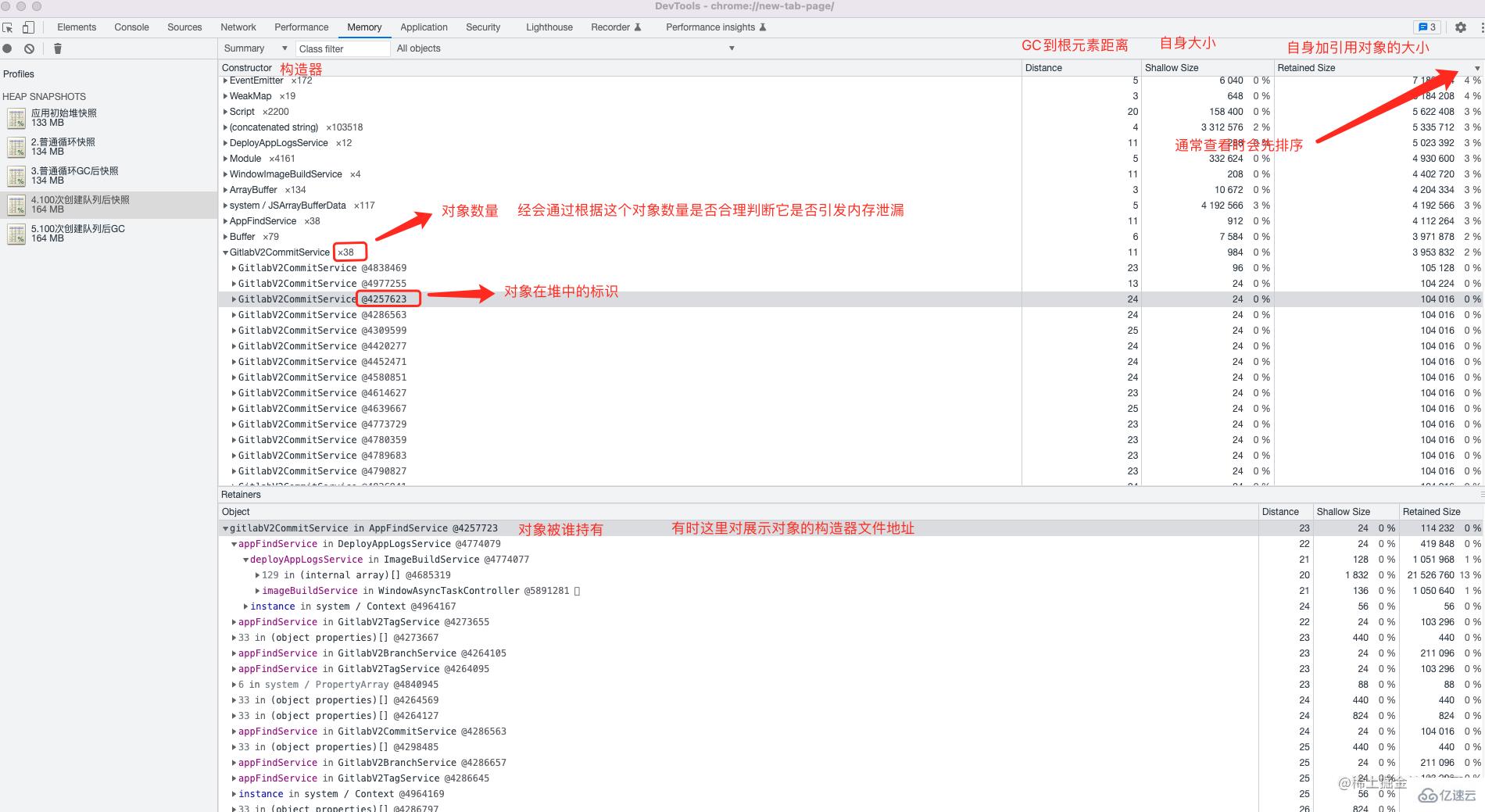 看這個視圖的時候一般會先對 Retained Size 進行排查,然后觀察其中對象的大小與數量,有經驗的工程師,可以快速判斷出某些對象數量異常。在這個視圖中除了關心自己定義的一些對象之外,
一些容易發生內存泄漏的對象也需要注意如:
看這個視圖的時候一般會先對 Retained Size 進行排查,然后觀察其中對象的大小與數量,有經驗的工程師,可以快速判斷出某些對象數量異常。在這個視圖中除了關心自己定義的一些對象之外,
一些容易發生內存泄漏的對象也需要注意如:
TCP
Socket
EventEmitter
global
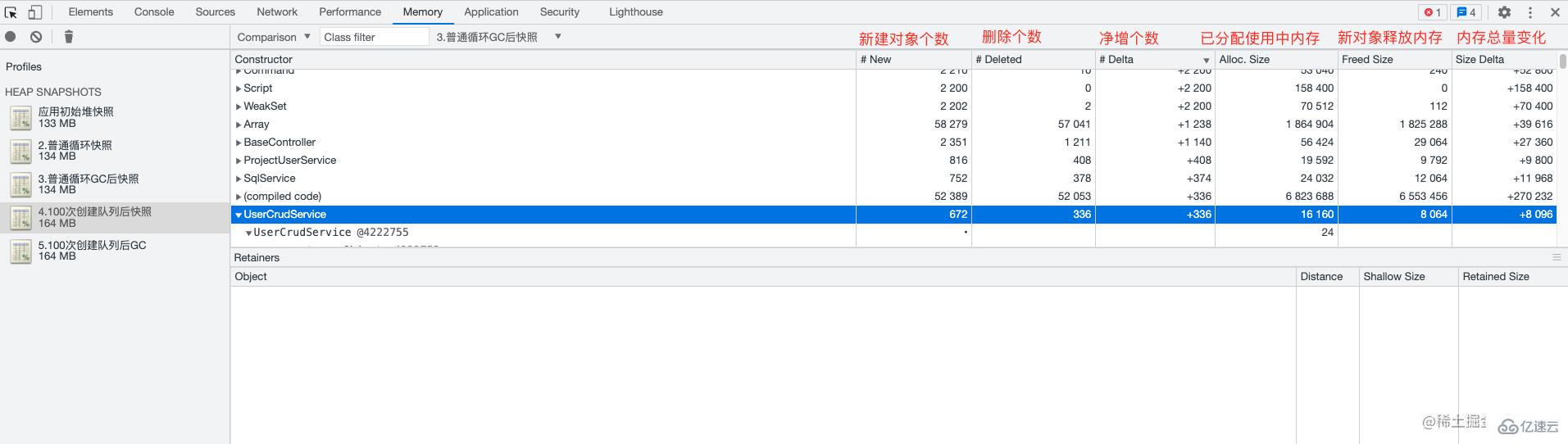
如果通過 Summary 視圖, 不能定位到問題這時我們一般會使用 Comparison 視圖。通過這個視圖我們能對比兩個堆快照中對象個數、與對象占有內存的變化;
通過這些信息我們可以判斷在一段時間(某些操作)之后,堆中的對象與內存變化的數值,通過這些數值我們可以找出一些異常的對象。通過這些對象的名稱屬性或作用可以縮小我們內存泄漏的排查范圍。
在 Comparison 視圖中選擇兩個堆快照,并在它們之間進行比較。您可以查看哪些對象在兩個堆快照之間新增,哪些對象在兩個堆快照之間減少,以及哪些對象的大小發生了變化。Comparison 視圖還允許查看對象之間的關系,以及對象的詳細信息,如類型、大小和引用計數。通過這些信息,可以了解哪些對象是導致內存泄漏的原因。
顯示了對象之間的所有可達的引用關系。每個對象都被表示為一個圓點,并由一條線條連接到它的父對象。通過這種方式可以查看對象之間的層次關系,并了解哪些對象是導致內存泄漏的原因。
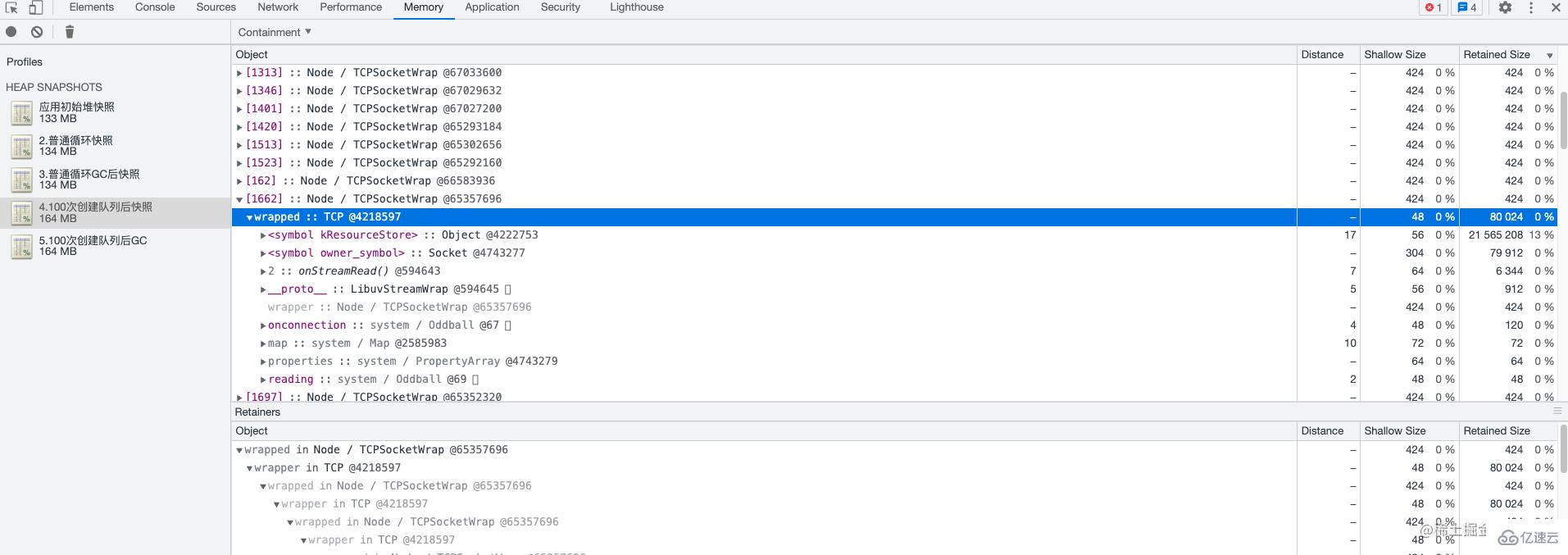
這個圖很簡單不展開講了
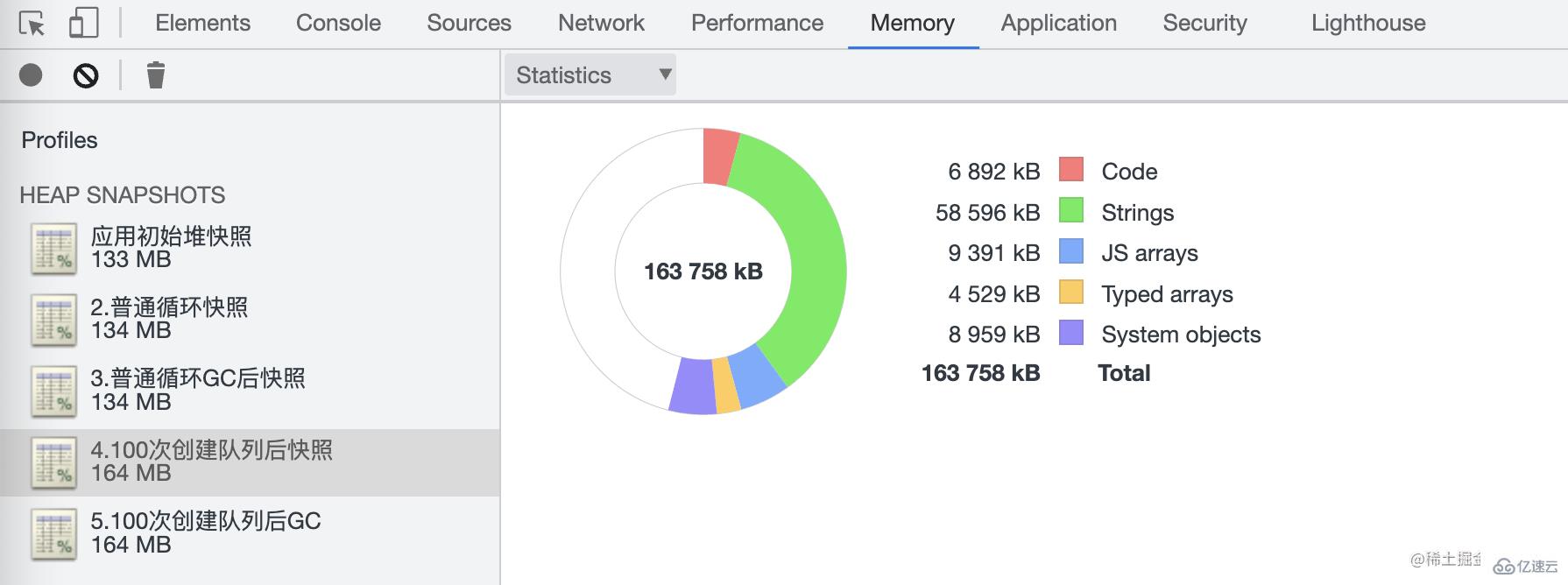
全局變量:全局變量不會被回收
緩存:使用了內存密集型的第三方庫如 lru-cache 存的太多就會導致內存不夠用,在 Nodejs 服務中建議使用 redis 替代 lru-cache
句柄泄漏:調用完系統資源沒有釋放
事件監聽
閉包
循環引用
感謝各位的閱讀,以上就是“Node如何排查內存泄漏”的內容了,經過本文的學習后,相信大家對Node如何排查內存泄漏這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





