溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“Flink怎么使用Savepoint”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“Flink怎么使用Savepoint”文章吧。
什么是 savepoint,為什么要使用 savepoint ?
保障 flink 作業在 配置迭代、flink 版本升級、藍綠部署中的數據一致性,提高容錯、降低恢復時間;
在此之前引入幾個概念:
Flink 通過狀態快照實現容錯處理
Flink 中的狀態: keyed state, operator state ..
Flink 中的狀態后端:A. 狀態數據如何存?B. 運行時存在哪里?C. 狀態快照保存在哪?

注1:自 1.13 版本之后,設置 Working State 和 設置 Snapshot State 拆離成了兩個接口,便于讀者更易于理解;
StateBackend
CheckpointStorage
注2:一般默認使用 FsStateBackend,運行時狀態放在堆中保障性能,快照備份時數據存于 Hdfs 保障容錯性;當業務有大狀態的 flink 作業存在時,可以通過配置化的方式將用戶作業的狀態后端設置為 RocksDBSateBackend。
Checkpoint – a snapshot taken automatically by Flink for the purpose of being able to recover from faults. Checkpoints can be incremental, and are optimized for being restored quickly.
Alignment checkpoint
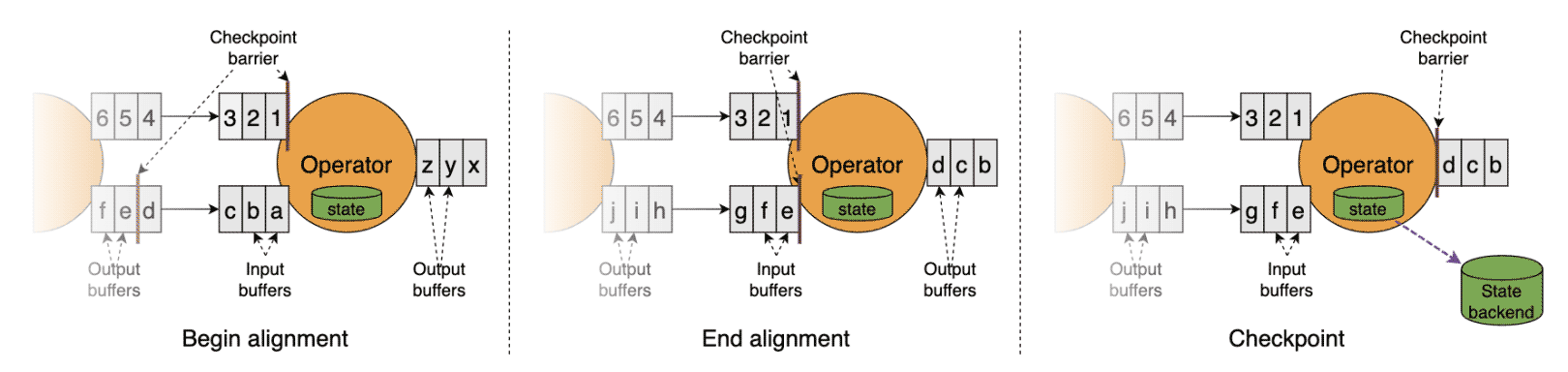
Unaligment checkpoint
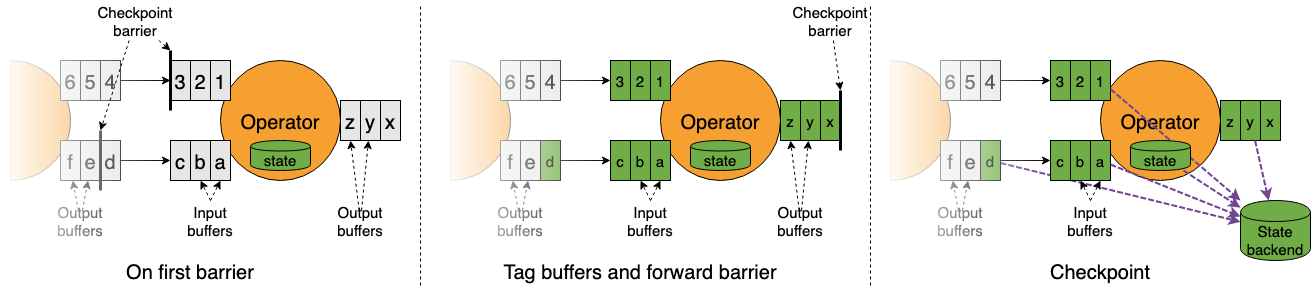
未對齊的 checkpoint 確保障礙物盡快到達接收器。
適用于至少有一條緩慢移動的數據路徑的應用程序,避免對齊時間過長。然而,
會增加了額外的輸入/輸出壓力,會造成 checkpoint size 的增加,當狀態后后端 IO 有瓶頸時,不合適;
注:一般默認使用 Alignment checkpoint;當出現被壓時,一般優先采用
1. 優化邏輯 2. 增加并發能力的方式進行處理;
Checkpoint 使 Flink 的狀態具有良好的容錯性,通過 checkpoint 機制,Flink 可以對作業的狀態和計算位置進行恢復。
Savepoint 是依據 Flink checkpointing 機制所創建的流作業執行狀態的一致鏡像;
Checkpoint 的主要目的是為意外失敗的作業提供恢復機制(如 tm/jm 進程掛了)。
Checkpoint 的生命周期由 Flink 管理,即 Flink 創建,管理和刪除 Checkpoint - 無需用戶交互。
Savepoint 由用戶創建,擁有和刪除。 他們的用例是計劃的,手動備份和恢復。
Savepoint 應用場景,升級 Flink 版本,調整用戶邏輯,改變并行度,以及進行紅藍部署等。 Savepoint 更多地關注可移植性和對前面提到的作業更改的支持。
除去這些概念上的差異,Checkpoint 和 Savepoint 的當前實現基本上使用相同的代碼并生成相同的格式(rocksDB 增量 checkpoint 除外,未來可能有更多類似的實現)
觸發 savepoint 保留到 hdfs, 在重新調度作業時,提供給用戶選擇即可。
關鍵點:執行 savepoint 需要指定 jobId,因此在設計數據平臺的元數據時,需要保留 jobId 數據。
使用 YARN 觸發 Savepoint # $ bin/flink savepoint :jobId [:targetDirectory] -yid :yarnAppId 這將觸發 ID 為 :jobId 和 YARN 應用程序 ID :yarnAppId 的作業的 Savepoint,并返回創建的 Savepoint 的路徑。 使用 Savepoint 取消作業 # $ bin/flink cancel -s [:targetDirectory] :jobId 這將自動觸發 ID 為 :jobid 的作業的 Savepoint,并取消該作業。此外,你可以指定一個目標文件系統目錄來存儲 Savepoint 。該目錄需要能被 JobManager(s) 和 TaskManager(s) 訪問。 從 Savepoint 恢復 # $ bin/flink run -s :savepointPath [:runArgs] 這將提交作業并指定要從中恢復的 Savepoint 。 你可以給出 Savepoint 目錄或 _metadata 文件的路徑。 跳過無法映射的狀態恢復 # 默認情況下,resume 操作將嘗試將 Savepoint 的所有狀態映射回你要還原的程序。 如果刪除了運算符,則可以通過 --allowNonRestoredState(short:-n)選項跳過無法映射到新程序的狀態: $ bin/flink run -s :savepointPath -n [:runArgs] 刪除 Savepoint # $ bin/flink savepoint -d :savepointPath 這將刪除存儲在 :savepointPath 中的 Savepoint。
當流處理應用程序發生錯誤的時候,結果可能會產生丟失或者重復。Flink 根據你為應用程序和集群的配置,可以產生以下結果:
Flink 不會從快照中進行恢復(at most once)
沒有任何丟失,但是你可能會得到重復冗余的結果(at least once)
沒有丟失或冗余重復(exactly once)
Flink 通過回退和重新發送 source 數據流從故障中恢復,當理想情況被描述為精確一次時,這并不意味著每個事件都將被精確一次處理。相反,這意味著 每一個事件都會影響 Flink 管理的狀態精確一次。
Barrier 只有在需要提供精確一次的語義保證時需要進行對齊(Barrier alignment)。如果不需要這種語義,可以通過配置 CheckpointingMode.AT_LEAST_ONCE 關閉 Barrier 對齊來提高性能。
為了實現端到端的精確一次,以便 sources 中的每個事件都僅精確一次對 sinks 生效,必須滿足以下條件:
sources 必須是可重放的,并且
sinks 必須是事務性的(或冪等的)
以上就是關于“Flink怎么使用Savepoint”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





