溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Linux行處理工具之grep正則表達式實例分析”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Linux行處理工具之grep正則表達式實例分析”吧!
在介紹正則表達式之前,我們先來嘗試一下,假如有如下文本。
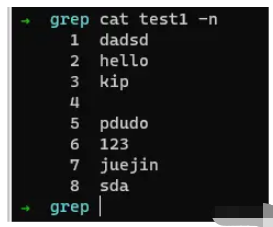
我們想獲取空行,應該如何來寫呢?
命令:
grep ^$ test1 -n
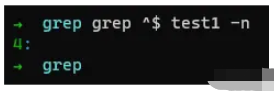
通過上述例子,我們使用正則表達式^$已經成功拿到了第四行數據,那么,這究竟如何解呢,我們細看博文。
grep表達式有三種不同的版本,分別為basic(BRE) 、extended(ERE) 以及 perl(PCRE) ,我們grep默認支持的是BRE,而ERE是egrep支持的,或者說是grep -E支持的, 而PCRE則是grep -P支持的,那么這三者究竟有啥區別呢?
| BRE | ERE | PCRE | |||
|---|---|---|---|---|---|
| 任意字符 | . | . | . | ||
| 前一個字符0次或者出現1次 | ? | ? | ? | ||
| 前一個字符出現0次或無數次 | * | * | * | ||
| 前一個字符出現一個或者更多 | + | + | + | ||
| 字符集 | [...] | [...] | [...] | ||
| 字符集取反 | [^...] | [^...] | [^...] | ||
| 匹配前面字符出現的n次 | {n} | {n} | {n} | ||
| 匹配前面字符出現的n次以上 | {n,} | {n,} | {n,} | ||
| 匹配前面字符出現的n次到m次 | {n,m} | {n,m} | {n,m} | ||
| 開頭 | |||||
| 結尾 | $ | $ | $ | ||
| 多表達式連接 | | | ||||
| 單詞 | \w | \w | \w 或者 [[:word:]] | ||
| 字母大寫/小寫 | [[:upper:]]/[[:lower:]] | [[:upper:]]/[[:lower:]] | [[:upper:]]/[[:lower:]] | ||
| 非單詞 | \W | ||||
| 空白字符 | \s 或者 [[:space:]] | \s 或者 [[:space:]] | |||
| 非空白字符 | [^[:space:]] | [^[:space:]] | \S | ||
| 數字 | \d 或者 [[:digit:]] | [[:digit:]] | [[:digit:]] | ||
| 非數字 | \D | [^[:digit:]] | [^[:digit:]] |
那么如何進行切換呢? 如上面所示,我們來看下。
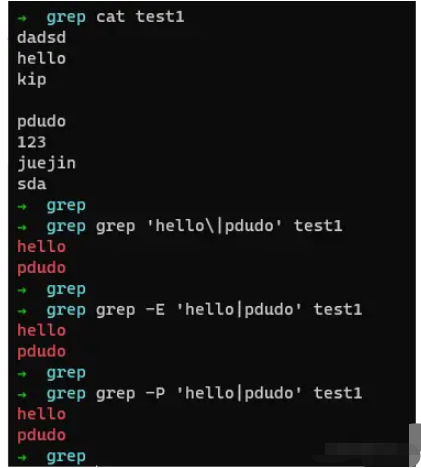
如上所述,若我們需要連接多個匹配項,在BRE(grep)中則是|,而在ERE(egrep)和PCRE(grep -P)中則是|,所以我們可以順利獲取出結果,更多匹配項如上所述
匹配電話號碼
若電話號碼為xxx-xxxx-xxxx類型的,如何進行匹配呢? 我們可以使用'[0-9]{3}-[0-9]{4}-[0-9]{4}'進行匹配。
例如:
命令:
echo "telphone: 180-1234-5678" | grep '[0-9]{3}-[0-9]{4}-[0-9]{4}' -o
同樣的,該方法還可以用來匹配其ip地址,正則: [0-9]{0,3}.[0-9]{0,3}.[0-9]{0,3}.[0-9]{0,3}

匹配空行
若我們想匹配空行,則可以使用^$進行匹配,即: 開頭就是結尾。
例如:
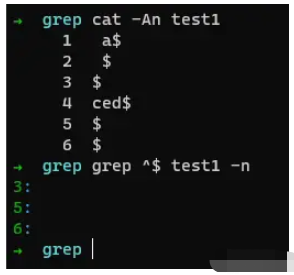
如上命令,我們順利取出了 第3、5、6行數據
匹配所有字母
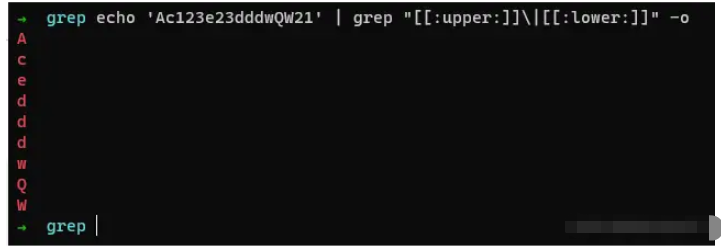
命令:
echo 'Ac123e23dddwQW21' | grep "[[:upper:]]|[[:lower:]]" -o
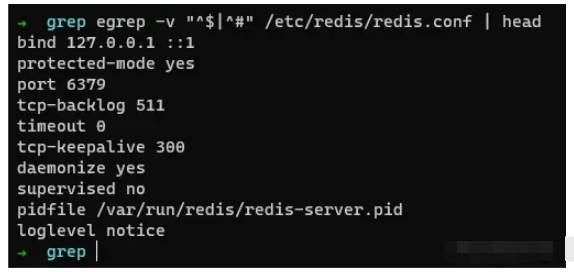
取出redis在使用的配置文件
我們知道redis服務器是以#來注釋的,我們可以利用grep或者egrep來過濾掉注釋和空格,例如:
fgrep最為簡單,它不會啟用正則表達式,而是按照字符來進行搜索,什么意思呢? 我們舉個小案例就清楚了,
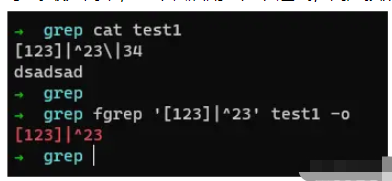
它不會進行任何正則匹配,所以可以直接使用搜索選就成,不用考慮轉移啥的。
感謝各位的閱讀,以上就是“Linux行處理工具之grep正則表達式實例分析”的內容了,經過本文的學習后,相信大家對Linux行處理工具之grep正則表達式實例分析這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





