溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
完整源碼在我的github上 https://github.com/NashLegend/QuicKid
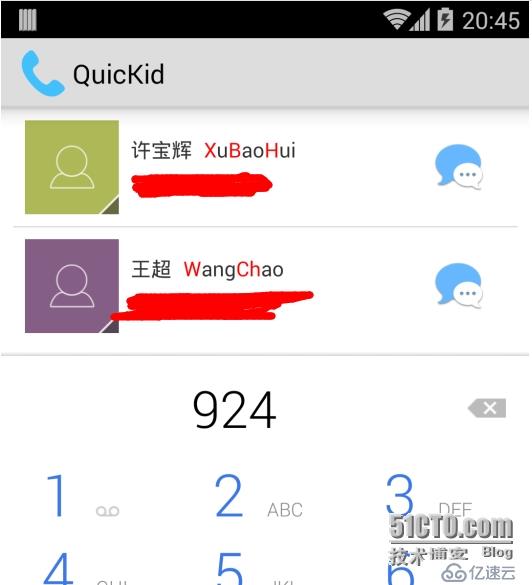
智能撥號是指,呃不用解釋了,國內撥號軟件都帶的大家都知道,就是輸入姓名拼音的一部分就可快速搜索出聯系人的撥號方式。如下圖
智能匹配,很容易想到的就是先把九宮格輸入鍵盤上輸入的數字轉換成可能的拼音組合,然后再用這些可能的拼音與聯系人列表中的姓名拼音一一匹配,取匹配度最高的排到最前,但是這有一個問題就是數組對應的可能的拼音組合實在是點兒多,跑一下下面的代碼就知道了。如果想智能一些的話還要先剔除一些不可能的拼音組合實在有點麻煩。
public static HashMap<Character, String[]> keyMaps;
public static void main(String[] args) {
keyMaps = new HashMap<Character, String[]>();
keyMaps.put('0', new String[0]);
keyMaps.put('1', new String[0]);
keyMaps.put('2', new String[] { "a", "b", "c" });
keyMaps.put('3', new String[] { "d", "e", "f" });
keyMaps.put('4', new String[] { "g", "h", "i" });
keyMaps.put('5', new String[] { "j", "k", "l" });
keyMaps.put('6', new String[] { "m", "n", "o" });
keyMaps.put('7', new String[] { "p", "q", "r", "s" });
keyMaps.put('8', new String[] { "t", "u", "v" });
keyMaps.put('9', new String[] { "w", "x", "y", "z" });
List<String> lss = getPossibleKeys("726");
System.out.println(lss.size());
}
public static ArrayList<String> getPossibleKeys(String key) {
ArrayList<String> list = new ArrayList<String>();
if (key.length() > 0) {
if (key.contains("1") || key.contains("0")) {
list.add(key);
} else {
int keyLen = key.length();
String[] words;
if (keyLen == 1) {
words = keyMaps.get(key.charAt(0));
for (int i = 0; i < words.length; i++) {
list.add(words[i]);
}
} else {
ArrayList<String> sonList = getPossibleKeys(key.substring(
0, key.length() - 1));
words = keyMaps.get(key.charAt(key.length() - 1));
for (int i = 0; i < words.length; i++) {
for (Iterator<String> iterator = sonList.iterator(); iterator
.hasNext();) {
String sonStr = iterator.next();
list.add(sonStr + words[i]);
}
}
}
}
}
return list;
}所以可以反過來想,為什么一定要匹配拼音呢。其實我們可以匹配數字,將姓名的拼音轉化成九宮格上的數字,比如張三就是94264,726。用輸入的數字來匹配這些數字,匹配次數將大大減少。匹配出的數值越高,匹配度越強。
完全匹配。用來匹配姓名和電話號碼。指輸入字符串與聯系人內某一匹配項完全匹配。無加減分項。
PanZhiHui-->PanZhiHui
前置首字母完全匹配。用來匹配姓名。指輸入字符串與聯系人前幾個首字母完全匹配。用來匹配姓名。是前置首字母溢出匹配的特殊形式。 無加分項,減分項為不匹配的首字母個數。
PZH-->PanZhiHui。+2-0PZ-->PanZhiHui。+2-1
前置首字母溢出匹配。用來匹配姓名。指在匹配首字母的情況下,還匹配了某一個或者幾個首字母后一段連貫的字符串。加分項為匹配到的首字母個數,減分項為不匹配的首字母個數。
PanZH-->PanZhiHui。+1-0PZhiHui-->PanZhiHui。+1-0PZHui-->PanZhiHui。+1-0PZHu-->PanZhiHui。+1-0PZhi-->PanZhiHui。+1-1
前置段匹配。用來匹配姓名。指一個長度為N的連貫字符與聯系人內某一匹配項的前N個字符完全匹配。是前置首字母溢出匹配的特殊形式。
panzh-->PanZhiHui
后置首字母完全匹配。用來匹配姓名。指輸入字符串匹配除第一個首字母以外的其他幾個連續首字母。 無加分項,減分項為不匹配的首字母個數。
ZH-->PanZhiHui
后置首字母溢出匹配。用來匹配姓名。后置首字母完全匹配的情況下,還匹配了某一個或者幾個首字母后一段連貫的字符串。加分項為匹配的首字母的數量,減分項為不匹配的首字母個數。
ZHu-->PanZhiHui。+1-0Zh-->PanZhiRui。+1-1
后置段匹配。用來匹配姓名。指有一串長度為N的連貫字符與與聯系人內某一匹配項的后半部的一段N個字符串匹配,且此連貫字符的開頭位置必須是某一首字母位置。是后置首字母溢出匹配的特殊形式,同時意味著后置首字母溢出匹配事實上不需要加分項,只要保證后置首字母完全匹配的加分項比它大就足夠了。
ZhiHui/Zhi/Hui-->PanZhiHui
后置無頭匹配。用來匹配姓名和電話號碼。指一串連貫字符在前7種全部未匹配成功的情況下,卻被包含在字符串里。加分項為-index,減分項為長度差
hiHui-->PanZhiHui
每個規則都有一個基礎數值,以及加分減分項,基本數值不同。取減分項為0.001,加分項為1。至于為什么,在下一段。
查詢時匹配以上8種,其他情況不匹配。
匹配的原則是匹配盡可能多的單詞。
上面這些名字完全是臨時胡編亂造的好么 0.0
查詢出的列表將按匹配度排序,匹配度是一個float(當然double也一樣),優先級別從高到低如下(減分項足夠小以至于高優先級的匹配度無論如何減分都仍然會高于下面的優先級,因此減分項事實上只用來區別同一優先級中不同聯系人匹配程度的高低)。
完全匹配,對應的基礎數值為4000。
前置首字母完全匹配、前置首字母溢出匹配、前置段匹配,這三個其實都可以視作前置首字母溢出匹配,對應的基礎數值為3000。(當只有一個字母時,按規則#1算)
后置首字母完全匹配、后置首字母溢出匹配、后置段匹配,這三個其實都可以視作后置首字母溢出匹配。對應的基礎數值為2000。(當只有一個字母時,按規則#5算)
后置無頭匹配。對應的基礎數值為1000。(可以考慮摒棄此匹配,沒有人會這么按,而按鍵出錯的可能性導致無頭匹配的可能性又極小,往往不是想要的結果)
輸入的一列查詢字符串將同時與聯系人的名字和電話匹配。對于一個聯系人,他的名字可能有多種發音,這時候要取匹配度最高的。對于一個聯系人,他可能有兩個甚至更多的電話號碼,匹配的時候要分別匹配,而不是單獨取匹配度最高的。
好了,先寫一個類Contact。
添加幾個常量,看字面意思應該看得懂。
static final int Match_Type_Name = 1; static final int Match_Type_Phone = 2; static final int Level_Complete = 4; static final int Level_Fore_Acronym_Overflow = 3; static final int Level_Back_Acronym_Overflow = 2; static final int Level_Headless = 1; static final int Level_None = 0; static final float Match_Level_None = 0; static final float Match_Level_Headless = 1000; static final float Match_Level_Back_Acronym_Overflow = 2000; static final float Match_Level_Fore_Acronym_Overflow = 3000; static final float Match_Level_Complete = 4000; static final float Match_Score_Reward = 1; static final float Match_Miss_Punish = 0.001f; static final int Max_Reward_Times = 999; static final int Max_Punish_Times = 999;
再添加下面幾條字段
List<ArrayList<String>> fullNameNumber = new ArrayList<ArrayList<String>>(); List<String> fullNameNumberWithoutSpace = new ArrayList<String>(); List<String> abbreviationNumber = new ArrayList<String>();
fullNameNumber是一個二維的ArrayList,它存放的是將一個聯系人打散后數字后的List。比如張三的fullNameString就是{{94264,726}},之所以是二維的,原因是有可能姓名是含有多音字……
fullNameNumberWithoutSpace是聯系人姓名的全拼對應的數字,比如張三就是{94264726},之所以是二維的,原因是有可能姓名是含有多音字……
abbreviationNumber是聯系人姓名首字母對應的數字,比如張三對應的就是{97},之所以是二維的,原因是有可能姓名是含有多音字……
在設置了Contact的名字后上面三個字段將同時生成數據。
synchronized public void initPinyin() {
String trimmed = name.replaceAll(" ", "");
//將姓名轉化為拼音
String fullNamesString = HanyuPinyinHelper.hanyuPinYinConvert(trimmed, false);
for (Iterator<String> iterator = fullNamesString.iterator(); iterator
.hasNext();) {
String str = iterator.next();
ArrayList<String> lss = new ArrayList<String>();
String[] pinyins = TextUtil.splitIgnoringEmpty(str, " ");
String abbra = "";
String fullNameNumberWithoutSpaceString = "";
for (int i = 0; i < pinyins.length; i++) {
String string = pinyins[i];
String res = convertString2Number(string);
abbra += res.charAt(0);
fullNameNumberWithoutSpaceString += res;
lss.add(res);
}
abbreviationNumber.add(abbra);
fullNameNumberWithoutSpace
.add(fullNameNumberWithoutSpaceString);
fullNameNumber.add(lss);
}
}給它一個match方法。下面調用的xxxMatch()方法都是針對四種不同種類的匹配的對應方法。
public float match(String reg) {
// 無法通過第一個字母來判斷是不是后置匹配
// 但是可以通過第一個字母判斷是不是前置匹配
// match的原則是匹配盡可能多的字符
// 事實上前五種匹配方式都可以使用crossMatch來實現
ScoreAndHits scoreAndHits = new ScoreAndHits(-1, 0f,
new ArrayList<PointPair>());
if (!TextUtils.isEmpty(reg)) {
boolean checkBack = !canPrematch(reg);
if (!checkBack) {
if ((scoreAndHits = completeMatch(reg)).score == 0f) {
if ((scoreAndHits = foreAcronymOverFlowMatch(reg)).score == 0f) {
checkBack = true;
}
}
}
if (checkBack) {
if ((scoreAndHits = backAcronymOverFlowMatch(reg)).score == 0f) {
scoreAndHits = backHeadlessParagraphMatch(reg);
}
}
}
scoreAndHits.reg = reg;
matchValue = scoreAndHits;
return scoreAndHits.score;
}所有的xxxMatch返回的結果是一個自定義類ScoreAndHits。
public static class ScoreAndHits {
public float score = 0f;
public int nameIndex;
public ArrayList<PointPair> pairs = new ArrayList<PointPair>();
public int matchType = Match_Type_Name;
public int matchLevel = Level_None;
public String reg = "";
public ScoreAndHits(int nameIndex, float score,
ArrayList<PointPair> pairs) {
this.nameIndex = nameIndex;
this.score = score;
this.pairs = pairs;
}
}nameIndex是匹配到了第幾個拼音。score是匹配度。pairs是指匹配到的數字在對應的二維list中的位置,用來將來高亮顯示匹配的字符用的。如果完全匹配的話,就用不到pairs了。
幾個匹配方法的具體內容看下一篇,超過字數限制,寫不開了
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





