溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“Kotlin的Collection與Sequence操作異同點是什么”,內容詳細,步驟清晰,細節處理妥當,希望這篇“Kotlin的Collection與Sequence操作異同點是什么”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
Collection 集合,Kotlin的集合類型和Java不一樣,Kotlin的集合分為可變(讀寫)和不可變(只讀)類型(lists, sets, maps, etc),可變類型是在不可變類型前面加Mutable,以我們常用的三種集合類型為例:
List<out E> - MutableList<E> Set<out E> - MutableSet<E> Map<K, out V> - MutableMap<K, V>
其實他們的區別就是List實現了Collection接口,而MutableList實現的是List和MutableCollection接口。而 MutableCollection 接口實現了Collection 接口,并且在里面添加了add和remove等操作方法。
可變不可變只是為了區分只讀和讀寫的操作,他們的操作符方式都是相同的。
集合的操作符說起來可就太多了
//對所有元素求和
list.sum()
//將集合中的每一個元素代入lambda表達式,然后對lambda表達式的返回值求和
list.sumBy {
it % 2
}
//在一個初始值的基礎上,從第一項到最后一項通過一個函數累計所有的元素
list.fold(100) { accumulator, element ->
accumulator + element / 2
}
//同fold,只是迭代的方向相反
list.foldRight(100) { accumulator, element ->
accumulator + element / 2
}
//同fold,只是accumulator的初始值就是集合的第一個元素,element從第二個元素開始
list.reduce { accumulator, element ->
accumulator + element / 2
}
//同reduce但方向相反:accumulator的初始值就是集合的最后一個元素,element從倒數第二個元素開始往前迭代
list.reduceRight { accumulator, element ->
accumulator + element / 2
}
val list = listOf(1, 2, 3, 4, 5, 6)
//只要集合中的任何一個元素滿足條件(使得lambda表達式返回true),any函數就返回true
list.any {
it >= 0
}
//集合中的全部元素都滿足條件(使得lambda表達式返回true),all函數才返回true
list.all {
it >= 0
}
//若集合中沒有元素滿足條件(使lambda表達式返回true),則none函數返回true
list.none {
it < 0
}
//count函數的返回值為:集合中滿足條件的元素的總數
list.count {
it >= 0
}//遍歷所有元素
list.forEach {
print(it)
}
//同forEach,只是可以同時拿到元素的索引
list.forEachIndexed { index, value ->
println("position $index contains a $value")
}
showFields.forEach { (key, value) ->//返回集合中最大的元素,集合為空(empty)則返回null
list.max()
//返回集合中使得lambda表達式返回值最大的元素,集合為空(empty)則返回null
list.maxBy { it }
//返回集合中最小的元素,集合為空(empty)則返回null
list.min()
//返回集合中使得lambda表達式返回值最小的元素,集合為空(empty)則返回null
list.minBy { it }//返回一個新List,去除集合的前n個元素
list.drop(2)
//返回一個新List,去除集合的后n個元素
list.dropLast(2)
//返回一個新List,去除集合中滿足條件(lambda返回true)的第一個元素
list.dropWhile {
it > 3
}
//返回一個新List,去除集合中滿足條件(lambda返回true)的最后一個元素
list.dropLastWhile {
it > 3
}
//返回一個新List,包含前面的n個元素
list.take(2)
//返回一個新List,包含最后的n個元素
list.takeLast(2)
//返回一個新List,僅保留集合中滿足條件(lambda返回true)的第一個元素
list.takeWhile {
it>3
}
//返回一個新List,僅保留集合中滿足條件(lambda返回true)的最后一個元素
list.takeLastWhile {
it>3
}
//返回一個新List,僅保留集合中滿足條件(lambda返回true)的元素,其他的都去掉
list.filter {
it > 3
}
//返回一個新List,僅保留集合中不滿足條件的元素,其他的都去掉
list.filterNot {
it > 3
}
//返回一個新List,僅保留集合中的非空元素
list.filterNotNull()
//返回一個新List,僅保留指定索引處的元素
list.slice(listOf(0, 1, 2))//將集合中的每一個元素代入lambda表達式,lambda表達式必須返回一個元素
//map的返回值是所有lambda表達式的返回值所組成的新List
//例如下面的代碼和listOf(2,4,6,8,10,12)將產生相同的List
list.map {
it * 2
}
//將集合中的每一個元素代入lambda表達式,lambda表達式必須返回一個集合
//而flatMap的返回值是所有lambda表達式返回的集合中的元素所組成的新List
//例如下面的代碼和listOf(1,2,2,3,3,4,4,5,5,6,6,7)將產生相同的List
list.flatMap {
listOf(it, it + 1)
}
//和map一樣,只是lambda表達式的參數多了一個index
list.mapIndexed { index, it ->
index * it
}
//和map一樣,只不過只有lambda表達式的非空返回值才會被包含在新List中
list.mapNotNull {
it * 2
}
//根據lambda表達式對集合元素進行分組,返回一個Map
//lambda表達式的返回值就是map中元素的key
//例如下面的代碼和mapOf("even" to listOf(2,4,6),"odd" to listOf(1,3,5))將產生相同的map
list.groupBy {
if (it % 2 == 0) "even" else "odd"
}list.contains(2)
list.elementAt(0)
//返回指定索引處的元素,若索引越界,則返回null
list.elementAtOrNull(10)
//返回指定索引處的元素,若索引越界,則返回lambda表達式的返回值
list.elementAtOrElse(10) { index ->
index * 2
}
//返回list的第一個元素
list.first()
//返回list中滿足條件的第一個元素
list.first {
it > 1
}
//返回list的第一個元素,list為empty則返回null
list.firstOrNull()
//返回list中滿足條件的第一個元素,沒有滿足條件的則返回null
list.firstOrNull {
it > 1
}
list.last()
list.last { it > 1 }
list.lastOrNull()
list.lastOrNull { it > 1 }
//返回元素2第一次出現在list中的索引,若不存在則返回-1
list.indexOf(2)
//返回元素2最后一次出現在list中的索引,若不存在則返回-1
list.lastIndexOf(2)
//返回滿足條件的第一個元素的索引
list.indexOfFirst {
it > 2
}
//返回滿足條件的最后一個元素的索引
list.indexOfLast {
it > 2
}
//返回滿足條件的唯一元素,如果沒有滿足條件的元素或滿足條件的元素多于一個,則拋出異常
list.single {
it == 5
}
//返回滿足條件的唯一元素,如果沒有滿足條件的元素或滿足條件的元素多于一個,則返回null
list.singleOrNull {
it == 5
}val list = listOf(1, 2, 3, 4, 5, 6)
//返回一個顛倒元素順序的新集合
list.reversed()
/**
* 返回一個升序排序后的新集合
*/
list.sorted()
//將每個元素代入lambda表達式,根據lambda表達式返回值的大小來對集合進行排序
list.sortedBy {
it*2
}
/**
* 功能和上面一樣 -> 上面是從小到大排列,這個返回的是從大到小
*/
list.sortedDescending()
list.sortedByDescending {
it*2
}
/**
* 根據多個條件排序
* 先根據age 升序排列,若age相同,根據name升序排列,但是都是默認的升序排列
*/
personList.sortWith(compareBy({ it.age }, { it.name }))
/**
* 根據多個條件排序,自定義的規則
* 構造一個Comparator對象,完成排序邏輯:先按age降序排列,若age相同,則按name升序排列
*/
val c1: Comparator<Person> = Comparator { o1, o2 ->
if (o2.age == o1.age) {
o1.name.compareTo(o2.name)
} else {
o2.age - o1.age
}
}
personList.sortWith(c1)
//上面的自定義方式可以通過JavaBean實現Comparable 接口實現自定義的排序
data class Person(var name: String, var age: Int) : Comparable<Person> {
override fun compareTo(other: Person): Int {
if (this.age == other.age) {
return this.name.compareTo(other.name)
} else {
return other.age - this.age
}
}
}
//sorted 方法返回排序好的list(已有有排序規則的用sorted,不要用sortedby了)
val sorted = personList.sorted()Sequence 是 Kotlin 中一個新的概念,用來表示一個延遲計算的集合。Sequence 只存儲操作過程,并不處理任何元素,直到遇到終端操作符才開始處理元素,我們也可以通過 asSequence 擴展函數,將現有的集合轉換為 Sequence ,代碼如下所示
val list = mutableListOf<Person>()
for (i in 1..10000) {
list.add(Person("name$i", (0..100).random()))
}
list.asSequence()當我們拿到結果之后我們還能通過toList再轉換為集合。
list.asSequence().toList()
Sequence的操作符絕大部分都是和 Collection 類似的。常用的一些操作符是可以直接平替使用的。
val list2 = list.asSequence()
.filter {
it.age > 50
}.map {
it.name
}.take(3).toList()居然他們的操作符都長的一樣,效果也都一樣,導致 Sequence 與 Collection 就很類似,那么既生瑜何生亮!為什么需要這么個東西?既然 Collection 能實現效果為什么還需要 Sequence 呢?他們的區別又是什么呢?
Collection 是立即執行的,每一次中間操作都會立即執行,并且把執行的結果存儲到一個容器中,沒多一個中間操作符就多一個容器存儲結果。
public inline fun <T, R> Iterable<T>.map(transform: (T) -> R): List<R> {
return mapTo(ArrayList<R>(collectionSizeOrDefault(10)), transform)
}
public inline fun <T> Iterable<T>.filter(predicate: (T) -> Boolean): List<T> {
return filterTo(ArrayList<T>(), predicate)
}比如常用的 map 和 filter 都是會新建一個 ArrayList 去存儲結果,
Sequence 是延遲執行的,它有兩種類型,中間操作和末端操作 ,主要的區別是中間操作不會立即執行,它們只是被存儲起來,中間操作符會返回另一個Sequence,僅當末端操作被調用時,才會按照順序在每個元素上執行中間操作,然后執行末端操作。
public fun <T, R> Sequence<T>.map(transform: (T) -> R): Sequence<R> {
return TransformingSequence(this, transform)
}
public fun <T> Sequence<T>.filter(predicate: (T) -> Boolean): Sequence<T> {
return FilteringSequence(this, true, predicate)
}比如常用的 map 和 filter 都是直接返回 Sequence 的this 對象。
public inline fun <T> Sequence<T>.first(predicate: (T) -> Boolean): T {
for (element in this) if (predicate(element)) return element
throw NoSuchElementException("Sequence contains no element matching the predicate.")
}然后在末端操作中,會對 Sequence 中的元素進行遍歷,直到預置條件匹配為止。
這里我們舉一個示例來演示一下:
我們使用同樣的篩選與轉換,來看看效果
val list = mutableListOf<Person>()
for (i in 1..10000) {
list.add(Person("name$i", (0..100).random()))
}
val time = measureTimeMillis {
val list1 = list.filter {
it.age > 50
}.map {
it.name
}.take(3)
YYLogUtils.w("list1$list1")
}
YYLogUtils.w("耗費的時間$time")
val time2 = measureTimeMillis {
val list2 = list.asSequence()
.filter {
it.age > 50
}.map {
it.name
}.take(3).toList()
YYLogUtils.w("list2$list2")
}
YYLogUtils.w("耗費的時間2$time2")運行結果:
當集合數量為10000的時候,執行時間能優秀百分之50左右:
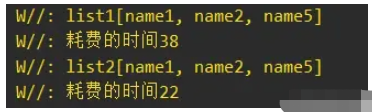
當集合數量為5000的時候,執行時間相差比較接近:
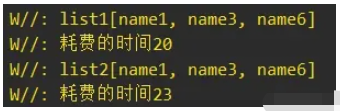
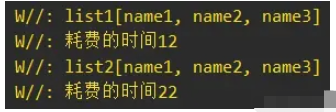
當集合數量為3000的時候,此時的結果就反過來了,Sequence延時執行的優化效果就不如List轉換Sequence再轉換List了:
讀到這里,這篇“Kotlin的Collection與Sequence操作異同點是什么”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





