溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Python怎么實現文本特征提取”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“Python怎么實現文本特征提取”文章能幫助大家解決問題。
創建一個字典,觀察如下數據形式的變化:
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
data = [{'city': '洛陽', 'temperature': 39},
{'city': '成都', 'temperature': 41},
{'city': '寧波', 'temperature': 42},
{'city': '佛山', 'temperature': 38}]
df1 = pd.DataFrame(data)
print(df1)
# one-hot編碼 因為temperature是數值型的,所以會保留原始值,只有字符串類型的才會生成虛擬變量
df2 = pd.get_dummies(df1)
print(df2)輸出如下:

使用DictVectorizer()創建字典特征提取模型
# 1.創建對象 默認sparse=True 返回的是sparse矩陣; sparse=False 返回的是ndarray矩陣 transfer = DictVectorizer() # 2.轉化數據并訓練 trans_data = transfer.fit_transform(data) print(transfer.get_feature_names_out()) print(trans_data)

使用sparse矩陣沒有顯示0數據,節約了內存,更為簡潔,這一點比ndarray矩陣更好。
文本特征提取使用的是CountVectorizer文本特征提取模型,這里準備了一段英文文本(I have a dream)。統計詞頻并得到sparse矩陣,代碼如下所示:
CountVectorizer()沒有sparse參數,默認采用sparse矩陣格式。且可以通過stop_words指定停用詞。
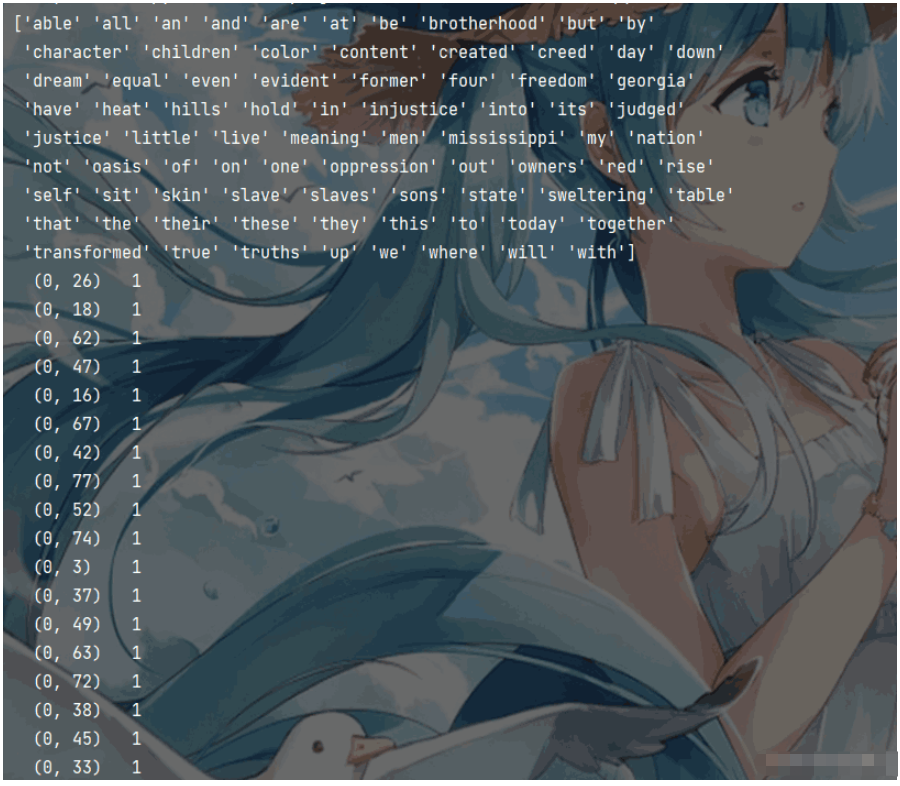
from sklearn.feature_extraction.text import CountVectorizer data = ["I have a dream that one day this nation will rise up and live out the true meaning of its creed", "We hold these truths to be self-evident, that all men are created equal", "I have a dream that one day on the red hills of Georgia, " "the sons of former slaves and the sons of former slave owners will be able to sit down together at the table of brotherhood", "I have a dream that one day even the state of Mississippi", " a state sweltering with the heat of injustice", "sweltering with the heat of oppression", "will be transformed into an oasis of freedom and justice", "I have a dream that my four little children will one day live in a nation where they will not be judged by the color of their skin but by the content of their character", "I have a dream today"] # CountVectorizer文本特征提取模型 # 1.實例化 將"is"標記為停用詞 c_transfer = CountVectorizer(stop_words=["is"]) # 2.調用fit_transform c_trans_data = c_transfer.fit_transform(data) # 打印特征名稱 print(c_transfer.get_feature_names_out()) # 打印sparse矩陣 print(c_trans_data)
輸出結果如下圖所示:
準備一段中文文本(data.txt),以水滸傳中風雪山神廟情節為例:
大雪下的正緊,林沖和差撥兩個在路上又沒買酒吃處。早來到草料場外,看時,一周遭有些黃土墻,兩扇大門。推開看里面時,七八間草房做著倉廒,四下里都是馬草堆,中間兩座草廳。到那廳里,只見那老軍在里面向火。差撥說道:“管營差這個林沖來替你回天王堂看守,你可即便交割。”老軍拿了鑰匙,引著林沖,分付道:“倉廒內自有官司封記,這幾堆草一堆堆都有數目。”老軍都點見了堆數,又引林沖到草廳上。老軍收拾行李,臨了說道:“火盆、鍋子、碗碟,都借與你。”林沖道:“天王堂內我也有在那里,你要便拿了去。”老軍指壁上掛一個大葫蘆,說道:“你若買酒吃時,只出草場,投東大路去三二里,便有市井。”老軍自和差撥回營里來。 只說林沖就床上放了包裹被臥,就坐下生些焰火起來。屋邊有一堆柴炭,拿幾塊來生在地爐里。仰面看那草屋時,四下里崩壞了,又被朔風吹撼,搖振得動。林沖道:“這屋如何過得一冬?待雪晴了,去城中喚個泥水匠來修理。”向了一回火,覺得身上寒冷,尋思:“卻才老軍所說五里路外有那市井,何不去沽些酒來吃?”便去包里取些碎銀子,把花槍挑了酒葫蘆,將火炭蓋了,取氈笠子戴上,拿了鑰匙,出來把草廳門拽上。出到大門首,把兩扇草場門反拽上,鎖了。帶了鑰匙,信步投東。雪地里踏著碎瓊亂玉,迤邐背著北風而行。那雪正下得緊。 行不上半里多路,看見一所古廟。林沖頂禮道:“神明庇佑,改日來燒錢紙。”又行了一回,望見一簇人家。林沖住腳看時,見籬笆中挑著一個草帚兒在露天里。林沖徑到店里,主人道:“客人那里來?”林沖道:“你認得這個葫蘆么?”主人看了道:“這葫蘆是草料場老軍的。”林沖道:“如何便認的?”店主道:“既是草料場看守大哥,且請少坐。天氣寒冷,且酌三杯權當接風。”店家切一盤熟牛肉,燙一壺熱酒,請林沖吃。又自買了些牛肉,又吃了數杯。就又買了一葫蘆酒,包了那兩塊牛肉,留下碎銀子,把花槍挑了酒葫蘆,懷內揣了牛肉,叫聲相擾,便出籬笆門,依舊迎著朔風回來。看那雪,到晚越下的緊了。古時有個書生,做了一個詞,單題那貧苦的恨雪: 廣莫嚴風刮地,這雪兒下的正好。扯絮挦綿,裁幾片大如栲栳。見林間竹屋茅茨,爭些兒被他壓倒。富室豪家,卻言道壓瘴猶嫌少。向的是獸炭紅爐,穿的是綿衣絮襖。手捻梅花,唱道國家祥瑞,不念貧民些小。高臥有幽人,吟詠多詩草。
對中文提取文本特征,需要安裝并使用到jieba庫。使用該庫將文本處理成為空格連接詞語的格式,再使用CountVectorizer文本特征提取模型進行提取即可。
代碼示例如下:
import jieba
from sklearn.feature_extraction.text import CountVectorizer
# 將文本轉為以空格相連的字符串
def cut_word(sent):
return " ".join(list(jieba.cut(sent)))
# 將文本以行為單位,去除空格,并置于列表中。格式形如:["第一行","第二行",..."n"]
with open("./論文.txt", "r") as f:
data = [line.replace("\n", "") for line in f.readlines()]
lis = []
# 將每一行的詞匯以空格連接
for temp in data:
lis.append(cut_word(temp))
transfer = CountVectorizer()
trans_data = transfer.fit_transform(lis)
print(transfer.get_feature_names())
# 輸出sparse數組
print(trans_data)
# 轉為ndarray數組(如果需要)
print(trans_data.toarray())程序執行效果如下:
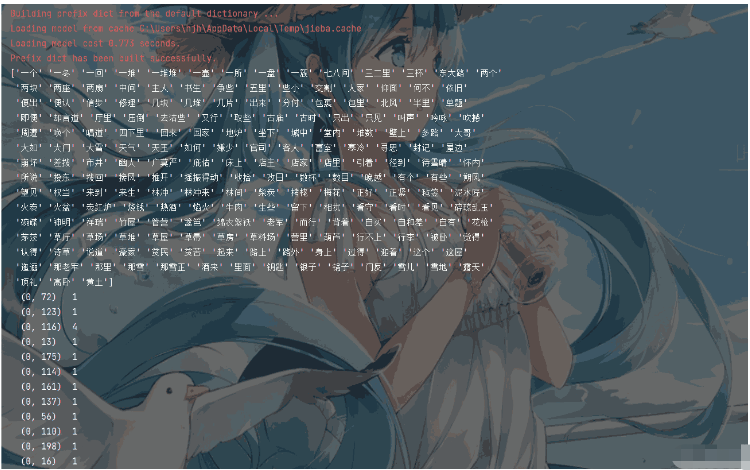
轉換得到的ndarray數組形式(如果需要)如圖所示:

TF-IDF文本提取器可以用來評估一字詞對于一個文件集或者一個語料庫中的其中一份文件的重要程度。
代碼展示如下:
from sklearn.feature_extraction.text import TfidfVectorizer
import jieba
def cut_word(sent):
return " ".join(list(jieba.cut(sent)))
with open("data.txt", "r") as f:
data = [line.replace("\n", "") for line in f.readlines()]
lis = []
for temp in data:
# print(cut_word(temp))
lis.append(cut_word(temp))
transfer = TfidfVectorizer()
print(transfer.get_feature_names())
print(trans_data)程序執行結果如下:
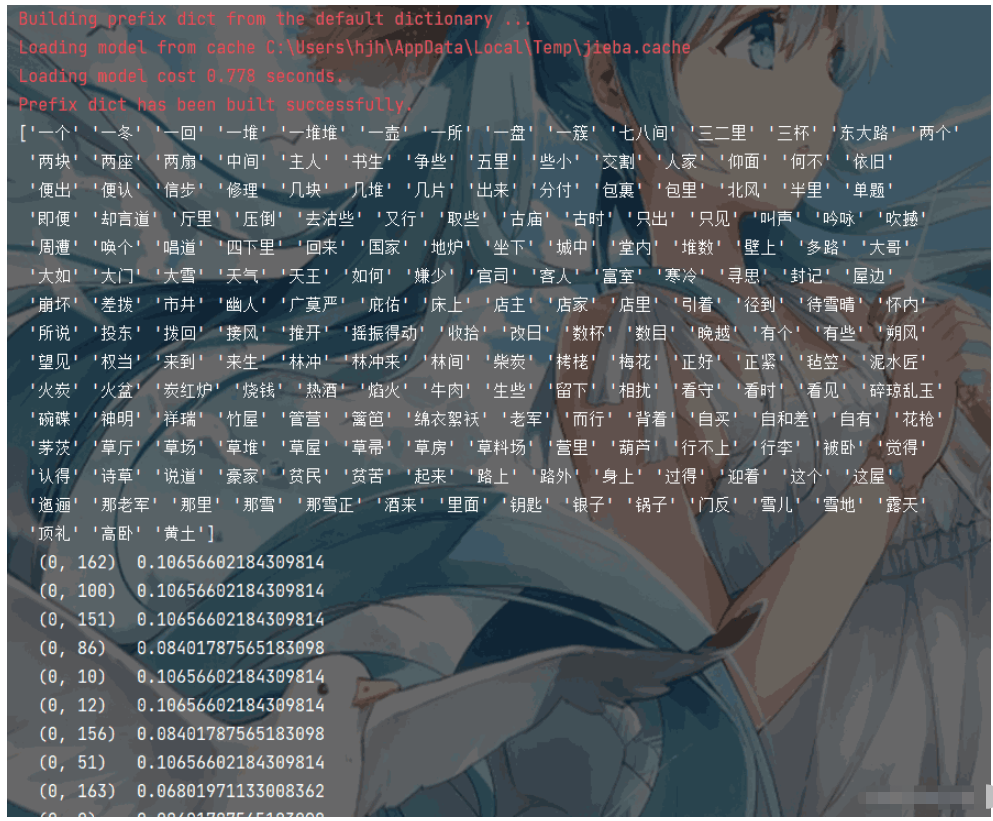
關于“Python怎么實現文本特征提取”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





