溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“PyTorch中的nn.Embedding怎么使用”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“PyTorch中的nn.Embedding怎么使用”文章吧。
太長不看版: NLP任務所依賴的語言數據稱為語料庫。
詳細介紹版: 語料庫(Corpus,復數是Corpora)是組織成數據集的真實文本或音頻的集合。 此處的真實是指由該語言的母語者制作的文本或音頻。 語料庫可以由從報紙、小說、食譜、廣播到電視節目、電影和推文的所有內容組成。 在自然語言處理中,語料庫包含可用于訓練 AI 的文本和語音數據。
為簡便起見,假設我們的語料庫只有三個英文句子并且均已經過處理(全部小寫+去掉標點符號):
corpus = ["he is an old worker", "english is a useful tool", "the cinema is far away"]
我們往往需要將其詞元化(tokenize)以成為一個序列,這里只需要簡單的 split 即可:
def tokenize(corpus): return [sentence.split() for sentence in corpus] tokens = tokenize(corpus) print(tokens) # [['he', 'is', 'an', 'old', 'worker'], ['english', 'is', 'a', 'useful', 'tool'], ['the', 'cinema', 'is', 'far', 'away']]
???? 這里我們是以單詞級別進行詞元化,還可以以字符級別進行詞元化。
詞表不重復地包含了語料庫中的所有詞元,其實現方式十分容易:
vocab = set(sum(tokens, []))
print(vocab)
# {'is', 'useful', 'an', 'old', 'far', 'the', 'away', 'a', 'he', 'tool', 'cinema', 'english', 'worker'}詞表在NLP任務中往往并不是最重要的,我們需要為詞表中的每一個單詞分配唯一的索引并構建單詞到索引的映射:word2idx。這里我們按照單詞出現的頻率來構建 word2idx。
from collections import Counter
word2idx = {
word: idx
for idx, (word, freq) in enumerate(
sorted(Counter(sum(tokens, [])).items(), key=lambda x: x[1], reverse=True))
}
print(word2idx)
# {'is': 0, 'he': 1, 'an': 2, 'old': 3, 'worker': 4, 'english': 5, 'a': 6, 'useful': 7, 'tool': 8, 'the': 9, 'cinema': 10, 'far': 11, 'away': 12}反過來,我們還可以構建 idx2word:
idx2word = {idx: word for word, idx in word2idx.items()}
print(idx2word)
# {0: 'is', 1: 'he', 2: 'an', 3: 'old', 4: 'worker', 5: 'english', 6: 'a', 7: 'useful', 8: 'tool', 9: 'the', 10: 'cinema', 11: 'far', 12: 'away'}對于 1.2 節中的 tokens,也可以轉化為索引的表示:
encoded_tokens = [[word2idx[token] for token in line] for line in tokens] print(encoded_tokens) # [[1, 0, 2, 3, 4], [5, 0, 6, 7, 8], [9, 10, 0, 11, 12]]
這種表示方式將在后續講解 nn.Embedding 時提到。
RNN無法直接處理單詞,因此需要通過某種方法把單詞變成數字形式的向量才能作為RNN的輸入。這種把單詞映射到向量空間中的一個向量的做法稱為詞嵌入(word embedding),對應的向量稱為詞向量(word vector)。
我們首先講解 nn.Embedding 中的基礎參數,了解它的基本用法后,再講解它的全部參數。
基礎參數如下:
nn.Embedding(num_embeddings, embedding_dim)
其中 num_embeddings 是詞表的大小,即 len(vocab);embedding_dim 是詞向量的維度。
我們使用第一章節的例子,此時詞表大小為 12 12 12,不妨設嵌入后詞向量的維度是 3 3 3(即將單詞嵌入到三維向量空間中),則 embedding 層應該這樣創建:
torch.manual_seed(0) # 為了復現性 emb = nn.Embedding(12, 3)
embedding 層中只有一個參數 weight,在創建時它會從標準正態分布中進行初始化:
print(emb.weight) # Parameter containing: # tensor([[-1.1258, -1.1524, -0.2506], # [-0.4339, 0.8487, 0.6920], # [-0.3160, -2.1152, 0.3223], # [-1.2633, 0.3500, 0.3081], # [ 0.1198, 1.2377, 1.1168], # [-0.2473, -1.3527, -1.6959], # [ 0.5667, 0.7935, 0.4397], # [ 0.1124, 0.6408, 0.4412], # [-0.2159, -0.7425, 0.5627], # [ 0.2596, 0.5229, 2.3022], # [-1.4689, -1.5867, 1.2032], # [ 0.0845, -1.2001, -0.0048]], requires_grad=True)
這里我們可以把 weight 當作 embedding 層的一個權重。
接下來再來看一下 nn.Embedding 的輸入。直觀來看,給定一個已經詞元化的句子,將其中的單詞輸入到 embedding 層應該得到相應的詞向量。事實上,nn.Embedding 接受的輸入并不是詞元化后的句子,而是它的索引形式,即第一章節中提到的 encoded_tokens。
nn.Embedding 可以接受任何形狀的張量作為輸入,但因為傳入的是索引,所以張量中的每個數字都不應超過 len(vocab) - 1,否則就會報錯。接下來,nn.Embedding 的作用就像一個查找表(Lookup Table)一樣,通過這些索引在 weight 中查找并返回相應的詞向量。
print(emb.weight) # tensor([[-1.1258, -1.1524, -0.2506], # [-0.4339, 0.8487, 0.6920], # [-0.3160, -2.1152, 0.3223], # [-1.2633, 0.3500, 0.3081], # [ 0.1198, 1.2377, 1.1168], # [-0.2473, -1.3527, -1.6959], # [ 0.5667, 0.7935, 0.4397], # [ 0.1124, 0.6408, 0.4412], # [-0.2159, -0.7425, 0.5627], # [ 0.2596, 0.5229, 2.3022], # [-1.4689, -1.5867, 1.2032], # [ 0.0845, -1.2001, -0.0048]], requires_grad=True) sentence = torch.tensor(encoded_tokens[0]) # 一共有三個句子,這里只使用第一個句子 print(sentence) # tensor([1, 0, 2, 3, 4]) print(emb(sentence)) # tensor([[-0.4339, 0.8487, 0.6920], # [-1.1258, -1.1524, -0.2506], # [-0.3160, -2.1152, 0.3223], # [-1.2633, 0.3500, 0.3081], # [ 0.1198, 1.2377, 1.1168]], grad_fn=<EmbeddingBackward0>) print(emb.weight[sentence] == emb(sentence)) # tensor([[True, True, True], # [True, True, True], # [True, True, True], # [True, True, True], # [True, True, True]])
細心的讀者可能已經看出 nn.Embedding 和 nn.Linear 似乎很像,那它們到底有什么區別呢?
回顧 nn.Linear,若不開啟 bias,設輸入向量為 x,nn.Linear.weight 對應的矩陣為 A(形狀為 hidden_size × input_size),則計算方式為:
y=xAT
其中 x , y 均為行向量。
假如 x 是one-hot向量,第 i 個位置是 1 1 1,那么 y 就是 A T 的第 i i 行。
現給定一個單詞 w ,假設它在 word2idx 中的索引就是 i ,在 nn.Embedding 中,我們根據這個索引 i 去查找 emb.weight 的第 i 行。而在 nn.Linear 中,我們則是將這個索引 i 編碼成一個one-hot向量,再去乘上對應的權重矩陣得到矩陣的第 i 行。
請看下例:
torch.manual_seed(0) vocab_size = 4 # 詞表大小為4 embedding_dim = 3 # 詞向量維度為3 weight = torch.randn(4, 3) # 隨機初始化權重矩陣 # 保持線性層和嵌入層具有相同的權重 linear_layer = nn.Linear(4, 3, bias=False) linear_layer.weight.data = weight.T # 注意轉置 emb_layer = nn.Embedding(4, 3) emb_layer.weight.data = weight idx = torch.tensor(2) # 假設某個單詞在word2idx中的索引為2 word = torch.tensor([0, 0, 1, 0]).to(torch.float) # 上述單詞的one-hot表示 print(emb_layer(idx)) # tensor([ 0.4033, 0.8380, -0.7193], grad_fn=<EmbeddingBackward0>) print(linear_layer(word)) # tensor([ 0.4033, 0.8380, -0.7193], grad_fn=<SqueezeBackward3>)
從中我們可以總結出:
nn.Linear 接受向量作為輸入,而 nn.Embedding 則是接受離散的索引作為輸入;
nn.Embedding 實際上就是輸入為one-hot向量,且不帶bias的 nn.Linear。
此外,nn.Linear 在運算過程中做了矩陣乘法,而 nn.Embedding 是直接根據索引查表,因此在該情景下 nn.Embedding 的效率顯然更高。
???? 進一步閱讀: [Stack Overflow] What is the difference between an Embedding Layer with a bias immediately afterwards and a Linear Layer in PyTorch?
在查閱了PyTorch官方論壇和Stack Overflow的一些帖子后,發現有不少人對 nn.Embedding 中的權重 weight 是怎么更新的感到非常困惑。
???? nn.Embedding 的權重實際上就是詞嵌入本身
事實上,nn.Embedding.weight 在更新的過程中既沒有采用 Skip-gram 也沒有采用 CBOW。回顧最簡單的多層感知機,其中的 nn.Linear.weight 會隨著反向傳播自動更新。當我們把 nn.Embedding 視為一個特殊的 nn.Linear 后,其更新機制就不難理解了,無非就是按照梯度進行更新罷了。
訓練結束后,得到的詞嵌入是最適合當前任務的詞嵌入,而非像word2vec,GloVe這種更為通用的詞嵌入。
當然我們也可以在訓練開始之前使用預訓練的詞嵌入,例如上述提到的word2vec,但此時應該考慮針對當前任務重新訓練或進行微調。
假如我們已經使用了預訓練的詞嵌入并且不想讓它在訓練過程中自我更新,那么可以嘗試凍結梯度,即:
emb.weight.requires_grad = False
???? 進一步閱讀:
[PyTorch Forums] How nn.Embedding trained?
[PyTorch Forums] How does nn.Embedding work?
[Stack Overflow] Embedding in pytorch
[Stack Overflow] What “exactly” happens inside embedding layer in pytorch?
在這一章節中,我們會講解 nn.Embedding 的所有參數并介紹如何使用預訓練的詞嵌入。
官方文檔:
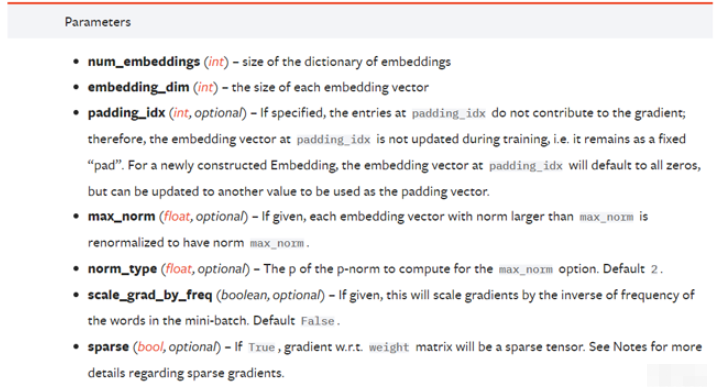
padding_idx
我們知道,nn.Embedding 雖然可以接受任意形狀的張量作為輸入,但絕大多數情況下,其輸入的形狀為 batch_size × sequence_length,這要求同一個 batch 中的所有序列的長度相同。
回顧1.2節中的例子,語料庫中的三個句子的長度相同(擁有相同的單詞個數),但事實上這是博主特意選取的三個句子。現實任務中,很難保證同一個 batch 中的所有句子長度都相同,因此我們需要對那些長度較短的句子進行填充。因為輸入到 nn.Embedding 中的都是索引,所以我們也需要用索引進行填充,那使用哪個索引最好呢?
假設語料庫為:
corpus = ["he is an old worker", "time tries truth", "better late than never"]
print(word2idx)
# {'he': 0, 'is': 1, 'an': 2, 'old': 3, 'worker': 4, 'time': 5, 'tries': 6, 'truth': 7, 'better': 8, 'late': 9, 'than': 10, 'never': 11}
print(encoded_tokens)
# [[0, 1, 2, 3, 4], [5, 6, 7], [8, 9, 10, 11]]我們可以在 word2idx 中新增一個詞元 <pad>(代表填充詞元),并為其分配新的索引:
word2idx['<pad>'] = 12
對 encoded_tokens 進行填充:
max_length = max([len(seq) for seq in encoded_tokens]) for i in range(len(encoded_tokens)): encoded_tokens[i] += [word2idx['<pad>']] * (max_length - len(encoded_tokens[i])) print(encoded_tokens) # [[0, 1, 2, 3, 4], [5, 6, 7, 12, 12], [8, 9, 10, 11, 12]]
創建 embedding 層并指定 padding_idx:
emb = nn.Embedding(len(word2idx), 3, padding_idx=12) # 假設詞向量維度是3 print(emb.weight) # tensor([[ 1.5017, -1.1737, 0.1742], # [-0.9511, -0.4172, 1.5996], # [ 0.6306, 1.4186, 1.3872], # [-0.1833, 1.4485, -0.3515], # [ 0.2474, -0.8514, -0.2448], # [ 0.4386, 1.3905, 0.0328], # [-0.1215, 0.5504, 0.1499], # [ 0.5954, -1.0845, 1.9494], # [ 0.0668, 1.1366, -0.3414], # [-0.0260, -0.1091, 0.4937], # [ 0.4947, 1.1701, -0.5660], # [ 1.1717, -0.3970, -1.4958], # [ 0.0000, 0.0000, 0.0000]], requires_grad=True)
可以看出填充詞元對應的詞向量是零向量,并且在訓練過程中填充詞元對應的詞向量不會進行更新(始終是零向量)。
padding_idx 默認為 None,即不進行填充。
max_norm
如果詞向量的范數超過了 max_norm,則將其按范數歸一化至 max_norm:
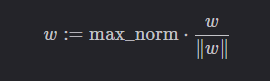
max_norm 默認為 None,即不進行歸一化。
norm_type
當指定了 max_norm 時,norm_type 決定采用何種范數去計算。默認是2-范數。
scale_grad_by_freq
若將該參數設置為 True,則對詞向量 w w w 進行更新時,會根據它在一個 batch 中出現的頻率對相應的梯度進行縮放:
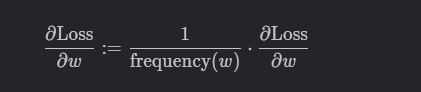
默認為 False。
sparse
若設置為 True,則與 Embedding.weight 相關的梯度將變為稀疏張量,此時優化器只能選擇:SGD、SparseAdam 和 Adagrad。默認為 False。
有些情況下我們需要使用預訓練的詞嵌入,這時候可以使用 from_pretrained 方法,如下:
torch.manual_seed(0) pretrained_embeddings = torch.randn(4, 3) print(pretrained_embeddings) # tensor([[ 1.5410, -0.2934, -2.1788], # [ 0.5684, -1.0845, -1.3986], # [ 0.4033, 0.8380, -0.7193], # [-0.4033, -0.5966, 0.1820]]) emb = nn.Embedding(4, 3).from_pretrained(pretrained_embeddings) print(emb.weight) # tensor([[ 1.5410, -0.2934, -2.1788], # [ 0.5684, -1.0845, -1.3986], # [ 0.4033, 0.8380, -0.7193], # [-0.4033, -0.5966, 0.1820]])
如果要避免預訓練的詞嵌入在后續的訓練過程中更新,可將 freeze 參數設置為 True:
emb = nn.Embedding(4, 3).from_pretrained(pretrained_embeddings, freeze=True)
以上就是關于“PyTorch中的nn.Embedding怎么使用”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





