溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“linux驅動程序運行空間是什么”,在日常操作中,相信很多人在linux驅動程序運行空間是什么問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”linux驅動程序運行空間是什么”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
linux驅動程序運行在“內核”空間。一般情況下驅動程序中都是調用kmalloc()來給數據結構分配內存,調用vmalloc()為活動的交換區分配數據結構,為某些I/O驅動程序分配緩沖區,或為模塊分配空間;kmalloc和vmalloc分配的是內核的內存。
linux驅動程序運行在“內核”空間。
對于一般編寫的單片機程序來說應用程序和驅動程序往往是雜糅的,擁有一定能力水平的單片機程序編程人員可以實現應用和驅動的分層。而在Linux系統中已經強制將應用和驅動進行了分層。
在單片機程序中,應用可以直接操作底層的寄存器。而在Linux系統中卻禁止這樣的行為,舉個例子:Linux應用的編寫人員故意在應用中調用了驅動中關于電源管理的驅動,關閉了系統,那不就得不償失了?
具體的Linux應用程序對驅動的調用如圖所示:
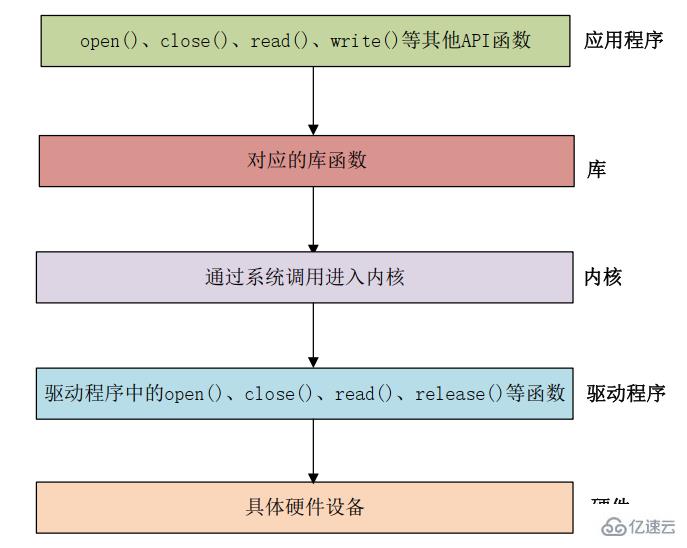
應用程序運行在用戶空間,驅動程序運行在內核空間。處于用戶空間應用程序如果想要實現對內核的操作,必須經過一種"系統調用"的方法,實現從用戶空間進入內核空間,實現對底層的操作。
內核也是程序,也應該具有自己的虛存空間,但是作為一種為用戶程序服務的程序,內核空間有它自己的特點。
內核空間與用戶空間的關系
在一個32位系統中,一個程序的虛擬空間最大可以是4GB,那么最直接的做法就是,把內核也看作是一個程序,使它和其他程序一樣也具有4GB空間。但是這種做法會使系統不斷的切換用戶程序的頁表和內核頁表,以致影響計算機的效率。解決這個問題的最好做法就是把4GB空間分成兩個部分:一部分為用戶空間,另一部分為內核空間,這樣就可以保證內核空間固定不變,而當程序切換時,改變的僅是程序的頁表。這種做法的唯一缺點便是內核空間和用戶空間均變小了。
例如:在i386這種32位的硬件平臺上,Linux在文件page.h中定義了一個常量PAGE_OFFSET:
#ifdef CONFIG_MMU
#define __PAGE_OFFSET (0xC0000000) //0xC0000000為3GB
#else
#define __PAGE_OFFSET (0x00000000)
#endif
#define PAGE_OFFSET ((unsigned long)__PAGE_OFFSET)
Linux以PAGE_OFFSET為界將4GB的虛擬內存空間分成了兩部分:地址0~3G-1這段低地址空間為用戶空間,大小為3GB;地址3GB~4GB-1這段高地址空間為內核空間,大小為1GB。
當系統中運行多個程序時,多個用戶空間與內核空間的關系可以表示如下圖:
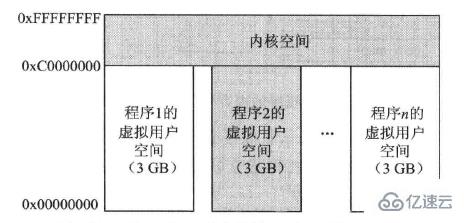
如圖中所示,程序1、2……n共享內核空間。當然,這里的共享指得是分時共享,因為在任何時刻,對于單核處理器系統來說,只能有一個程序在運行。
內核空間的總體布局
Linux在發展過程中,隨著硬件設備的更新和技術水平的提高,其內核空間布局的發展也是一種不斷打補丁的方式。這樣的后果就是使得內核空間被分成不同的幾個區域,而且在不同的區域具有不同的映射方式。通常,人們認為Linux內核空間有三個區域,即DMA區(ZONE_DMA)、普通區(ZONE_NORMAL)和高端內存區(ZONE_HIGHMEM)。
早期計算機實際配置的物理內存通常只有幾MB,所以為了提高內核通過虛擬地址訪問物理地址內存的速度,內核空間的虛擬地址與物理內存地址采用了一種從低地址向高地址依次一一對應的固定映射方式,如下圖所示:
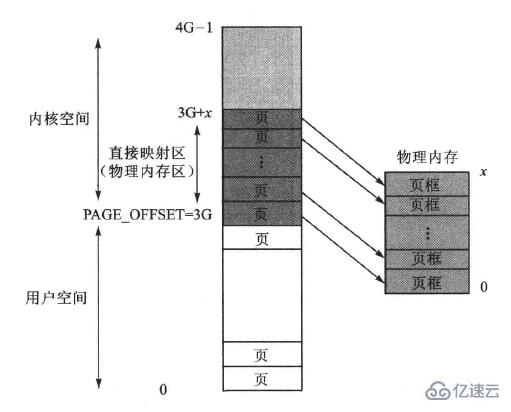
可以看到,這種固定映射方式使得虛擬地址與物理地址的關系變得很簡單,即內核虛擬地址與實際物理地址只在數值上相差一個固定的偏移量PAGE_OFFSET,所以當內核使用虛擬地址訪問物理頁框時,只需在虛擬地址上減去PAGE_OFFSET即可得到實際物理地址,比使用頁表的方式要快得多!
由于這種做法幾乎就是直接使用物理地址,所以這種按固定映射方式的內核空間也就叫做“物理內存空間”,簡稱物理內存。另外,由于固定映射方式是一種線性映射,所以這個區域也叫做線性映射區。
當然,這種情況下(計算機實際物理內存較小時),內核固定映射空間僅占整個1GB內核空間的一部分。例如:在配置32MB實際物理內存的x86計算機系統時,內核的固定映射區便是PAGE_OFFSET~(PAGE_OFFSET+0x02000000)這個32MB空間。那么內核空間剩余的內核虛擬空間怎么辦呢?
當然還是按照普通虛擬空間的管理方式,以頁表的非線性映射方式使用物理內存。具體來說,在整個1GB內核空間中去除固定映射區,然后在剩余部分中再去除其開頭部分的一個8MB隔離區,余下的就是映射方式與用戶空間相同的普通虛擬內存映射區。在這個區,虛擬地址和物理地址不僅不存在固定映射關系,而且通過調用內核函數vmalloc()獲得動態內存,故這個區就被稱為vmalloc分配區,如下圖所示:
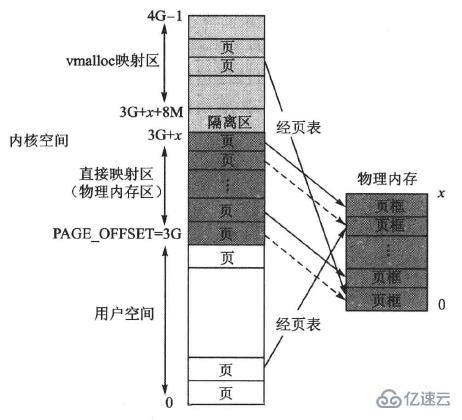
對于配置32MB實際物理內存的x86計算機系統來說,vmalloc分配區的起始位置為PAGE_OFFSET+0x02000000+0x00800000。
這里說明一下:這里說的內核空間與物理頁框的固定映射,實質上是內核頁對物理頁框的一種“預定”,并不是說這些頁就“霸占”了這些物理頁框。即只有當虛擬頁真正需要訪問物理頁框時,虛擬頁才與物理頁框綁定。而平時,當某個物理頁框不被與它對應的虛擬頁所使用時,該頁框完全可以被用戶空間以及后面所介紹的內核kmalloc分配區使用。
總之,在實際物理內存較小的系統中,實際內存的大小就是內核空間的物理內存區與vmalloc分配區的邊界。
對于整個1GB的內核空間,人們還把該空間頭部的16MB叫做DMA區,即ZONE_DMA區,因為以往硬件將DMA空間固定在了物理內存的低16MB空間;其余區則叫做普通區,即ZONE_NORMAL。
內核空間的高端內存
隨著計算機技術的發展,計算機的實際物理內存越來越大,從而使得內核固定映射區(線性區)也越來越大。顯然,如果不加以限制,當實際物理內存達到1GB時,vmalloc分配區(非線性區)將不復存在。于是以前開發的、調用了vmalloc()的內核代碼也就不再可用,顯然為了兼容早期的內核代碼,這是不能允許的。
下圖就表示了這種內核空間所面臨的局面:
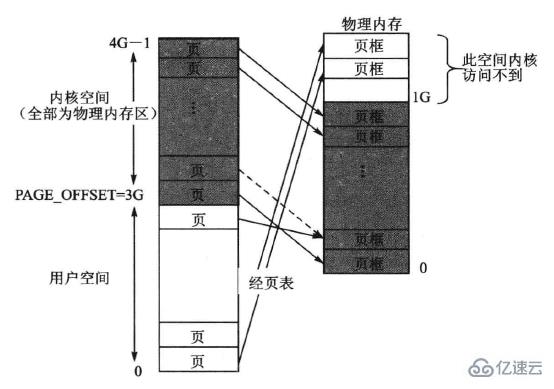
顯然,出現上述問題的原因就是沒有預料到實際物理內存可以超過1GB,因而沒有為內核固定映射區的邊界設定限制,而任由其隨著實際物理內存的增大而增大。
解決上述問題的方法就是:對內核空間固定映射區的上限加以限制,使之不能隨著物理內存的增加而任意增加。Linux規定,內核映射區的上邊界的值最大不能大于一個小于1G的常數high_menory,當實際物理內存較大時,以3G+high_memory為邊界來確定物理內存區。
例如:對于x86系統,high_memory的值為896M,于是1GB內核空間余下的128MB為非線性映射區。這樣就確保在任何情況下,內核都有足夠的非線性映射區以兼容早期代碼并可以按普通虛存方式訪問實際物理內存的1GB以上的空間。
也就是說,高端內存的最基本思想:借一段地址空間,建立臨時地址映射,用完后釋放,達到這段地址空間可以循環使用,訪問所有物理內存。當計算機是物理內存較大時,內核空間的示意圖如下:
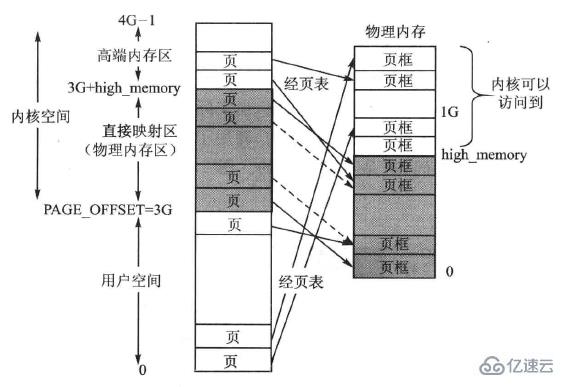
習慣上,Linux把內核空間3G+high_memory~4G-1的這個部分叫做高端內存區(ZONE_HIGHMEM)。
總結一下:在x86結構的內核空間,三種類型的區域(從3G開始計算)如下:
ZONE_DMA:內核空間開始的16MB
ZONE_NORMAL:內核空間16MB~896MB(固定映射)
ZONE_HIGHMEM :內核空間896MB ~ 結束(1G)
根據應用目標不同,高端內存區分vmalloc區、可持久映射區和臨時映射區。內核空間中高端內存的布局如下圖所示:
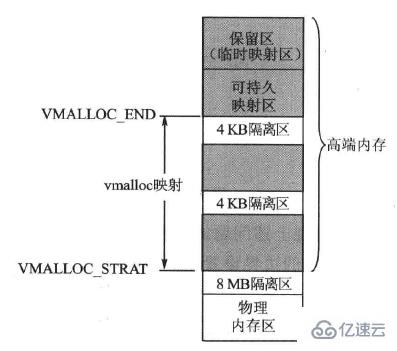
vmalloc映射區時高端內存的主要部分,該區間的頭部與內核線性映射空間之間有一個8MB的隔離區,尾部與后續的可持久映射區有一個4KB的隔離區。
vmalloc映射區的映射方式與用戶空間完全相同,內核可以通過調用函數vmalloc()在這個區域獲得內存。這個函數的功能相當于用戶空間的malloc(),所提供的內存空間在虛擬地址上連續(注意,不保證物理地址連續)。
如果是通過 alloc_page() 獲得了高端內存對應的 page,如何給它找個線性空間?
內核專門為此留出一塊線性空間,從PKMAP_BASE開始,用于映射高端內存,就是可持久內核映射區。
在可持久內核映射區,可通過調用函數kmap()在物理頁框與內核虛擬頁之間建立長期映射。這個空間通常為4MB,最多能映射1024個頁框,數量較為稀少,所以為了加強頁框的周轉,應及時調用函數kunmap()將不再使用的物理頁框釋放。
臨時映射區也叫固定映射區和保留區。該區主要應用在多處理器系統中,因為在這個區域所獲得的內存空間沒有所保護,故所獲得的內存必須及時使用;否則一旦有新的請求,該頁框上的內容就會被覆蓋,所以這個區域叫做臨時映射區。
關于高端內存區一篇很不錯的文章:linux 用戶空間與內核空間——高端內存詳解。
內核內存分配修飾符gfp
為了在內核內存請求函數對請求進行必要的說明,Linux定義了多種內存分配修飾符gfp。它們是行為修飾符、區修飾符、類型修飾符。
在內存分配函數中的行為修飾符說明內核應當如何分配內存。主要行為修飾符如下:
| 修飾符 | 說明 |
| __GFP_WAIT | 分配器可以休眠 |
| __GFP_HIGH | 分配器可以訪問緊急事件緩沖池 |
| __GFP_IO | 分配器可以啟動磁盤IO |
| __GFP_FS | 分配器可以啟動文件系統IO |
| __GFP_COLD | 分配器應該使用高速緩沖中快要淘汰的頁框 |
| __GFP_NOWARN | 分配器不發出警告 |
| __GFP_REPEAT | 分配失敗時重新分配 |
| __GFP_NOFAILT | 分配失敗時重新分配,直至成功 |
| __GFP_NORETRY | 分配失敗時不再重新分配 |
區修飾符說明需要從內核空間的哪個區域中分配內存。內存分配器默認從內核空間的ZONE_NORMAL開始逐漸向高端獲取為內存請求者分配內存區,如果用戶特意需要從ZONE_DMA或ZONE_HOGNMEM獲得內存,那么就需要內存請求者在內存請求函數中使用以下兩個區修飾符說明:
| 修飾符 | 說明 |
| __GFP_DMA | 從ZONE_DMA區分配內存 |
| __GFP_HIGHMEM | 從ZONE_HIGHMEM區分配內存 |
類型修飾符實質上是上述所述修飾符的聯合應用。也就是:將上述的某些行為修飾符和區修飾符,用“|”進行連接并另外取名的修飾符。這里就不多介紹了。
內核常用內存分配及地址映射函數
函數vmalloc()在vmalloc分配區分配內存,可獲得虛擬地址連續,但并不保證其物理頁框連續的較大內存。與物理空間的內存分配函數malloc()有所區別,vmalloc()分配的物理頁不會被交換出去。函數vmalloc()的原型如下:
void *vmalloc(unsigned long size)
{
return __vmalloc(size, GFP_KERNEL | __GFP_HIGHMEM, PAGE_KERNEL);
}void *__vmalloc(unsigned long size, gfp_t gfp_mask, pgprot_t prot)
{
return kmalloc(size, (gfp_mask | __GFP_COMP) & ~__GFP_HIGHMEM);
}
其中,參數size為所請求內存的大小,返回值為所獲得內存虛擬地址指針。
與vmalloc()配套的釋放函數如下:
void vfree(const void *addr)
{
kfree(addr);
}
其中,參數addr為待釋放內存指針。
kmalloc()是內核另一個常用的內核分配函數,它可以分配一段未清零的連續物理內存頁,返回值為直接映射地址。由kmalloc()可分配的內存最大不能超過32頁。其優點是分配速度快,缺點是不能分配大于128KB的內存頁(出于跨平臺考慮)。
在linux/slab.h文件中,該函數的原型聲明如下:
static __always_inline void *kmalloc(size_t size, gfp_t flags)
{
struct kmem_cache *cachep;
void *ret;
if (__builtin_constant_p(size)) {
int i = 0;
if (!size)
return ZERO_SIZE_PTR;
#define CACHE(x) \
if (size <= x) \
goto found; \
else \
i++;
#include <linux/kmalloc_sizes.h>
#undef CACHE
return NULL;
found:
#ifdef CONFIG_ZONE_DMA
if (flags & GFP_DMA)
cachep = malloc_sizes[i].cs_dmacachep;
else
#endif
cachep = malloc_sizes[i].cs_cachep;
ret = kmem_cache_alloc_notrace(cachep, flags);
trace_kmalloc(_THIS_IP_, ret,
size, slab_buffer_size(cachep), flags);
return ret;
}
return __kmalloc(size, flags);
}
其中,參數size為以字節為單位表示的所申請空間的大小;參數flags決定了所分配的內存適合什么場合。
與函數kmalloc()對應的釋放函數如下:
void kfree(const void *objp)
{
struct kmem_cache *c;
unsigned long flags;
trace_kfree(_RET_IP_, objp);
if (unlikely(ZERO_OR_NULL_PTR(objp)))
return;
local_irq_save(flags);
kfree_debugcheck(objp);
c = virt_to_cache(objp);
debug_check_no_locks_freed(objp, obj_size(c));
debug_check_no_obj_freed(objp, obj_size(c));
__cache_free(c, (void *)objp);
local_irq_restore(flags);
}
小結一下,kmalloc、vmalloc、malloc的區別:
kmalloc和vmalloc是分配的是內核的內存,malloc分配的是用戶的內存;
kmalloc保證分配的內存在物理上是連續的,vmalloc保證的是在虛擬地址空間上的連續,malloc不保證任何東西;
kmalloc能分配的大小有限,vmalloc和malloc能分配的大小相對較大;
vmalloc比kmalloc要慢。
也就是說:kmalloc、vmalloc這兩個函數所分配的內存都處于內核空間,即從3GB~4GB;但位置不同,kmalloc()分配的內存處于3GB~high_memory(ZONE_DMA、ZONE_NORMAL)之間,而vmalloc()分配的內存在VMALLOC_START~4GB(ZONE_HIGHMEM)之間,也就是非連續內存區。一般情況下在驅動程序中都是調用kmalloc()來給數據結構分配內存,而vmalloc()用在為活動的交換區分配數據結構,為某些I/O驅動程序分配緩沖區,或為模塊分配空間。
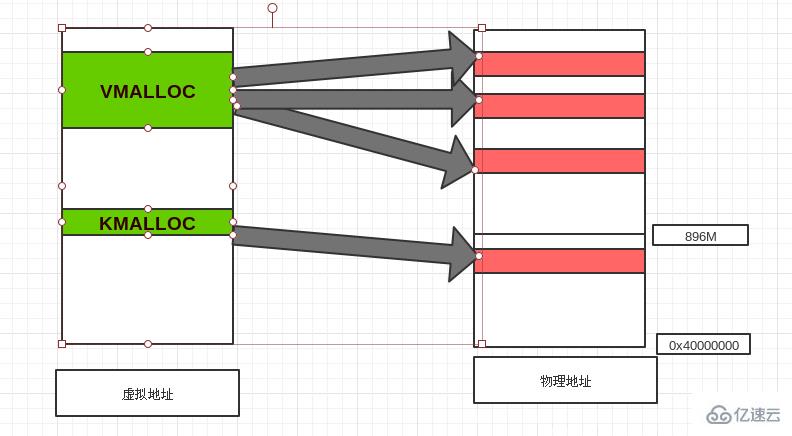
與上述在虛擬空間分配內存的函數不同,alloc_pages()是在物理內存空間分配物理頁框的函數,其原型如下:
其中,參數order表示所分配頁框的數目,該數目為2^order。order的最大值由include/Linux/Mmzone.h文件中的宏MAX_ORDER決定。參數gfp_mask為說明內存頁框分配方式及使用場合。static inline struct page * alloc_pages(gfp_t gfp_mask, unsigned int order)
{
if (unlikely(order >= MAX_ORDER))
return NULL;
return alloc_pages_current(gfp_mask, order);
}
函數返回值為頁框塊的第一個頁框page結構的地址。
調用下列函數可以獲得頁框的虛擬地址:
void *page_address(struct page *page)
{
unsigned long flags;
void *ret;
struct page_address_slot *pas;
if (!PageHighMem(page))
return lowmem_page_address(page);
pas = page_slot(page);
ret = NULL;
spin_lock_irqsave(&pas->lock, flags);
if (!list_empty(&pas->lh)) {
struct page_address_map *pam;
list_for_each_entry(pam, &pas->lh, list) {
if (pam->page == page) {
ret = pam->virtual;
goto done;
}
}
}
done:
spin_unlock_irqrestore(&pas->lock, flags);
return ret;
}
使用函數alloc_pages()獲得的內存應該使用下面的函數釋放:
函數kmap()void __free_pages(struct page *page, unsigned int order)
{
if (put_page_testzero(page)) {
if (order == 0)
free_hot_page(page);
else
__free_pages_ok(page, order);
}
}
kmap()是一個映射函數,它可以將一個物理頁框映射到內核空間的可持久映射區。這種映射類似于內核ZONE_NORMAL的固定映射,但虛擬地址與物理地址的偏移不一定是PAGE_OFFSET。由于內核可持久映射區的容量有限(總共只有4MB),因此當內存使用完畢后,應該立即釋放。
函數kmap()的函數原型如下:
void *kmap(struct page *page)
{
might_sleep();
if (!PageHighMem(page))
return page_address(page);
return kmap_high(page);
}
小結
由于CPU的地址總線只有32位, 32的地址總線無論是從邏輯上還是從物理上都只能描述4G的地址空間(232=4Gbit),在物理上理論上最多擁有4G內存(除了IO地址空間,實際內存容量小于4G),邏輯空間也只能描述4G的線性地址空間。
為了合理的利用邏輯4G空間,Linux采用了3:1的策略,即內核占用1G的線性地址空間,用戶占用3G的線性地址空間。所以用戶進程的地址范圍從0~3G,內核地址范圍從3G~4G,也就是說,內核空間只有1G的邏輯線性地址空間。
如果Linux物理內存小于1G的空間,通常內核把物理內存與其地址空間做了線性映射,也就是一一映射,這樣可以提高訪問速度。但是,當Linux物理內存超過1G時,線性訪問機制就不夠用了,因為只能有1G的內存可以被映射,剩余的物理內存無法被內核管理,所以,為了解決這一問題,Linux把內核地址分為線性區和非線性區兩部分,線性區規定最大為896M,剩下的128M為非線性區。從而,線性區映射的物理內存成為低端內存,剩下的物理內存被成為高端內存。與線性區不同,非線性區不會提前進行內存映射,而是在使用時動態映射。
低端內存又分成兩部分:ZONE_DMA:內核空間開始的16MB、ZONE_NORMAL:內核空間16MB~896MB(固定映射)。剩下的就是高端內存:ZONE_HIGHMEM :內核空間896MB ~ 結束(1G)。
根據應用目標不同,高端內存區分vmalloc區、可持久映射區和臨時映射區三部分。vmalloc區使用vmalloc()函數進行分配;可持久映射區使用allc_pages()獲得對應的 page,在利用kmap()函數直接映射;臨時映射區一般用于特殊需求。
| 內核空間(3G~4G) | 高端內存(3G+high_memory~4G)ZONE_HIGHMEM 非線性映射區 | 臨時映射區 |
| 可持久映射區 | ||
| vmalloc區 | ||
低端內存(3G~3G+high_memory-1) 線性映射區(固定映射區) | ZONE_NORMAL | |
| ZONE_DMA | ||
| 用戶空間(0~3G-1) | 頁目錄-->中間頁目錄-->頁表 | |
到此,關于“linux驅動程序運行空間是什么”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





